溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
美美今天請來了我們技術團隊很厲害的iOS女神亞男小姐姐深度剖析Swift,她特別講解了如何才能開發出高性能的Swift程序。希望對你有所幫助哦~Enjoy Reading!
簡介
2014年,蘋果公司在WWDC上發布Swift這一新的編程語言。經過幾年的發展,Swift已經成為iOS開發語言的“中流砥柱”,Swift提供了非常靈活的高級別特性,例如協議、閉包、泛型等,并且Swift還進一步開發了強大的SIL(Swift Intermediate Language)用于對編譯器進行優化,使得Swift相比Objective-C運行更快性能更優,Swift內部如何實現性能的優化,我們本文就進行一下解讀,希望能對大家有所啟發和幫助。
針對Swift性能提升這一問題,我們可以從概念上拆分為兩個部分:
編譯器:Swift編譯器進行的性能優化,從階段分為編譯期和運行期,內容分為時間優化和空間優化。
開發者:通過使用合適的數據結構和關鍵字,幫助編譯器獲取更多信息,進行優化。
下面我們將從這兩個角度切入,對Swift性能優化進行分析。通過了解編譯器對不同數據結構處理的內部實現,來選擇最合適的算法機制,并利用編譯器的優化特性,編寫高性能的程序。
理解Swift的性能,首先要清楚Swift的數據結構,組件關系和編譯運行方式。
數據結構
Swift的數據結構可以大體拆分為:Class,Struct,Enum。
組件關系
組件關系可以分為:inheritance,protocols,generics。
方法分派方式
方法分派方式可以分為Static dispatch和Dynamic dispatch。
要在開發中提高Swift性能,需要開發者去了解這幾種數據結構和組件關系以及它們的內部實現,從而通過選擇最合適的抽象機制來提升性能。
首先我們對于性能標準進行一個概念陳述,性能標準涵蓋三個標準:
Allocation
Reference counting
Method dispatch
接下來,我們會分別對這幾個指標進行說明。
內存分配可以分為堆區棧區,在棧的內存分配速度要高于堆,結構體和類在堆棧分配是不同的。
Stack
基本數據類型和結構體默認在棧區,棧區內存是連續的,通過出棧入棧進行分配和銷毀,速度很快,高于堆區。
我們通過一些例子進行說明:
//示例 1
// Allocation
// Struct
struct Point {
var x, y:Double
func draw() { … }
}
let point1 = Point(x:0, y:0) //進行point1初始化,開辟棧內存
var point2 = point1 //初始化point2,拷貝point1內容,開辟新內存
point2.x = 5 //對point2的操作不會影響point1
// use `point1`
// use `point2`
以上結構體的內存是在棧區分配的,內部的變量也是內聯在棧區。將point1賦值給point2實際操作是在棧區進行了一份拷貝,產生了新的內存消耗point2,這使得point1和point2是完全獨立的兩個實例,它們之間的操作互不影響。在使用point1和point2之后,會進行銷毀。
Heap
高級的數據結構,比如類,分配在堆區。初始化時查找沒有使用的內存塊,銷毀時再從內存塊中清除。因為堆區可能存在多線程的操作問題,為了保證線程安全,需要進行加鎖操作,因此也是一種性能消耗。
// Allocation
// Class
class Point {
var x, y:Double
func draw() { … }
}
let point1 = Point(x:0, y:0) //在堆區分配內存,棧區只是存儲地址指針
let point2 = point1 //不產生新的實例,而是對point2增加對堆區內存引用的指針
point2.x = 5 //因為point1和point2是一個實例,所以point1的值也會被修改
// use `point1`
// use `point2`
以上我們初始化了一個Class類型,在棧區分配一塊內存,但是和結構體直接在棧內存儲數值不同,我們只在棧區存儲了對象的指針,指針指向的對象的內存是分配在堆區的。需要注意的是,為了管理對象內存,在堆區初始化時,除了分配屬性內存(這里是Double類型的x,y),還會有額外的兩個字段,分別是type和refCount,這個包含了type,refCount和實際屬性的結構被稱為blue box。
