溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

近年來隨著大數據的興起,分布式計算引擎層出不窮。 Hadoop 是 Apache 開源組織的一個分布式計算開源框架,在很多大型網站上都已經得到了應用。Hadoop 的設計核心思想來源于 Google MapReduce 論文,靈感來自于函數式語言中的 map 和 reduce 方法。在函數式語言中,map 表示針對列表中每個元素應用一個方法,reduce 表示針對列表中的元素做迭代計算。通過 MapReduce 算法,可以將數據根據某些特征進行分類規約,處理并得到最終的結果。
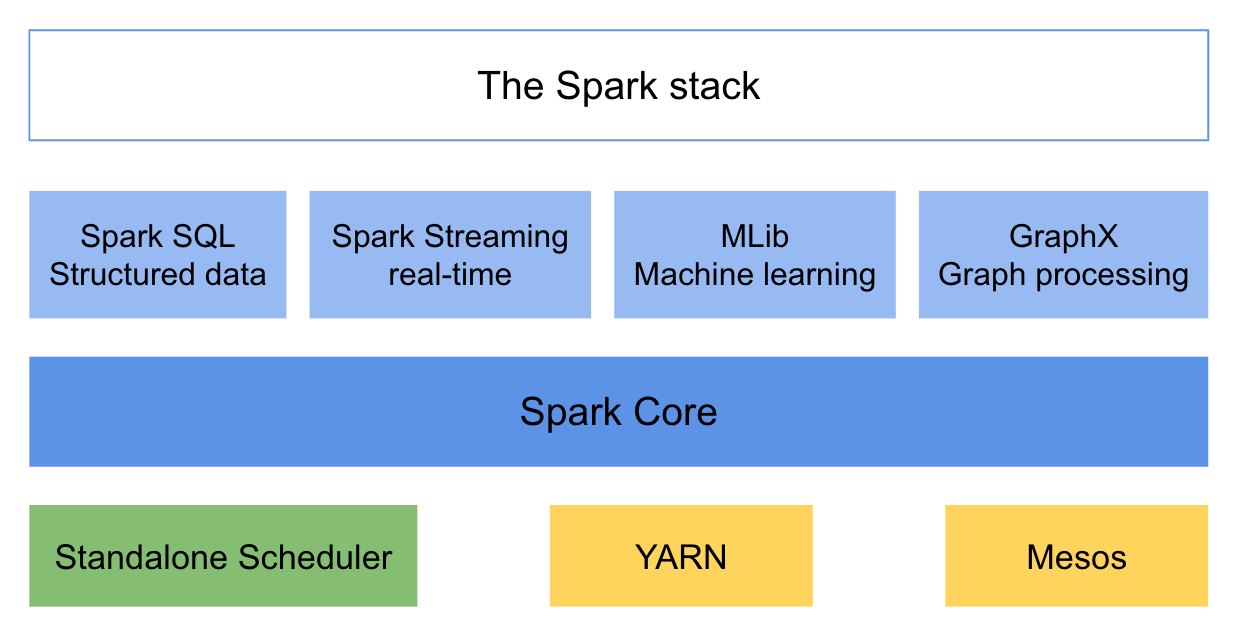
Apache Spark 是一個圍繞速度、易用性構建的通用內存并行計算框架。在 2009 年由加州大學伯克利分校 AMP 實驗室開發,并于 2010 年成為 Apache 基金會的開源項目。Spark 借鑒了 Hadoop 的設計思想,繼承了其分布式并行計算的優點,提供了豐富的算子。
Spark 提供了一個全面、統一的框架用于管理各種有著不同類型數據源的大數據處理需求,支持批量數據處理與流式數據處理。Spark 支持內存計算,性能相比起 Hadoop 有著巨大提升。Spark 支持 Java,Scala 和 Python 三種語言進行編程,支持以操作本地集合的方式操作分布式數據集,并且支持交互查詢。除了經典的 MapReduce 操作之外,Spark 還支持 SQL 查詢、流式處理、機器學習和圖計算。
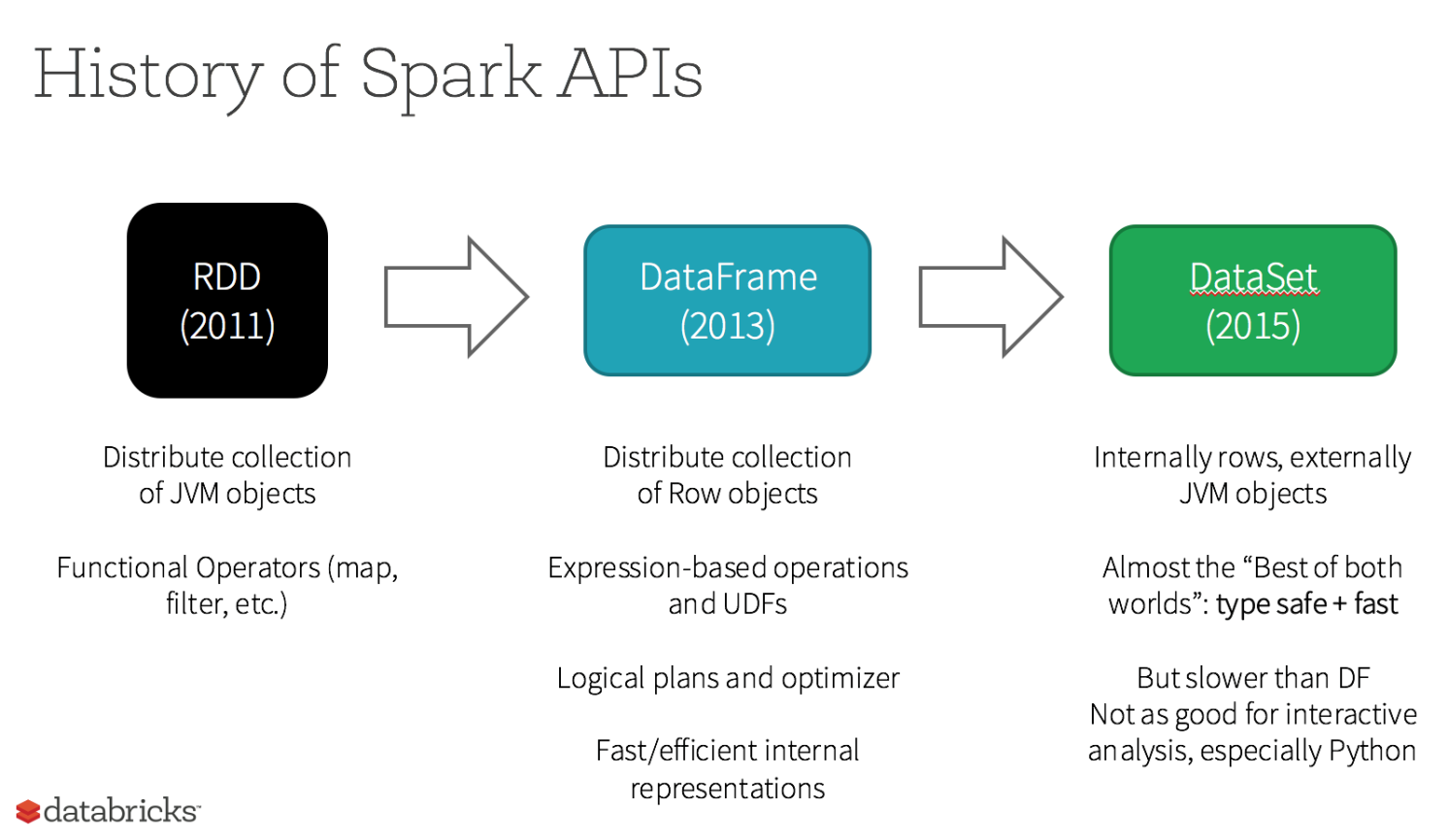
彈性分布式數據集(RDD,Resilient Distributed Dataset)是 Spark 最基本的抽象,代表不可變的分區數據集。RDD 具有可容錯和位置感知調度的特點。操作 RDD 就如同操作本地數據集合,而不必關心任務調度與容錯等問題。RDD 允許用戶在執行多個查詢時,顯示地將工作集合緩存在內存中,后續查詢能夠重用該數據集。RDD 通過一系列的轉換就就形成了 DAG,根據 RDD 之間的依賴關系的不同將 DAG 劃分成不同的 Stage。
與 RDD 相似,DataFrame 也是一個不可變分布式數據集合。區別于 RDD,DataFrame 中的數據被組織到有名字的列中,就如同關系型數據庫中的表。設計 DataFrame 的目的就是要讓對大型數據集的處理變得更簡單,允許開發者為分布式數據集指定一個模式,便于進行更高層次的抽象。
