溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
SQL語言只是訪問、操作數據庫的語言,并不是一種具有流程控制的程序設計語言,而只有程序設計語言才能用于應用軟件的開發。PL /SQL是一種高級數據庫程序設計語言,該語言專門用于在各種環境下對ORACLE數據庫進行訪問。由于該語言集成于數據庫服務器中,所以PL/SQL代碼可以對數據進行快速高效的處理。除此之外,可以在ORACLE數據庫的某些客戶端工具中,使用PL/SQL語言也是該語言的一個特點。本章的主要內容是討論引入PL/SQL語言的必要性和該語言的主要特點,以及了解PL/SQL語言的重要性和數據庫版本問題。還要介紹一些貫穿全書的更詳細的高級概念,并在本章的最后就我們在本書案例中使用的數據庫表的若干約定做一說明。
1.1 SQL與PL/SQL
1.1.1 什么是PL/SQL?
PL/SQL是 Procedure Language & Structured Query Language 的縮寫。ORACLE的SQL是支持ANSI(American national Standards Institute)和ISO92 (International Standards Organization)標準的產品。PL/SQL是對SQL語言存儲過程語言的擴展。從ORACLE6以后,ORACLE的RDBMS附帶了PL/SQL。它現在已經成為一種過程處理語言,簡稱PL/SQL。目前的PL/SQL包括兩部分,一部分是數據庫引擎部分;另一部分是可嵌入到許多產品(如C語言,JAVA語言等)工具中的獨立引擎。可以將這兩部分稱為:數據庫PL/SQL和工具PL/SQL。兩者的編程非常相似。都具有編程結構、語法和邏輯機制。工具PL/SQL另外還增加了用于支持工具(如ORACLE Forms)的句法,如:在窗體上設置按鈕等。本章主要介紹數據庫PL/SQL內容。
1.2 PL/SQL的優點或特征
1.2.1 有利于客戶/服務器環境應用的運行
對于客戶/服務器環境來說,真正的瓶頸是網絡上。無論網絡多快,只要客戶端與服務器進行大量的數據交換。應用運行的效率自然就回受到影響。如果使用PL/SQL進行編程,將這種具有大量數據處理的應用放在服務器端來執行。自然就省去了數據在網上的傳輸時間。
1.2.2 適合于客戶環境
PL/SQL由于分為數據庫PL/SQL部分和工具PL/SQL。對于客戶端來說,PL/SQL可以嵌套到相應的工具中,客戶端程序可以執行本地包含PL/SQL部分,也可以向服務發SQL命令或激活服務器端的PL/SQL程序運行。
1.2.3 過程化
PL/SQL是Oracle在標準SQL上的過程性擴展,不僅允許在PL/SQL程序內嵌入SQL語句,而且允許使用各種類型的條件分支語句和循環語句,可以多個應用程序之間共享其解決方案。
1.2.4 模塊化
PL/SQL程序結構是一種描述性很強、界限分明的塊結構、嵌套塊結構,被分成單獨的過程、函數、觸發器,且可以把它們組合為程序包,提高程序的模塊化能力。
1.2.5 運行錯誤的可處理性
使用PL/SQL提供的異常處理(EXCEPTION),開發人員可集中處理各種ORACLE錯誤和PL/SQL錯誤,或處理系統錯誤與自定義錯誤,以增強應用程序的健壯性。
1.2.6 提供大量內置程序包
ORACLE提供了大量的內置程序包。通過這些程序包能夠實現DBS的一些低層操作、高級功能,不論對DBA還是應用開發人員都具有重要作用。
當然還有其它的一些優點如:更好的性能、可移植性和兼容性、可維護性、易用性與快速性等。
1.3 PL/SQL 可用的SQL語句
PL/SQL是ORACLE系統的核心語言,現在ORACLE的許多部件都是由PL/SQL寫成。在PL/SQL中可以使用的SQL語句有:INSERT,UPDATE,DELETE,SELECT INTO,COMMIT,ROLLBACK,SAVEPOINT。