內存分配總結
從初始化角度,Class相比Struct需要在堆區分配內存,進行內存管理,使用了指針,有更強大的特性,但是性能較低。
優化方式:
對于頻繁操作(比如通信軟件的內容氣泡展示),盡量使用Struct替代Class,因為棧內存分配更快,更安全,操作更快。
Swift通過引用計數管理堆對象內存,當引用計數為0時,Swift確認沒有對象再引用該內存,所以將內存釋放。
對于引用計數的管理是一個非常高頻的間接操作,并且需要考慮線程安全,使得引用計數的操作需要較高的性能消耗。
對于基本數據類型的Struct來說,沒有堆內存分配和引用計數的管理,性能更高更安全,但是對于復雜的結構體,如:
// Reference Counting
// Struct containing references
struct Label {
var text:String
var font:UIFont
func draw() { … }
}
let label1 = Label(text:"Hi", font:font) //棧區包含了存儲在堆區的指針
let label2 = label1 //label2產生新的指針,和label1一樣指向同樣的string和font地址
// use `label1`
// use `label2`
這里看到,包含了引用的結構體相比Class,需要管理雙倍的引用計數。每次將結構體作為參數傳遞給方法或者進行直接拷貝時,都會出現多份引用計數。下圖可以比較直觀的理解:
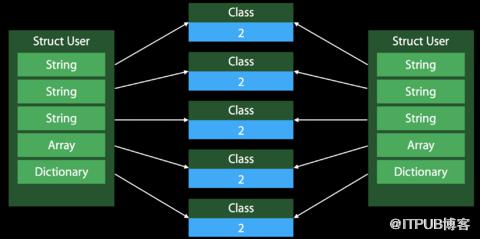
Class在拷貝時的處理方式:
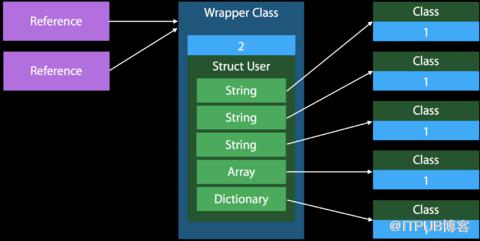
引用計數總結
Class在堆區分配內存,需要使用引用計數器進行內存管理。
基本類型的Struct在棧區分配內存,無引用計數管理。
包含強類型的Struct通過指針管理在堆區的屬性,對結構體的拷貝會創建新的棧內存,創建多份引用的指針,Class只會有一份。
優化方式
在使用結構體時:
通過使用精確類型,例如UUID替代String(UUID字節長度固定128字節,而不是String任意長度),這樣就可以進行內存內聯,在棧內存儲UUID,我們知道,棧內存管理更快更安全,并且不需要引用計數。
Enum替代String,在棧內管理內存,無引用計數,并且從語法上對于開發者更友好。
我們之前在Static dispatch VS Dynamic dispatch中提到過,能夠在編譯期確定執行方法的方式叫做靜態分派Static dispatch,無法在編譯期確定,只能在運行時去確定執行方法的分派方式叫做動態分派Dynamic dispatch。
Static dispatch更快,而且靜態分派可以進行內聯等進一步的優化,使得執行更快速,性能更高。
但是對于多態的情況,我們不能在編譯期確定最終的類型,這里就用到了Dynamic dispatch動態分派。動態分派的實現是,每種類型都會創建一張表,表內是一個包含了方法指針的數組。動態分派更靈活,但是因為有查表和跳轉的操作,并且因為很多特點對于編譯器來說并不明確,所以相當于block了編譯器的一些后期優化。所以速度慢于Static dispatch。
下面看一段多態代碼,以及分析實現方式:
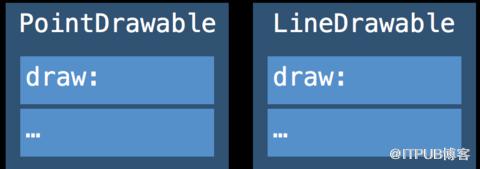
//引用語義實現的多態
class Drawable { func draw() {} }
class Point :Drawable {
var x, y:Double
override func draw() { … }
}
class Line :Drawable {
var x1, y1, x2, y2:Double
override func draw() { … }
}
var drawables:[Drawable]
for d in drawables {
d.draw()
}
Method Dispatch總結
Class默認使用Dynamic dispatch,因為在編譯期幾乎每個環節的信息都無法確定,所以阻礙了編譯器的優化,比如inline和whole module inline。
使用Static dispatch代替Dynamic dispatch提升性能
我們知道Static dispatch快于Dynamic dispatch,如何在開發中去盡可能使用Static dispatch。