DataSet 是一個支持強類型的特定領域對象,這種對象可以函數式或者關系操作并行地轉換。DataSet 就是一些有明確類型定義的 JVM 對象的集合,可以通過 Scala 中定義的 Case Class 或者 Java 中的 Class 來指定。DataFrame 是 Row 類型的 Dataset,即 Dataset[Row]。DataSet 的 API 是強類型的;而且可以利用這些模式進行優化。
DataFrame 與 DataSet 只在執行行動操作時觸發計算。本質上,數據集表示一個邏輯計劃,該計劃描述了產生數據所需的計算。當執行行動操作時,Spark 的查詢優化程序優化邏輯計劃,并生成一個高效的并行和分布式物理計劃。
Spark Writer 是 Nebula Graph 基于 Spark 的分布式數據導入工具,基于 DataFrame 實現,能夠將多種數據源中的數據轉化為圖的點和邊批量導入到圖數據庫中。
目前支持的數據源有:Hive 和HDFS。
Spark Writer 支持同時導入多個標簽與邊類型,不同標簽與邊類型可以配置不同的數據源。
Spark Writer 通過配置文件,從數據中生成一條插入語句,發送給查詢服務,執行插入操作。Spark Writer 中插入操作使用異步執行,通過 Spark 中累加器統計成功與失敗數量。
git clone https://github.com/vesoft-inc/nebula.git
cd nebula/src/tools/spark-sstfile-generator
mvn compile package
標簽數據文件由一行一行的數據組成,文件中每一行表示一個點和它的屬性。一般來說,第一列為點的 ID ——此列的名稱將在后文的映射文件中指定,其他列為點的屬性。例如Play標簽數據文件格式:
{"id":100,"name":"Tim Duncan","age":42}
{"id":101,"name":"Tony Parker","age":36}
{"id":102,"name":"LaMarcus Aldridge","age":33}
邊類型數據文件由一行一行的數據組成,文件中每一行表示一條邊和它的屬性。一般來說,第一列為起點 ID,第二列為終點 ID,起點 ID 列及終點 ID 列會在映射文件中指定。其他列為邊屬性。下面以 JSON 格式為例進行說明。
以邊類型 follow 數據為例:
{"source":100,"target":101,"likeness":95}
{"source":101,"target":100,"likeness":95}
{"source":101,"target":102,"likeness":90}
{"source":100,"target":101,"likeness":95,"ranking":2}