提示:在 PL/SQL中只能用 SQL語句中的 DML 部分,不能用 DDL 部分,如果要在PL/SQL中使用DDL(如CREATE table 等)的話,只能以動態的方式來使用。
l ORACLE 的 PL/SQL 組件在對 PL/SQL 程序進行解釋時,同時對在其所使用的表名、列名及數據類型進行檢查。
l PL/SQL 可以在SQL*PLUS 中使用。
l PL/SQL 可以在高級語言中使用。
l PL/SQL可以在ORACLE的開發工具中使用(如:SQL Developer或Procedure Builder等)。
l 其它開發工具也可以調用PL/SQL編寫的過程和函數,如Power Builder 等都可以調用服務器端的PL/SQL過程。
1.4 運行PL/SQL程序
PL/SQL程序的運行是通過ORACLE中的一個引擎來進行的。這個引擎可能在ORACLE的服務器端,也可能在 ORACLE 應用開發的客戶端。引擎執行PL/SQL中的過程性語句,然后將SQL語句發送給數據庫服務器來執行。再將結果返回給執行端。2.1 PL/SQL塊
PL/SQL程序由三個塊組成,即聲明部分、執行部分、異常處理部分。
PL/SQL塊的結構如下:
DECLARE
--聲明部分: 在此聲明PL/SQL用到的變量,類型及游標,以及局部的存儲過程和函數
BEGIN
-- 執行部分: 過程及SQL 語句 , 即程序的主要部分
EXCEPTION
-- 執行異常部分: 錯誤處理
END;
其中:執行部分不能省略。
PL/SQL塊可以分為三類:
1. 無名塊或匿名塊(anonymous):動態構造,只能執行一次,可調用其它程序,但不能被其它程序調用。
2. 命名塊(named):是帶有名稱的匿名塊,這個名稱就是標簽。
3. 子程序(subprogram):存儲在數據庫中的存儲過程、函數等。當在數據庫上建立好后可以在其它程序中調用它們。
4. 觸發器(Trigger):當數據庫發生操作時,會觸發一些事件,從而自動執行相應的程序。
5. 程序包(package):存儲在數據庫中的一組子程序、變量定義。在包中的子程序可以被其它程序包或子程序調用。但如果聲明的是局部子程序,則只能在定義該局部子程序的塊中調用該局部子程序。
2.2 PL/SQL結構
l PL/SQL塊中可以包含子塊;
l 子塊可以位于 PL/SQL中的任何部分;
l 子塊也即PL/SQL中的一條命令;
2.3 標識符
PL/SQL程序設計中的標識符定義與SQL 的標識符定義的要求相同。要求和限制有:
l 標識符名不能超過30字符;
l 第一個字符必須為字母;
l 不分大小寫;
l 不能用’-‘(減號);
l 不能是SQL保留字。
提示: 一般不要把變量名聲明與表中字段名完全一樣,如果這樣可能得到不正確的結果.
例如:下面的例子將會刪除所有的紀錄,而不是’EricHu’的記錄;
DECLARE
ename varchar2(20) :='EricHu';
BEGIN
DELETE FROM scott.emp WHERE ename=ename;
END;
變量命名在PL/SQL中有特別的講究,建議在系統的設計階段就要求所有編程人員共同遵守一定的要求,使得整個系統的文檔在規范上達到要求。下面是建議的命名方法: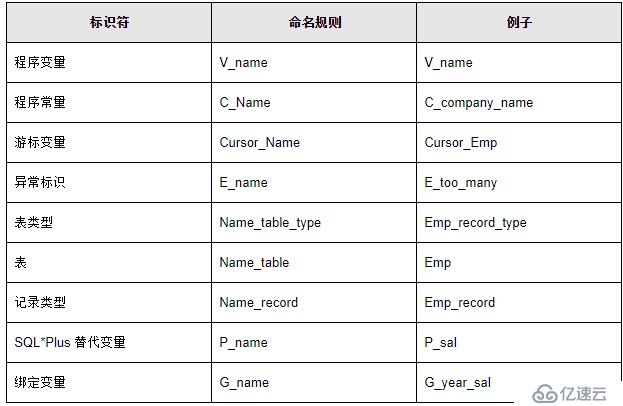
2.4 PL/SQL 變量類型
在前面的介紹中,有系統的數據類型,也可以自定義數據類型。下表給出ORACLE類型和PL/SQL中的變量類型的合法使用列表:
2.4.1 變量類型
四類數據類型
標量類型(SCALAR,或稱基本數據類型):用于保存單個值,例如字符串,數字,日期,布爾;