inheritance constraints繼承約束
我們可以使用final關鍵字去修飾Class,以此生成的Final class,使用Static dispatch。
access control訪問控制private關鍵字修飾,使得方法或屬性只對當前類可見。編譯器會對方法進行Static dispatch。
編譯器可以通過whole module optimization檢查繼承關系,對某些沒有標記final的類通過計算,如果能在編譯期確定執行的方法,則使用Static dispatch。Struct默認使用Static dispatch。
Swift快于OC的一個關鍵是可以消解動態分派。
總結
Swift提供了更靈活的Struct,用以在內存、引用計數、方法分派等角度去進行性能的優化,在正確的時機選擇正確的數據結構,可以使我們的代碼性能更快更安全。
延伸
你可能會問Struct如何實現多態呢?答案是protocol oriented programming。
以上分析了影響性能的幾個標準,那么不同的算法機制Class,Protocol Types和Generic code,它們在這三方面的表現如何,Protocol Type和Generic code分別是怎么實現的呢?我們帶著這個問題看下去。
這里我們會討論Protocol Type如何存儲和拷貝變量,以及方法分派是如何實現的。不通過繼承或者引用語義的多態:
protocol Drawable { func draw() }
struct Point :Drawable {
var x, y:Double
func draw() { … }
}
struct Line :Drawable {
var x1, y1, x2, y2:Double
func draw() { … }
}
var drawables:[Drawable] //遵守了Drawable協議的類型集合,可能是point或者line
for d in drawables {
d.draw()
}
以上通過Protocol Type實現多態,幾個類之間沒有繼承關系,故不能按照慣例借助V-Table實現動態分派。
如果想了解Vtable和Witness table實現,可以進行點擊查看,這里不做細節說明。
因為Point和Line的尺寸不同,數組存儲數據實現一致性存儲,使用了Existential Container。查找正確的執行方法則使用了 Protoloc Witness Table。
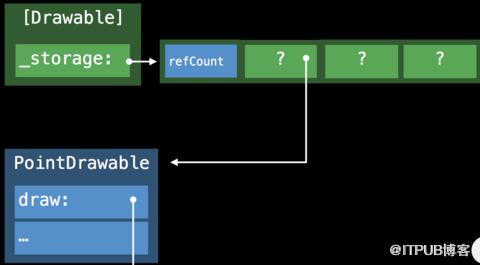
Existential Container是一種特殊的內存布局方式,用于管理遵守了相同協議的數據類型Protocol Type,這些數據類型因為不共享同一繼承關系(這是V-Table實現的前提),并且內存空間尺寸不同,使用Existential Container進行管理,使其具有存儲的一致性。
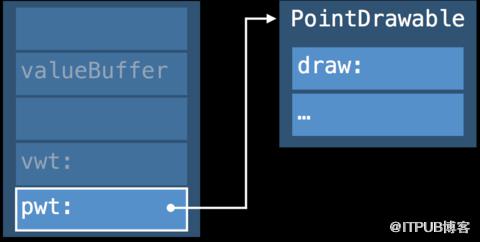
結構如下:
三個詞大小的valueBuffer
這里介紹一下valueBuffer結構,valueBuffer有三個詞,每個詞包含8個字節,存儲的可能是值,也可能是對象的指針。對于small value(空間小于valueBuffer),直接存儲在valueBuffer的地址內, inline valueBuffer,無額外堆內存初始化。當值的數量大于3個屬性即large value,或者總尺寸超過valueBuffer的占位,就會在堆區開辟內存,將其存儲在堆區,valueBuffer存儲內存指針。
value witness table的引用
因為Protocol Type的類型不同,內存空間,初始化方法等都不相同,為了對Protocol Type生命周期進行專項管理,用到了Value Witness Table。
protocol witness table的引用
管理Protocol Type的方法分派。
內存分布如下:
1. payload_data_0 = 0x0000000000000004,
2. payload_data_1 = 0x0000000000000000,
3. payload_data_2 = 0x0000000000000000,
4. instance_type = 0x000000010d6dc408 ExistentialContainers`type