{"source":101,"target":100,"likeness":95,"ranking":1}
{"source":101,"target":102,"likeness":90,"ranking":3}
Spark Writer 使用 HOCON 配置文件格式。HOCON(Human-Optimized Config Object Notation)是一個易于使用的配置文件格式,具有面向對象風格。配置文件由 Spark 配置段,Nebula 配置段,以及標簽配置段和邊配置段四部分組成。
Spark 信息配置了 Spark 運行的相關參數,Nebula 相關信息配置了連接 Nebula 的用戶名和密碼等信息。 tags 映射和 edges 映射分別對應多個 tag/edge 的輸入源映射,描述每個 tag/edge 的數據源等基本信息,不同 tag/edge 可以來自不同數據源。
Nebula 配置段主要用于描述 nebula 查詢服務地址、用戶名和密碼、圖空間信息等信息。
nebula: {
# 查詢引擎 IP 列表
addresses: ["127.0.0.1:3699"]
# 連接 Nebula Graph 服務的用戶名和密碼
user: user
pswd: password
# Nebula Graph 圖空間名稱
space: test
# thrift 超時時長及重試次數,默認值分別為 3000 和 3
connection {
timeout: 3000
retry: 3
}
# nGQL 查詢重試次數,默認值為 3
execution {
retry: 3
}
}
標簽配置段用于描述導入標簽信息,數組中每個元素為一個標簽信息。標簽導入主要分為兩種:基于文件導入與基于 Hive 導入。
# 處理標簽
tags: [
# 從 HDFS 文件加載數據, 此處數據類型為 Parquet tag 名稱為 ${TAG_NAME}
# HDFS Parquet 文件的中的 field_0、field_1將寫入 ${TAG_NAME}
# 節點列為 ${KEY_FIELD}
{
name: ${TAG_NAME}
type: parquet
path: ${HDFS_PATH}
fields: {
field_0: nebula_field_0,
field_1: nebula_field_1
}
vertex: ${KEY_FIELD}
batch : 16
}
# 與上述類似
# 從 Hive 加載將執行命令 $ {EXEC} 作為數據集
{
name: ${TAG_NAME}
type: hive
exec: ${EXEC}
fields: {
hive_field_0: nebula_field_0,