復合類型(COMPOSITE):復合類型可以在內部存放多種數值,類似于多個變量的集合,例如記錄類型,嵌套表,索引表,可變數組等;
引用類型(REFERENCE):用于指向另一個不同對象,例如REF CURSOR,REF;
LOB類型:大數據類型,最多可以存儲4GB的信息,主要用來處理二進制數據;
標量類型
標量類型也被稱為基本數據類型
常見標量類型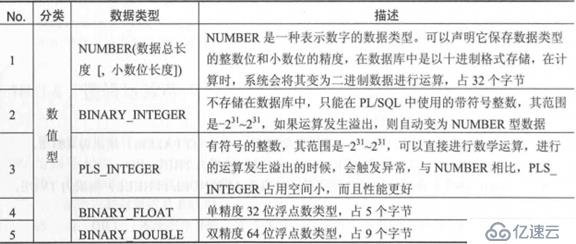
數值型
NUMBER數據類型
采用十進制類型,需將十進制轉為二進制進行計算
定義整型:NUMBER(n);
定義浮點型數據:NUMBER(m,n)
實例1:定義NUMBER變量
SQL> set serveroutput on
SQL> DECLARE
2 v_x NUMBER(3) ; -- 最多只能為3位數字
3 v_y NUMBER(5,2) ; -- 3位整數,2位小數
4 BEGIN
5 v_x := -500 ;
6 v_y := 999.88 ;
7 DBMS_OUTPUT.put_line('v_x = ' || v_x) ;
8 DBMS_OUTPUT.put_line('v_y = ' || v_y) ;
9 DBMS_OUTPUT.put_line('加法運算:' || (v_x + v_y)) ; -- 整數 + 浮點數 = 浮點數
10 END ;
11 /
v_x = -500
v_y = 999.88
加法運算:499.88
PL/SQL procedure successfully completed.
BINARY_INTEGER與PLS_INTEGER
說明:
兩者具有相同的范圍長度。與NUMBER比較,占用的范圍更小;
采用二進制補碼存儲,運算性能比NUMBER高;
兩者區別:
BINARY_INTEGER操作的數據大于其數據范圍時,會自動轉換為NUMBER型進行保存;
PLS_INTEGER操作的數據大于范圍時,會拋出異常信息
示例1:驗證PLS_INTEGER操作
SQL> DECLARE
2 v_pls1 PLS_INTEGER := 100 ;
3 v_pls2 PLS_INTEGER := 200 ;
4 v_result PLS_INTEGER ;
5 BEGIN
6 v_result := v_pls1 + v_pls2 ;
7 DBMS_OUTPUT.put_line('計算結果:' || v_result) ;
8 END ;
9 /
計算結果:300
PL/SQL procedure successfully completed.
BINARY_FLOAT與BINARY_DOUBLE
兩者比NUMBER節約空間,同時范圍更大,采用二進制存儲數據;
示例1:驗證BINARY_DOUBLE操作
SQL> DECLARE
2 v_float BINARY_FLOAT := 8909.51F ;
3 v_double BINARY_DOUBLE := 8909.51D ;
4 BEGIN
5 v_float := v_float + 1000.16 ;
6 v_double := v_double + 1000.16 ;
7 DBMS_OUTPUT.put_line('BINARY_FLOAT變量內容:' || v_float) ;
8 DBMS_OUTPUT.put_line('BINARY_DOUBLE變量內容:' || v_double) ;
9 END ;
10 /
BINARY_FLOAT變量內容:9.90966992E+003
BINARY_DOUBLE變量內容:9.9096700000000001E+003
PL/SQL procedure successfully completed.