metadata for ExistentialContainers.Car,
5. protocol_witness_0 = 0x000000010d6dc1c0
ExistentialContainers protocol witness table for
ExistentialContainers.Car:ExistentialContainers.Drivable
in ExistentialContainers
為了實現Class多態也就是引用語義多態,需要V-Table來實現,但是V-Table的前提是具有同一個父類即共享相同的繼承關系,但是對于Protocol Type來說,并不具備此特征,故為了支持Struct的多態,需要用到protocol oriented programming機制,也就是借助Protocol Witness Table來實現(細節可以點擊Vtable和witness table實現,每個結構體會創造PWT表,內部包含指針,指向方法具體實現)。
用于管理任意值的初始化、拷貝、銷毀。

Value Witness Table的結構如上,是用于管理遵守了協議的Protocol Type實例的初始化,拷貝,內存消減和銷毀的。
Value Witness Table在SIL中還可以拆分為%relative_vwtable和%absolute_vwtable,我們這里先不做展開。
Value Witness Table和Protocol Witness Table通過分工,去管理Protocol Type實例的內存管理(初始化,拷貝,銷毀)和方法調用。
我們來借助具體的示例進行進一步了解:
// Protocol Types
// The Existential Container in action
func drawACopy(local :Drawable) {
local.draw()
}
let val :Drawable = Point()
drawACopy(val)
在Swift編譯器中,通過Existential Container實現的偽代碼如下:
// Protocol Types
// The Existential Container in action
func drawACopy(local :Drawable) {
local.draw()
}
let val :Drawable = Point()
drawACopy(val)
//existential container的偽代碼結構
struct ExistContDrawable {
var valueBuffer:(Int, Int, Int)
var vwt:ValueWitnessTable
var pwt:DrawableProtocolWitnessTable
}
// drawACopy方法生成的偽代碼
func drawACopy(val:ExistContDrawable) { //將existential container傳入
var local = ExistContDrawable() //初始化container
let vwt = val.vwt //獲取value witness table,用于管理生命周期
let pwt = val.pwt //獲取protocol witness table,用于進行方法分派
local.type = type
local.pwt = pwt
vwt.allocateBufferAndCopyValue(&local, val) //vwt進行生命周期管理,初始化或者拷貝
pwt.draw(vwt.projectBuffer(&local)) //pwt查找方法,這里說一下projectBuffer,因為不同類型在內存中是不同的(small value內聯在棧內,large value初始化在堆內,棧持有指針),所以方法的確定也是和類型相關的,我們知道,查找方法時是通過當前對象的地址,通過一定的位移去查找方法地址。
vwt.destructAndDeallocateBuffer(temp) //vwt進行生命周期管理,銷毀內存
}
我們知道,Swift中Class的實例和屬性都存儲在堆區,Struct實例在棧區,如果包含指針屬性則存儲在堆區,Protocol Type如何存儲屬性?Small Number通過Existential Container內聯實現,大數存在堆區。如何處理Copy呢?
