溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

論文鏈接:https://static.aminer .cn/misc/pdf/minrror.pdf
常規的神經機器翻譯(NMT)需要大量平行語料,這對于很多語種來說真是太難了。所幸的是,原始的非平行語料極易獲得。但即便如此,現有基于非平行語料的方法仍舊未將非平行語料在訓練和解碼中發揮得淋漓盡致。
為此,本文提出一種鏡像生成式機器翻譯模型:MGNMT(mirror-generative NMT)。
MGNMT是一個統一的框架,該框架同時集成了source-target和target-source的翻譯模型及其各自語種的語言模型。MGNMT中的翻譯模型和語言模型共享隱語義空間,所以能夠從非平行語料中更有效地學習兩個方向上的翻譯。此外,翻譯模型和語言模型還能夠聯合協作解碼,提升翻譯質量。實驗表明本文方法確實有效,MGNMT在各種場景和語言(包括resource rich和 low-resource語言)中始終優于現有方法。
當下神經機器翻譯大行其道,但嚴重依賴于大量的平行語料。然而,在大多數機器翻譯場景中,獲取大量平行語料并非易事。此外,由于領域之間平行語料差異太大,特定領域內有限的并行語料(例如,醫療領域),NMT通常很難將其應用于其他領域。因此,當平行語料不足時,充分利用非平行雙語數據(通常獲取成本很低)對于獲得令人滿意的翻譯性能就至關重要了。
當下的NMT系統在訓練和解碼階段上都尚未將非平行語料發揮極致。對于訓練階段,一般是用回譯法(back-translation )。回譯法分別更新兩個方向的機器翻譯模型,這顯得不夠高效。給定source語種數據x和target語種數據y,回譯法先利用tgt2src翻譯模型將y翻譯到x?。再用上述生成的偽翻譯對(x?,y) 更新src2tgt翻譯模型。同理可以用數據x更新反方向的翻譯模型。需要注意的是,這里兩個方向上的翻譯模型相互獨立,各自獨立更新。也就是說,一方模型每次的更新都于另一方無直接益處。對此,有學者提出聯合回譯法和對偶學習(dual learning),在迭代訓練中使二者隱含地相互受益。但是,這些方法中的翻譯模型仍然各自獨立。理想狀態下,當兩個方向的翻譯模型相關,則非平行語料所帶來的增益能夠進一步提高。此時,一方每一步的更新都能夠提升另一方的性能,反之亦然。這將更大地發揮非平行語料的效用。
對于解碼,有學者提出在翻譯模型x->y中直接 插入獨自在target語種上訓練的外部語言模型。這種引入target語種知識的方法確實能夠取得更好的翻譯結果,特別是對于特定領域。但是,在解碼的時候直接引入獨立語言模型似乎不是最好的。原因如下:
(1)采用的語言模型來自于外部,獨立于翻譯模型的學習。這種簡單的 插入方式可能使得兩個模型無法良好協作,甚至帶來沖突;
(2)語言模型僅在解碼中使用,而訓練過程沒有。這導致訓練和解碼不一致,可能會影響性能。
本文提出鏡像生成式NMT(MGNMT)嘗試解決上述問題,進而更高效地利用非平行語料。MGNMT在一個統一的框架中聯合翻譯模型(兩個方向)和語言模型(兩個語種)。受生成式NMT(GNMT)的啟發,MGNMT中引入一個在x和y之間共享的隱語義變量z。本文利用對稱性或者說鏡像性質來分解條件聯合概率p(x, y | z):
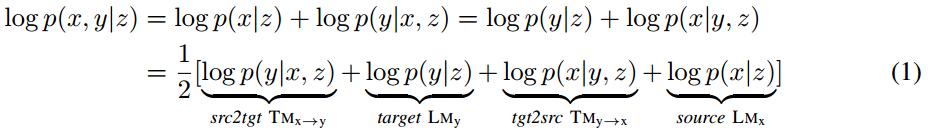
MGNMT的概率圖模型如Figure 1所示:
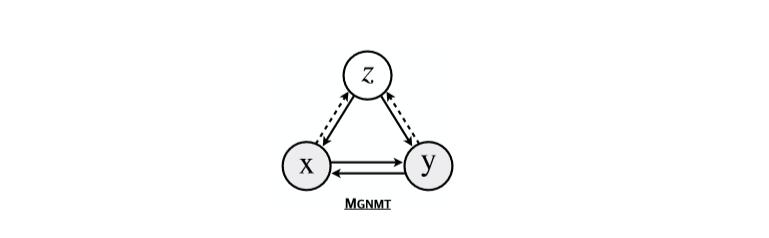
Figure 1:MGNMT的概率圖模型
通過共享的隱語義變量將兩個語種的雙向翻譯模型和語言模型分別對齊,如Figure 2所示:
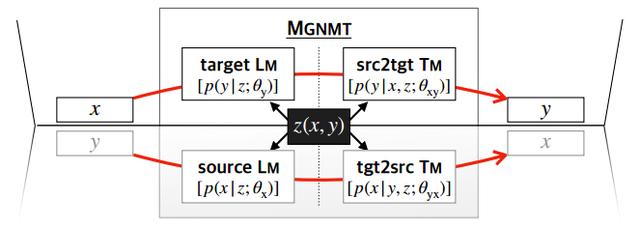
Figure 2:MGNMT的鏡像性質
引入隱變量后,將各個模型關聯起來,且在給定z下條件獨立。如此的MGNMT有如下2個優勢:
(1)訓練時,由于隱變量的作用,兩個方向的翻譯模型不再各自獨立,而是相互關聯。因此一個方向上的更新直接有益于另一個方向的翻譯模型。這提升了非平行語料的利用效率;
(2)解碼時,MGNMT能夠天然地利用其內部target端的語言模型。這個語言模型是與翻譯模型聯合學習的,聯合語言模型和翻譯模型有助于獲得更好的生成結果。
實驗表明MGNMT在平行語料上取得具有競爭力的結果,甚至在一些場景和語種對上(包括resource-rich語種、 resource-poor語種和跨領域翻譯)優于數個健壯的基準模型。此外還發現,翻譯模型和語言模型的聯合學習確實能夠提升MGNMT的翻譯質量。本文還證明MGNMT是一種自由體系結構,可以應用于任何神經序列模型如 Transformer和RNN。
MGNMT的整體框架如Figure 3所示:
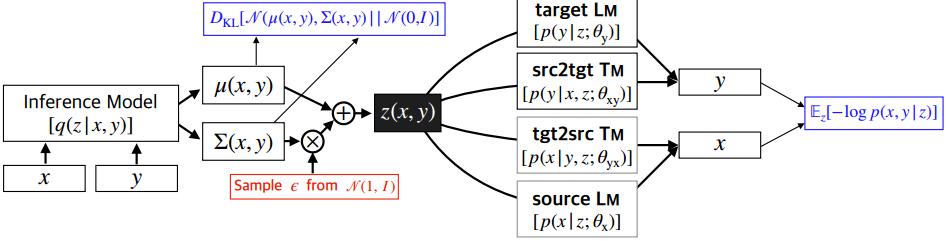
Figure 3:MGNMT的框架示意圖
其中(x,y)表示source-target語言對,θ表示模型參數,D_xy $表示平行語料,D_x和D_y分別表示各自的非平行單語語料。
MGNMT對雙語句對進行聯合建模,具體是利用聯合概率的鏡像性質:

其中隱變量z(本文選用標準高斯分布)表示x和y之間的語義共享。隱變量橋接了兩個方向的翻譯模型和語言模型。下面分別介紹平行語料和非平行語料的訓練及其解碼。
給定平行語料對(x,y),使用隨機梯度變分貝葉斯法(stochastic gradient variational Bayes,SGVB)得到log p(x,y)的近似最大似然估計。近似后驗可以參數化為:
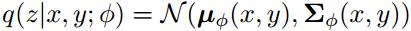
從方程(1)中可以得出聯合概率對數似然的證據下界(Evidence Lower BOund,ELBO):
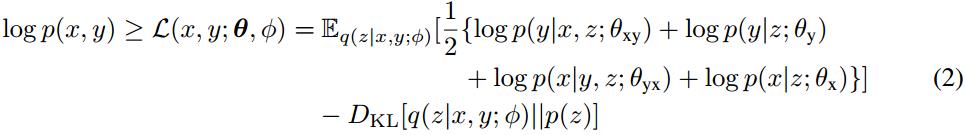
方程(2)中第一項表示句子對log似然的期望,該期望用蒙特卡洛采樣獲得。第二項是隱變量的近似后驗和先驗分布之間的KL散度。通過重新參數化的技巧,使用基于梯度的算法聯合訓練所有部分。
本文在MGNMT中設計一種迭代訓練方法以利用非平行語料。在該訓練過程中兩個方向的翻譯都能夠受益于各自的單語種數據集,且能夠相互促進。非平行語料上的訓練方法如 Algorithm 1所示:

給定兩個非平行句子:source語種中的句子x^s和target語種中的句子y^t。目標是使它們的邊際分布似然的下界相互最大化:
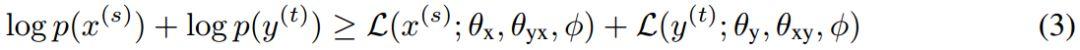
其中小于等于號右邊的兩項分別表示source和target的邊際對數似然的下界。
以上述第二項為例。用p(x|y^t)在source語種中采樣出的x作為y^t的翻譯結果(即回譯)。如此可以獲得偽平行句子對(x, y^t)。在方程(4)中直接給出該項的表達式:
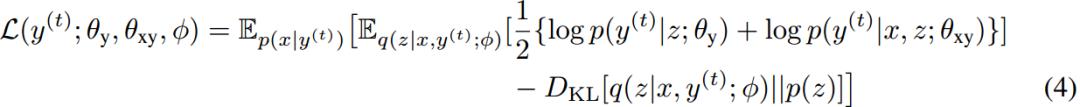
同理可以得到另一項的表達式:
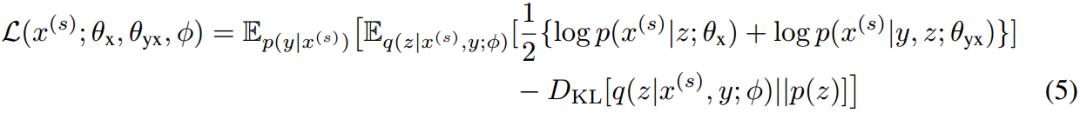
具體的證明過程,感興趣的童鞋可以看原始論文的附錄。
根據上述兩個公式可以得到2個方向的偽平行語料,再將二者聯合起來訓練MGNMT。方程(3)可以用基于梯度的方法進行更新,計算如方程(6)所示:
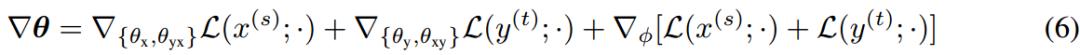
上述利用非平行語料的整個訓練過程在某種程度上與聯合回譯相似。但是聯合回譯每次迭代只利用非平行語料的一個方向來更新一個方向的翻譯模型。由于隱變量來自于共享近似后驗q(z|x, y;Φ),所以可充當促進MGNMT中兩個方向單語種性能的橋梁。