兩者定義的常量:這些常量只能在PL/SQL中使用。這些常量分別表示BINARY_FLOAT與BINARY_DOUBLE的數據范圍,同時針對非數字與超過其類型最大值的數據標記
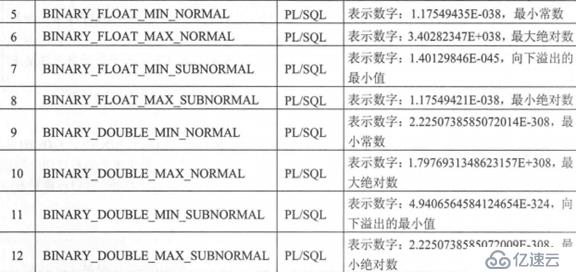
示例2:觀察表示范圍的常量內容
SQL> DECLARE
2 BEGIN
3 DBMS_OUTPUT.put_line('1、BINARY_FLOAT_MIN_NORMAL = ' || BINARY_FLOAT_MIN_NORMAL) ;
4 DBMS_OUTPUT.put_line('1、BINARY_FLOAT_MAX_NORMAL = ' || BINARY_FLOAT_MAX_NORMAL) ;
5 DBMS_OUTPUT.put_line('1、BINARY_FLOAT_MIN_SUBNORMAL = ' || BINARY_FLOAT_MIN_SUBNORMAL) ;
6 DBMS_OUTPUT.put_line('1、BINARY_FLOAT_MAX_SUBNORMAL = ' || BINARY_FLOAT_MAX_SUBNORMAL) ;
7 DBMS_OUTPUT.put_line('2、BINARY_DOUBLE_MIN_NORMAL = ' || BINARY_DOUBLE_MIN_NORMAL) ;
8 DBMS_OUTPUT.put_line('2、BINARY_DOUBLE_MAX_NORMAL = ' || BINARY_DOUBLE_MAX_NORMAL) ;
9 DBMS_OUTPUT.put_line('2、BINARY_DOUBLE_MIN_SUBNORMAL = ' || BINARY_DOUBLE_MIN_SUBNORMAL) ;
10 DBMS_OUTPUT.put_line('2、BINARY_DOUBLE_MAX_SUBNORMAL = ' || BINARY_DOUBLE_MAX_SUBNORMAL) ;
11 END ;
12 /
1、BINARY_FLOAT_MIN_NORMAL = 1.17549435E-038
1、BINARY_FLOAT_MAX_NORMAL = 3.40282347E+038
1、BINARY_FLOAT_MIN_SUBNORMAL = 1.40129846E-045
1、BINARY_FLOAT_MAX_SUBNORMAL = 1.17549421E-038
2、BINARY_DOUBLE_MIN_NORMAL = 2.2250738585072014E-308
2、BINARY_DOUBLE_MAX_NORMAL = 1.7976931348623157E+308
2、BINARY_DOUBLE_MIN_SUBNORMAL = 4.9406564584124654E-324
2、BINARY_DOUBLE_MAX_SUBNORMAL = 2.2250738585072009E-308
PL/SQL procedure successfully completed.
示例3:超過范圍的計算
SQL> DECLARE
2 BEGIN
3 DBMS_OUTPUT.put_line('超過范圍計算的結果:' ||
4 BINARY_DOUBLE_MAX_NORMAL * BINARY_DOUBLE_MAX_NORMAL) ;
5 DBMS_OUTPUT.put_line('超過范圍計算的結果:' ||
6 BINARY_DOUBLE_MAX_NORMAL / 0) ;
7 END ;
8 /
超過范圍計算的結果:Inf
超過范圍計算的結果:Inf
PL/SQL procedure successfully completed.