在出現Copy情況時:
let aLine = Line(1.0, 1.0, 1.0, 3.0)
let pair = Pair(aLine, aLine)
let copy = pair

會將新的Exsitential Container的valueBuffer指向同一個value即創建指針引用,但是如果要改變值怎么辦?我們知道Struct值的修改和Class不同,Copy是不應該影響原實例的值的。
這里用到了一個技術叫做Indirect Storage With Copy-On-Write,即優先使用內存指針。通過提高內存指針的使用,來降低堆區內存的初始化。降低內存消耗。在需要修改值的時候,會先檢測引用計數檢測,如果有大于1的引用計數,則開辟新內存,創建新的實例。在對內容進行變更的時候,會開啟一塊新的內存,偽代碼如下:
class LineStorage { var x1, y1, x2, y2:Double }
struct Line :Drawable {
var storage :LineStorage
init() { storage = LineStorage(Point(), Point()) }
func draw() { … }
mutating func move() {
if !isUniquelyReferencedNonObjc(&storage) { //如何存在多份引用,則開啟新內存,否則直接修改
storage = LineStorage(storage)
}
storage。start = ...
}
}
這樣實現的目的:通過多份指針去引用同一份地址的成本遠遠低于開辟多份堆內存。以下對比圖:
支持Protocol Type的動態多態(Dynamic Polymorphism)行為。
通過使用Witness Table和Existential Container來實現。
對于大數的拷貝可以通過Indirect Storage間接存儲來進行優化。
說到動態多態Dynamic Polymorphism,我們就要問了,什么是靜態多態Static Polymorphism,看看下面示例:
// Drawing a copy
protocol Drawable {
func draw()
}
func drawACopy(local :Drawable) {
local.draw()
}
let line = Line()
drawACopy(line)
// ...
let point = Point()
drawACopy(point)
這種情況我們就可以用到泛型Generic code來實現,進行進一步優化。
我們接下來會討論泛型屬性的存儲方式和泛型方法是如何分派的。泛型和Protocol Type的區別在于:
泛型支持的是靜態多態。
每個調用上下文只有一種類型。
查看下面的示例,foo和bar方法是同一種類型。
在調用鏈中會通過類型降級進行類型取代。
對于以下示例:
func foo<T:Drawable>(local :T) {
bar(local)
}
func bar<T:Drawable>(local:T) { … }
let point = Point()
foo(point)
分析方法foo和bar的調用過程:
//調用過程
foo(point)-->foo<T = Point>(point) //在方法執行時,Swift將泛型T綁定為調用方使用的具體類型,這里為Point
bar(local) -->bar<T = Point>(local) //在調用內部bar方法時,會使用foo已經綁定的變量類型Point,可以看到,泛型T在這里已經被降級,通過類型Point進行取代
泛型方法調用的具體實現為:
同一種類型的任何實例,都共享同樣的實現,即使用同一個Protocol Witness Table。
使用Protocol/Value Witness Table。
每個調用上下文只有一種類型:這里沒有使用Existential Container, 而是將Protocol/Value Witness Table作為調用方的額外參數進行傳遞。
變量初始化和方法調用,都使用傳入的VWT和PWT來執行。
看到這里,我們并不覺得泛型比Protocol Type有什么更快的特性,泛型如何更快呢?靜態多態前提下可以進行進一步的優化,稱為特定泛型優化。
靜態多態:在調用站中只有一種類型
Swift使用只有一種類型的特點,來進行類型降級取代。
類型降級后,產生特定類型的方法
為泛型的每個類型創造對應的方法
這時候你可能會問,那每一種類型都產生一個新的方法,代碼空間豈不爆炸?
靜態多態下進行特定優化specialization
因為是靜態多態。所以可以進行很強大的優化,比如進行內聯實現,并且通過獲取上下文來進行更進一步的優化。從而降低方法數量。優化后可以更精確和具體。
例如:
func min<T:Comparable>(x:T, y:T) -> T {
return y < x ? y : x
}
從普通的泛型展開如下,因為要支持所有類型的min方法,所以需要對泛型類型進行計算,包括初始化地址、內存分配、生命周期管理等。除了對value的操作,還要對方法進行操作。這是一個非常的的工程。
func min<T:Comparable>(x:T, y:T, FTable:FunctionTable) -> T {
let xCopy = FTable.copy(x)
let yCopy = FTable.copy(y)
let m = FTable.lessThan(yCopy, xCopy) ? y :x
FTable.release(x)
FTable.release(y)
return m
}
在確定入參類型時,比如Int,編譯器可以通過泛型特化,進行類型取代(Type Substitute),優化為:
func min<Int>(x:Int, y:Int) -> Int {
return y < x ? y :x
}
泛型特化specilization是何時發生的?