MGNMT在解碼中同時對翻譯模型和語言模型建模,所以在解碼時能夠獲得更流暢更高質量的翻譯結果。給定句子x(或者target句子y),通過y=argmax_{y} p(y|x)=argmax_{y} p(x, y)找到相應的翻譯結果。具體的解碼流程如 Algorithm 2所示:

以srg2tgt翻譯模型為例。對給定的source句子x做如下操作:
(1)從標準高斯先驗分布中采樣一個初始化的隱變量z,然后得到一個初始翻譯y~=arg max_y p(y| x, z);
(2)從后驗近似分布q(z|x, y~; Φ)不斷采樣隱變量,用beam search重解碼以最大化ELBO。從而迭代生成y~:

每個步驟的解碼得分由x->y翻譯模型和y的語言模型決定,這有助于翻譯結果更像target語種。重建的重排得分由y->x和x的語言模型決定。重排是指翻譯后對候選的重新排序。在重排中引入重建得分確實有助于翻譯效果的提升。
實驗數據集:WMT16 En-Ro,IWSLT16 EN-DE, WMT14 EN-DE 和 NIST EN-ZH。
? MGNMT能更充分地利用非平行語料
對所有的語言,使用的非平行語料如下Table 1所示:

Table 1:每個翻譯任務數據集的統計結果
下面兩個Table是模型在各個數據集上的實驗結果。可以看出,MGNMT+非平行語料在所有實驗上取得最好結果。
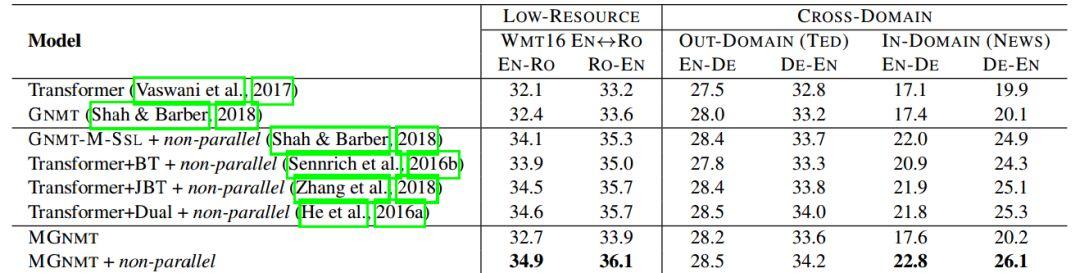
Table 2:在low-resource和跨領域翻譯任務上的BLEU得分
在Table 2中值得注意的是,在跨領域數據集中使用非平行語料的MGNMT取得了最好的結果。
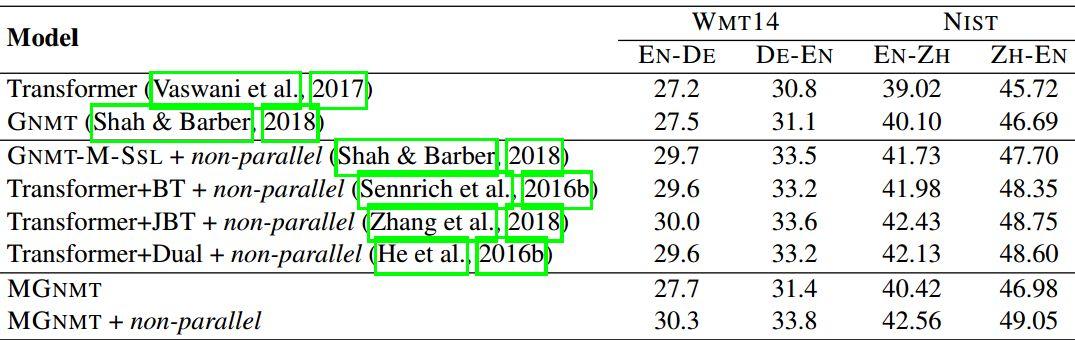
Table 3:resource-rich語種數據集上的BLEU得分
綜合這兩張Table,無論是low-resource還是resource-rich,MG-NMT都能取得很好的效果,尤其是加了非平行語料之后。
? MGNMT中引入語言模型性能更好
Table 4展示在解碼中引入語言模型的影響。表中的LM-FUSION表示 插入一個預訓練的語言模型,而不是像MG-NMT一樣一起訓練。可以看到,常規直接 插入LM的效果不如本文的方法。

Table 4:在解碼中引入語言模型的實驗結果
? 非平行語料的影響
無論是Transformer還是MGNMT,都能從更多的非平行語料中獲益,但總的來看,MGNMT從中汲取的收益更大。
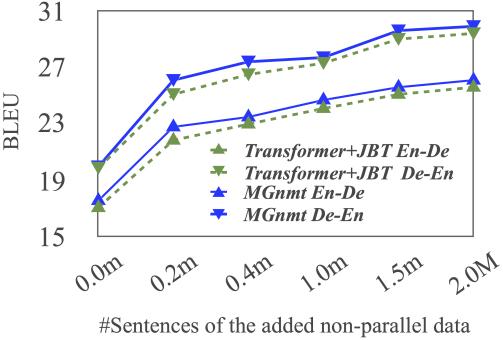