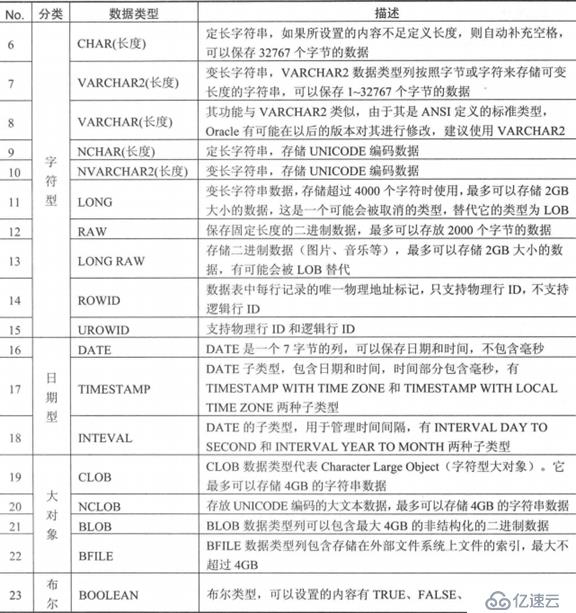
字符型
CHAR與VARCHAR2
說明:
CHAR采用定長方式保存字符串。如果用戶設置的內容不足其定義長度,則會自動補充空格;
VARCHAR2是可變字符串。如果設置的內容不足其長度,也不會為其補充內容;
示例1:觀察CHAR和VARCHAR2的區別
SQL> DECLARE
2 v_info_char CHAR(10) ;
3 v_info_varchar VARCHAR2(10) ;
4 BEGIN
5 v_info_char := 'MLDN' ; -- 長度不足10個
6 v_info_varchar := 'java' ; -- 長度不足10個
7 DBMS_OUTPUT.put_line('v_info_char內容長度:' || LENGTH(v_info_char)) ;
8 DBMS_OUTPUT.put_line('v_info_varchar內容長度:' || LENGTH(v_info_varchar)) ;
9 END ;
10 /
v_info_char內容長度:10
v_info_varchar內容長度:4
PL/SQL procedure successfully completed.
NCHAR和NVARCHAR2
兩者的特性與CHAR,VARCHAR2一樣。區別在于它們保存的數據為UNICODE編碼,中文與英文都會變為十六進制編碼保存;
示例1:驗證NCHAR和NVARCHAR2
SQL> DECLARE
2 v_info_nchar NCHAR(10) ;
3 v_info_nvarchar NVARCHAR2(10) ;
4 BEGIN
5 v_info_nchar := 'CSDN' ; -- 長度不足10個
6 v_info_nvarchar := '高端培訓' ; -- 長度不足10個
7 DBMS_OUTPUT.put_line('v_info_nchar內容長度:' || LENGTH(v_info_nchar)) ;
8 DBMS_OUTPUT.put_line('v_info_nvarchar內容長度:' || LENGTH(v_info_nvarchar)) ;
9 END ;
10 /
v_info_nchar內容長度:10
v_info_nvarchar內容長度:8
PL/SQL procedure successfully completed.
LONG與LONG RAW
兩者用于向后兼容;
LONG說明:
使用LONG的地方都會使用CLOB或NCLOB;
LONG用于存儲字符流;
可以使用"UTL_RAW.cast_to_varchar2(RAW數據)"函數,將RAW轉為字符串
LONG RAW說明:
使用LONG RAW的地方都替換為BLOB或BILE;
LONG RAW用于存儲二進制數據流
為LONG RAW變量設置內容,要使用"UTL_RAW.cast_to_raw(字符串)"進行轉換;
示例1:使用LONG和LONG RAW操作
SQL> set serveroutput on
SQL> DECLARE
2 v_info_long LONG ;
3 v_info_longraw LONG RAW ;
4 BEGIN
5 v_info_long := 'CSDN' ; -- 直接設置字符串
6 v_info_longraw := UTL_RAW.cast_to_raw('高端培訓') ; -- 將字符串變為RAW
7 DBMS_OUTPUT.put_line('v_info_long內容:' || v_info_long) ;
8 DBMS_OUTPUT.put_line('v_info_longraw內容:' || UTL_RAW.cast_to_varchar2(v_info_longraw)) ;
9 END ;
10 /
v_info_long內容:CSDN
v_info_longraw內容:高端培訓
PL/SQL procedure successfully completed.
OWID與UROWID
ROWID表示的是一條數據的物理行地址,由18個字符組合而成,與ROWID偽列功能相同;
UROWID具備ROWID的功能,還增加了一個邏輯行地址,在PL/SQL中應將所有的ROWID交給UROWID管理;
示例1:使用ROWID及UROWID
SQL> create synonym emp for scott.emp@CLONEPDB_PLUG;
Synonym created.
SQL> DECLARE
2 v_emp_rowid ROWID ;
3 v_emp_urowid UROWID ;
4 BEGIN
5 SELECT ROWID INTO v_emp_rowid FROM emp WHERE empno=7369 ; -- 取得ROWID
6 SELECT ROWID INTO v_emp_urowid FROM emp WHERE empno=7369 ; -- 取得ROWID
7 DBMS_OUTPUT.put_line('7369雇員的ROWID = ' || v_emp_rowid) ;
8 DBMS_OUTPUT.put_line('7369雇員的UROWID = ' || v_emp_urowid) ;
9 END ;
10 /
7369雇員的ROWID = AAAR7bAALAAAACTAAA
7369雇員的UROWID = AAAR7bAALAAAACTAAA
PL/SQL procedure successfully completed.