在使用特定優化時,調用方需要進行類型推斷,這里需要知曉類型的上下文,例如類型的定義和內部方法實現。如果調用方和類型是單獨編譯的,就無法在調用方推斷類型的內部實行,就無法使用特定優化,保證這些代碼一起進行編譯,這里就用到了whole module optimization。而whole module optimization是對于調用方和被調用方的方法在不同文件時,對其進行泛型特化優化的前提。
特定泛型的進一步優化:
// Pairs in our program using generic types
struct Pair<T :Drawable> {
init(_ f:T, _ s:T) {
first = f ; second = s
}
var first:T
var second:T
}
let pairOfLines = Pair(Line(), Line())
// ...
let pairOfPoint = Pair(Point(), Point())
在用到多種泛型,且確定泛型類型不會在運行時修改時,就可以對成對泛型的使用進行進一步優化。
優化的方式是將泛型的內存分配由指針指定,變為內存內聯,不再有額外的堆初始化消耗。請注意,因為進行了存儲內聯,已經確定了泛型特定類型的內存分布,泛型的內存內聯不能存儲不同類型。所以再次強調此種優化只適用于在運行時不會修改泛型類型,即不能同時支持一個方法中包含line和point兩種類型。
whole module optimization是用于Swift編譯器的優化機制。可以通過-whole-module-optimization (或 -wmo)進行打開。在XCode 8之后默認打開。 Swift Package Manager在release模式默認使用whole module optimization。
module是多個文件集合。
編譯器在對源文件進行語法分析之后,會對其進行優化,生成機器碼并輸出目標文件,之后鏈接器聯合所有的目標文件生成共享庫或可執行文件。
whole module optimization通過跨函數優化,可以進行內聯等優化操作,對于泛型,可以通過獲取類型的具體實現來進行推斷優化,進行類型降級方法內聯,刪除多余方法等操作。
全模塊優化的優勢
編譯器掌握所有方法的實現,可以進行內聯和泛型特化等優化,通過計算所有方法的引用,移除多余的引用計數操作。
通過知曉所有的非公共方法,如果這寫方法沒有被使用,就可以對其進行消除。
如何降低編譯時間
和全模塊優化相反的是文件優化,即對單個文件進行編譯。這樣的好處在于可以并行執行,并且對于沒有修改的文件不會再次編譯。缺點在于編譯器無法獲知全貌,無法進行深度優化,全模塊優化如何避免沒修改的文件再次編譯。
編譯器內部運行過程分為:語法分析,類型檢查,SIL優化,LLVM后端處理。
語法分析和類型檢查一般很快,SIL優化執行了重要的Swift特定優化,例如泛型特化和方法內聯等,該過程大概占用真個編譯時間的三分之一。LLVM后端執行占用了大部分的編譯時間,用于運行降級優化和生成代碼。
進行全模塊優化后,SIL優化會將模塊再次拆分為多個部分,LLVM后端通過多線程對這些拆分模塊進行處理,對于沒有修改的部分,不會進行再處理。這樣就避免了修改一小部分,整個大模塊進行LLVM后端執行,并且多線程并行操作也會縮短處理時間。
Swift因為方法分派機制問題,所以在設計和優化后,會產生和我們常規理解不太一致的結果,這當然不能算Bug。但是還是要單獨進行說明,避免在開發過程中,因為對機制的掌握不足,造成預期和執行出入導致的問題。
Message dispatch
我們通過上面說明結合Static dispatch VS Dynamic dispatch對方法分派方式有了了解。這里需要對Objective-C的方法分派方式進行說明。
熟悉OC的人都知道,OC采用了運行時機制使用obj_msgSend發送消息,runtime非常的靈活,我們不僅可以對方法調用采用swizzling,對于對象也可以通過isa-swizzling來擴展功能,應用場景有我們常用的hook和大家熟知的KVO。
大家在使用Swift進行開發時都會問,Swift是否可以使用OC的運行時和消息轉發機制呢?答案是可以。
Swift可以通過關鍵字dynamic對方法進行標記,這樣就會告訴編譯器,此方法使用的是OC的運行時機制。
注意:我們常見的關鍵字
@ObjC并不會改變Swift原有的方法分派機制,關鍵字@ObjC的作用只是告訴編譯器,該段代碼對于OC可見。