Figure 4:BLEU受非平行語料數據集規模的影響
再來看看只用單語非平行語料是否也同時有助于MGNMT兩個方向上的翻譯。從實驗結果可以看到,只添加單語非平行語料,模型的BLEU值確實得到提升。這說明這兩個方向的翻譯模型的確相互促進。
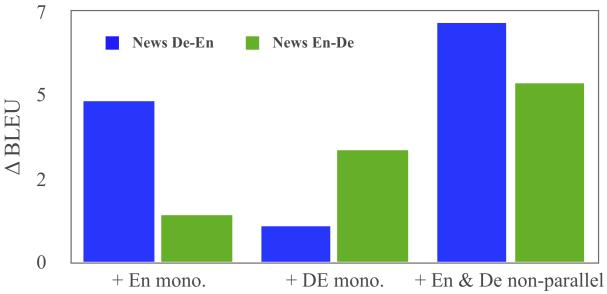
Figure 5:單語非平行語料對BLEU的影響
本文提出了一個鏡像生成式的機器翻譯模型MGNMT以更高效地利用非平行語料。
該模型通過一個共享雙語隱語義空間對雙向翻譯模型和各自的語言模型進行聯合學習。在MGNMT中兩個翻譯方向都可同時受益于非平行語料。此外,MGNMT在解碼時天然利用學習到的target語言模型,這能直接提升翻譯質量。實驗證明本文MGNMT在各個語種翻譯對中都優于其他方法。
? 未來方向
未來的研究方向,是要將MGNMT用于完全無監督機器翻譯中。
AAAI 2020 論文集:
AAAI 2020 論文解讀會 @ 望京(附PPT 下載)
AAAI 2020 論文解讀系列:
01. [中科院自動化所] 通過識別和翻譯交互打造更優的語音翻譯模型
02. [中科院自動化所] 全新視角,探究「目標檢測」與「實例分割」的互惠關系
03. [北理工] 新角度看雙線性池化,冗余、突發性問題本質源于哪里?
04. [復旦大學] 利用場景圖針對圖像序列進行故事生成
05. [騰訊 AI Lab] 2100場王者榮耀,1v1勝率99.8%,騰訊絕悟 AI 技術解讀
06. [復旦大學] 多任務學習,如何設計一個更好的參數共享機制?
07. [清華大學] 話到嘴邊卻忘了?這個模型能幫你 | 多通道反向詞典模型
08. [北航等] DualVD:一種視覺對話新框架
09. [清華大學] 借助BabelNet構建多語言義原知識庫
10. [微軟亞研] 溝壑易填:端到端語音翻譯中預訓練和微調的銜接方法
11. [微軟亞研] 時間可以是二維的嗎?基于二維時間圖的視頻內容片段檢測
12. [清華大學] 用于少次關系學習的神經網絡雪球機制
13. [中科院自動化所] 通過解糾纏模型探測語義和語法的大腦表征機制
14. [中科院自動化所] 多模態基準指導的生成式多模態自動文摘
15. [南京大學] 利用多頭注意力機制生成多樣性翻譯
16. [UCSB 王威廉組] 零樣本學習,來擴充知識圖譜(視頻解讀)
https://www.toutiao.com/i6779699118714389006/
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