日期型
DATE數據類型
用來存儲日期時間數據;
可通過SYSDATE或SYSTIMESTAMP兩個偽列來獲取當前的日期時間;
主要字段索引:
示例1:定義DATE型變量
SQL> DECLARE
2 v_date1 date := SYSDATE;
3 v_date2 date := systimestamp;
4 v_date3 date :=TO_DATE('2015-01-01','YYYY-MM-DD');
5 BEGIN
6 DBMS_OUTPUT.put_line('日期數據:' || TO_CHAR(v_date1,'yyyy-mm-dd hh34:mi:ss'));
7 DBMS_OUTPUT.put_line('日期數據:' || TO_CHAR(v_date2,'yyyy-mm-dd hh34:mi:ss'));
8 DBMS_OUTPUT.put_line('日期數據:' || TO_CHAR(v_date3,'yyyy-mm-dd hh34:mi:ss'));
9 END;
10 /
日期數據:2017-12-19 15:22:01
日期數據:2017-12-19 15:22:01
日期數據:2015-01-01 00:00:00
PL/SQL procedure successfully completed.
TIMESTAMP數據類型
該類型與DATE的區別在于,可以提供更為準確的時間。但是要使用SYSTIMESTAMP偽列來為其賦值;
如果只是使用SYSDATE,那么TIMESTAMP與DATE沒有任何區別;
示例1:定義TIMESTAMP型變量
SQL> DECLARE
2 v_timestamp1 TIMESTAMP := SYSDATE;
3 v_timestamp2 TIMESTAMP := SYSTIMESTAMP;
4 v_timestamp3 TIMESTAMP := to_timestamp('2011-12-15 10:40:10.345', 'yyyy-MM-dd HH24:MI:ss.ff');
5 BEGIN
6 DBMS_OUTPUT.put_line('日期數據:' || v_timestamp1) ;
7 DBMS_OUTPUT.put_line('日期數據:' || v_timestamp2) ;
8 DBMS_OUTPUT.put_line('日期數據:' || v_timestamp3) ;
9 END ;
10 /
日期數據:19-DEC-17 03.32.31.000000 PM
日期數據:19-DEC-17 03.32.31.988000 PM
日期數據:15-DEC-11 10.40.10.345000 AM
PL/SQL procedure successfully completed.
TIMESTAMP的兩個擴充子類型:
TIMESTAMP WITH TIME ZONE:包含與格林威治時間的時區偏移量
SQL> DECLARE
2 v_timestamp TIMESTAMP WITH TIME ZONE := SYSTIMESTAMP ;
3 BEGIN
4 DBMS_OUTPUT.put_line(v_timestamp) ;
5 END ;
6 /
19-DEC-17 03.36.53.909000 PM +08:00
PL/SQL procedure successfully completed.
TIMESTAMP WITH LOCAL TIME ZONE:不管是何種時區的數據,都使用當前數據庫的時區;
SQL> DECLARE
2 v_timestamp TIMESTAMP WITH LOCAL TIME ZONE := SYSTIMESTAMP ;
3 BEGIN
4 DBMS_OUTPUT.put_line(v_timestamp) ;
5 END ;
6 /
19-DEC-17 03.37.32.894000 PM
PL/SQL procedure successfully completed.