總結來說,Swift通過dynamic關鍵字的擴展后,一共包含三種方法分派方式:Static dispatch,Table dispatch和Message dispatch。下表為不同的數據結構在不同情況下采取的分派方式:
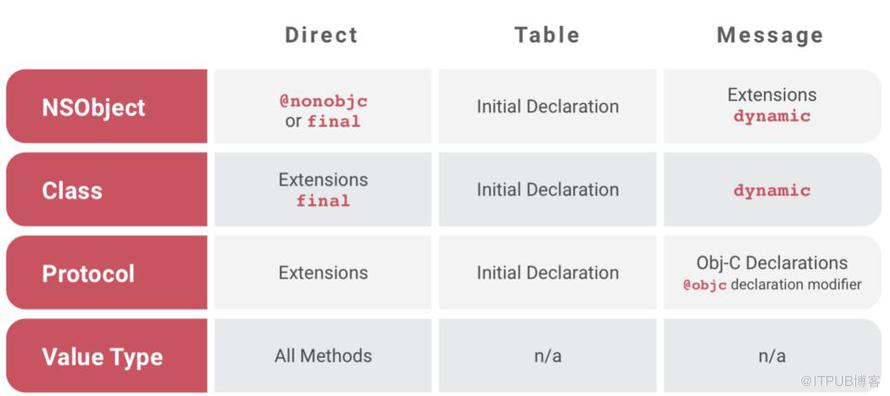
如果在開發過程中,錯誤的混合了這幾種分派方式,就可能出現Bug,以下我們對這些Bug進行分析:
SR-584
此情況是在子類的extension中重載父類方法時,出現和預期不同的行為。
class Base:NSObject {
var directProperty:String { return "This is Base" }
var indirectProperty:String { return directProperty }
}
class Sub:Base { }
extension Sub {
override var directProperty:String { return "This is Sub" }
}
執行以下代碼,直接調用沒有問題:
Base().directProperty // “This is Base”
Sub().directProperty // “This is Sub”
間接調用結果和預期不同:
Base()。indirectProperty // “This is Base”
Sub()。indirectProperty // expected "this is Sub",but is “This is Base” <- Unexpected!
在Base.directProperty前添加dynamic關鍵字就可以獲得"this is Sub"的結果。Swift在extension 文檔中說明,不能在extension中重載已經存在的方法。
“Extensions can add new functionality to a type, but they cannot override existing functionality.”
會出現警告:Cannot override a non-dynamic class declaration from an extension。
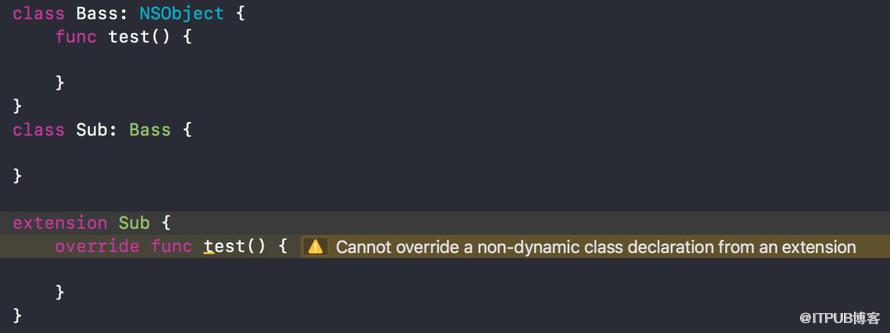
出現這個問題的原因是,NSObject的extension是使用的Message dispatch,而Initial Declaration使用的是Table dispath(查看上圖 Swift Dispatch Method)。extension重載的方法添加在了Message dispatch內,沒有修改虛函數表,虛函數表內還是父類的方法,故會執行父類方法。想在extension重載方法,需要標明dynamic來使用Message dispatch。
SR-103
協議的擴展內實現的方法,無法被遵守類的子類重載:
protocol Greetable {
func sayHi()
}
extension Greetable {
func sayHi() {
print("Hello")
}
}
func greetings(greeter:Greetable) {
greeter.sayHi()
}
現在定義一個遵守了協議的類Person。遵守協議類的子類LoudPerson:
class Person:Greetable {
}
class LoudPerson:Person {
func sayHi() {
print("sub")
}
}
執行下面代碼結果為:
var sub:LoudPerson = LoudPerson()
sub.sayHi() //sub
不符合預期的代碼:
var sub:Person = LoudPerson()
sub.sayHi() //HellO <-使用了protocol的默認實現
注意,在子類LoudPerson中沒有出現override關鍵字。可以理解為LoudPerson并沒有成功注冊Greetable在Witness table的方法。所以對于聲明為Person實際為LoudPerson的實例,會在編譯器通過Person去查找,Person沒有實現協議方法,則不產生Witness table,sayHi方法是直接調用的。解決辦法是在base類內實現協議方法,無需實現也要提供默認方法。或者將基類標記為final來避免繼承。