hive_field_1: nebula_field_1
}
vertex: ${KEY_FIELD}
}
]
說明:
邊類型配置段用于描述導入標簽信息,數組中每個元素為一個邊類型信息。邊類型導入主要分為兩種:基于文件導入與基于Hive導入。
基于Hive導入配置需指定執行的查詢語言
# 處理邊
edges: [
# 從 HDFS 加載數據,數據類型為 JSON
# 邊名稱為 ${EDGE_NAME}
# HDFS JSON 文件中的 field_0、field_1 將被寫入${EDGE_NAME}
# 起始字段為 source_field,終止字段為 target_field ,邊權重字段為 ranking_field。
{
name: ${EDGE_NAME}
type: json
path: ${HDFS_PATH}
fields: {
field_0: nebula_field_0,
field_1: nebula_field_1
}
source: source_field
target: target_field
ranking: ranking_field
}
# 從 Hive 加載將執行命令 ${EXEC} 作為數據集
# 邊權重為可選
{
name: ${EDGE_NAME}
type: hive
exec: ${EXEC}
fields: {
hive_field_0: nebula_field_0,
hive_field_1: nebula_field_1
}
source: source_id_field
target: target_id_field
}
]
說明:
name 字段用于表示邊類型名稱
bin/spark-submit \
--class com.vesoft.nebula.tools.generator.v2.SparkClientGenerator \
--master ${MASTER-URL} \
${SPARK_WRITER_JAR_PACKAGE} -c conf/test.conf -h -d
說明:
作者有話說:Hi ,大家好,我是 darion,Nebula Graph 的軟件工程師,對分布式系統方面有些小心得,希望上述文章可以給大家帶來些許啟發。限于水平,如有不當之處還請斧正,在此感謝^^
喜歡這篇文章?來來來,給我們的 GitHub 點個 star 表鼓勵啦~~ ?????♂??????♀? [手動跪謝]
交流圖數據庫技術?交個朋友,Nebula Graph 官方小助手微信: NebulaGraphbot 拉你進交流群~~
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





