溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
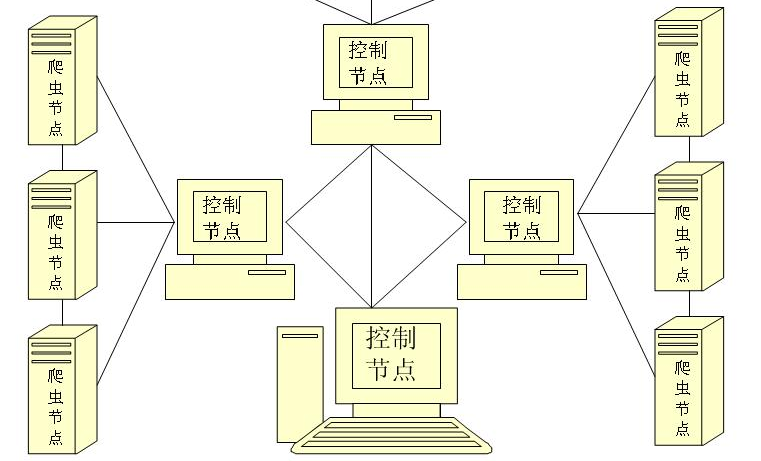
分布式網絡爬蟲包含多個爬蟲,每個爬蟲需要完成的任務和單個的爬行器類似,它們從互聯網上下載網頁,并把網頁保存在本地的磁盤,從中抽取URL并沿著這些URL的指向繼續爬行。由于并行爬行器需要分割下載任務,可能爬蟲會將自己抽取的URL發送給其他爬蟲。這些爬蟲可能分布在同一個局域網之中,或者分散在不同的地理位置。
根據爬蟲的分散程度不同,可以把分布式爬行器分成以下兩大類:
1、基于局域網分布式網絡爬蟲:這種分布式爬行器的所有爬蟲在同一個局域網里運行,通過高速的網絡連接相互通信。這些爬蟲通過同一個網絡去訪問外部互聯網,下載網頁,所有的網絡負載都集中在他們所在的那個局域網的出口上。由于局域網的帶寬較高,爬蟲之間的通信的效率能夠得到保證;但是網絡出口的總帶寬上限是固定的,爬蟲的數量會受到局域網出口帶寬的限制。
2、基于廣域網分布式網絡爬蟲:當并行爬行器的爬蟲分別運行在不同地理位置(或網絡位置),我們稱這種并行爬行器為分布式爬行器。例如,分布式爬行器的爬蟲可能位于中國,日本,和美國,分別負責下載這三地的網頁;或者位于CHINANET,CERNET,CEINET,分別負責下載這三個網絡的中的網頁。分布式爬行器的優勢在于可以子在一定程度上分散網絡流量,減小網絡出口的負載。如果爬蟲分布在不同的地理位置(或網絡位置),需要間隔多長時間進行一次相互通信就成為了一個值得考慮的問題。爬蟲之間的通訊帶寬可能是有限的,通常需要通過互聯網進行通信。
分布式網絡爬蟲是一項十分復雜系統。需要考慮很多方面因素。性能可以說是它這重要的指標。當然硬件層面的資源也是必須的。
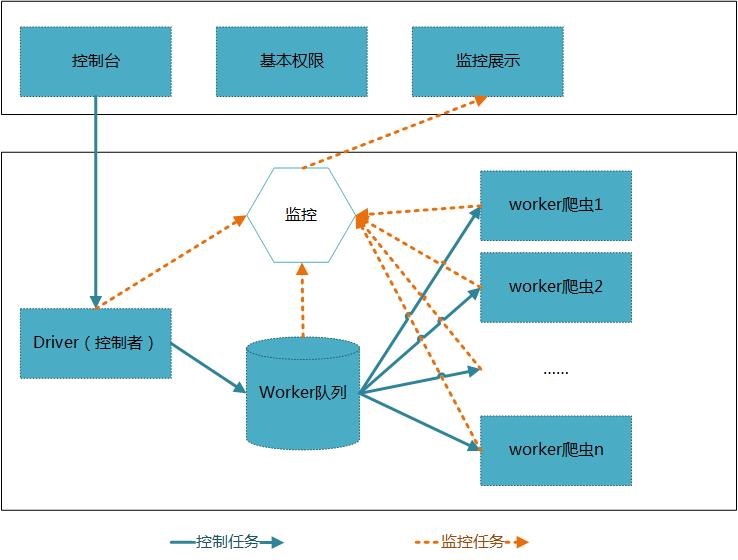
下面是項目的總體架構,第一個版本基于此方案來做。
上面的web層包括:控制臺、基本權限、監控展示等,還可以根據需要再一步進行擴展。
核心層由控制者統一調度,將任務發給工人隊列中的工人進行爬取操作。各個結點動態的向監控模塊發送模塊狀態等信息,統一由展示層展示。
眾推,開源版的今日頭條!
基于hadoop思維的分布式網絡爬蟲。
目前已經將fourinone、jeesite、webmagic整合進來,并且進一步進行改進。想最終做成一個基于設計器的動態可配置的分布式爬蟲系統,這個是第一階段的目標。
目前項目進展情況:
1、sourceer,可以接入多種數據源,接口已經定義(加入builder封裝,可以使用簡單爬蟲)。
2、web架構工程(web工程上傳并測試成功,權限、基礎框架改造,導入等已經錄成視頻,刪除activiti,刪除cms部分)。
3、分布式框架研究(分布式項目分包,添加部分注釋,測試單機單工人爬取)。
4、插件化整合。
5、文章等各種去重方式及算法(目前已實現bloomfilter,指紋算法去重,已經實現simhash,分詞算法(ansj))。
6、分類器測試(bayes,文本分類單機測試成功)。
項目地址:
(分布式爬蟲)http://git.oschina.net/zongtui/zongtui-webcrawler
(去重過濾器)https://git.oschina.net/zongtui/zongtui-filter
(文本分類器)https://git.oschina.net/zongtui/zongtui-classifier
(文檔目錄)https://git.oschina.net/zongtui/zongtui-doc
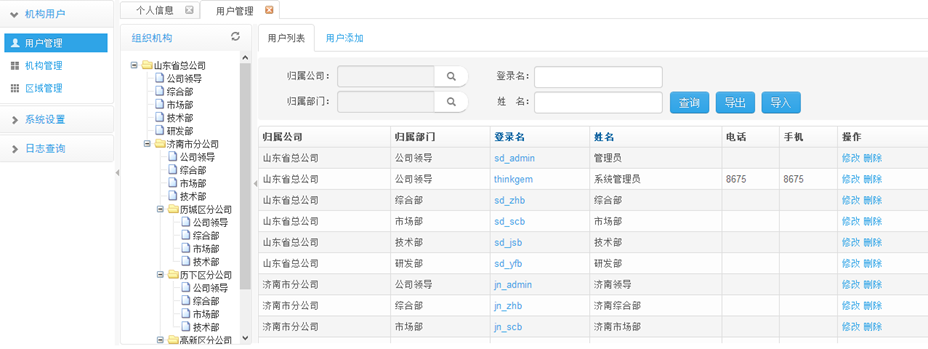
項目界面:
啟動jetty,目前皮膚暫時還未換。
目前項目正在進一步完善當中,希望能得到你更多的意見!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