進一步通過示例去理解:
// Defined protocol。
protocol A {
func a() -> Int
}
extension A {
func a() -> Int {
return 0
}
}
// A class doesn't have implement of the function。
class B:A {}
class C:B {
func a() -> Int {
return 1
}
}
// A class has implement of the function。
class D:A {
func a() -> Int {
return 1
}
}
class E:D {
override func a() -> Int {
return 2
}
}
// Failure cases。
B().a() // 0
C().a() // 1
(C() as A).a() // 0 # We thought return 1。
// Success cases。
D().a() // 1
(D() as A).a() // 1
E().a() // 2
(E() as A).a() // 2
其他
我們知道Class extension使用的是Static dispatch:
class MyClass {
}
extension MyClass {
func extensionMethod() {}
}
class SubClass:MyClass {
override func extensionMethod() {}
}
以上代碼會出現錯誤,提示Declarations in extensions can not be overridden yet。
影響程序的性能標準有三種:初始化方式, 引用指針和方法分派。
文中對比了兩種數據結構:Struct和Class的在不同標準下的性能表現。Swift相比OC和其它語言強化了結構體的能力,所以在了解以上性能表現的前提下,通過利用結構體可以有效提升性能。
在此基礎上,我們還介紹了功能強大的結構體的類:Protocol Type和Generic。并且介紹了它們如何支持多態以及通過使用有條件限制的泛型如何讓程序更快。
swift memorylayout
witness table video
protocol types pdf
protocol and value oriented programming in UIKit apps video
optimizing swift performance
whole module optimizaiton
increasing performance by reducing dynamic dispatch
protocols generics existential container
protocols and generics
why swift is swift
swift method dispatch
swift extension
universal dynamic dispatch for method calls
compiler performance.md
structures and classes
作者簡介
亞男,美團點評iOS工程師。2017年加入美團點評,負責美團管家開發,研究編譯器原理。目前正積極推動Swift組件化建設。
歡迎加入美團iOS技術交流群,跟作者零距離交流。進群方式:請加美美同學的微信(微信號:MTDPtech01),回復:iOS,美美會自動拉你進群。
---------- END ----------
招聘信息
我們餐飲生態技術部是一個技術氛圍活躍,大牛聚集的地方。新到店緊握真正的大規模SaaS實戰機會,多租戶、數據、安全、開放平臺等全方位的挑戰。業務領域復雜技術挑戰多,技術和業務能力迅速提升,最重要的是,加入我們,你將實現真正通過代碼來改變行業的夢想。我們歡迎各端人才加入,Java優先。感興趣的同學趕緊發送簡歷至 zhaoyanan02@meituan.com,我們期待你的到來。
原文鏈接:https://mp.weixin.qq.com/s/U95QmOOjeXkk-yC23cuZCQ
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