NTERVAL數據類型
該類型可以保存兩個時間戳之間的時間間隔,此類型分為兩個子類型:
INTERVAL YEAR[(年的精度)] TO MONTHS:保存的和操作年與月之間的時間間隔,用戶可以設置年的數據精度。默認值為2;
賦值格式:'年-月'
INTERVAL DAY[(天的精度)] TO SECEND[(秒的精度)]:保存和操作天,時,分,秒之間的時間間隔,默認為2。秒的默認值為6;
賦值格式:'天時:分:秒.毫秒'
當取得時間間隔后,可利用下列公式進行計算: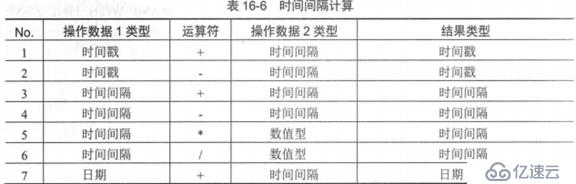
示例1:定義INTERVAL YEAR TO MONTHS類型變量
SQL> DECLARE
2 v_interval INTERVAL YEAR(3) TO MONTH := INTERVAL '27-09' YEAR TO MONTH ;
3 BEGIN
4 DBMS_OUTPUT.put_line('時間間隔:' || v_interval) ;
5 DBMS_OUTPUT.put_line('當前時間戳 + 時間間隔:' || (SYSTIMESTAMP + v_interval)) ;
6 DBMS_OUTPUT.put_line('當前日期 + 時間間隔:' || (SYSDATE + v_interval)) ;
7 END ;
8 /
時間間隔:+027-09
當前時間戳 + 時間間隔:19-SEP-45 03.43.24.742000000 PM +08:00
當前日期 + 時間間隔:2045-09-19 15:43:24
PL/SQL procedure successfully completed.
示例2:定義INTERVAL DAY TO SECOND類型變量
SQL> DECLARE
2 v_interval INTERVAL DAY(6) TO SECOND (3) := INTERVAL '8 18:19:27.367123909' DAY TO SECOND;
3 BEGIN
4 DBMS_OUTPUT.put_line('時間間隔:' || v_interval) ;
5 DBMS_OUTPUT.put_line('當前時間戳 + 時間間隔:' || (SYSTIMESTAMP + v_interval)) ;
6 DBMS_OUTPUT.put_line('當前日期 + 時間間隔:' || (SYSDATE + v_interval)) ;
7 END ;
8 /
時間間隔:+000008 18:19:27.367
當前時間戳 + 時間間隔:28-DEC-17 10.03.46.657000000 AM +08:00
當前日期 + 時間間隔:2017-12-28 10:03:46
PL/SQL procedure successfully completed.
布爾型
該類型保存TRUE,FALSE,NULL
示例1:定義布爾型變量
SQL> DECLARE
2 v_flag BOOLEAN ;
3 BEGIN
4 v_flag := true ;
5 IF v_flag THEN
6 DBMS_OUTPUT.put_line('條件滿足。') ;
7 END IF ;
8 END ;
9 /
條件滿足。
PL/SQL procedure successfully completed.
子類型
在某一標量類型的基礎上定義更多約束,從而創建一個新的類型,這種新類型被稱為子類型;
創建語法:
subtype 子類型名稱 is 父數據類型[(約束)] [not null];
在定義子類型的時候必須設置好父數據類型。父類型可以是Oracle的各種數據類型
示例1:定義NUMBER子類型
SQL> DECLARE
2 SUBTYPE score_subtype IS NUMBER(5,2) NOT NULL ;
3 v_score score_subtype := 99.35 ; --依據score_subtype類型為v_score變量賦值為99.35
4 BEGIN
5 DBMS_OUTPUT.put_line('成績為:' || v_score) ;
6 END ;
7 /
成績為:99.35
PL/SQL procedure successfully completed.
示例2:定義VARCHAR2子類型
SQL> DECLARE
2 SUBTYPE string_subtype IS VARCHAR2(200) ;
3 v_company string_subtype ;--聲明一個子類型為 string_subtype的變量v_company
4 BEGIN
5 v_company := 'test' ;
6 DBMS_OUTPUT.put_line(v_company) ;
7 END ;
8 /
test
PL/SQL procedure successfully completed.
RETURNING子句
SQL> set serveroutput on;
SQL> DECLARE
2 Row_id ROWID;
3 info VARCHAR2(40);
4 BEGIN
5 INSERT INTO dept VALUES (90, '財務室', '海口')
6 RETURNING rowid, dname||':'||to_char(deptno)||':'||loc
7 INTO row_id, info;
8 DBMS_OUTPUT.PUT_LINE('ROWID:'||row_id);
9 DBMS_OUTPUT.PUT_LINE(info);
10 END;
11 /
ROWID:AAAR7ZAALAAAACFAAA
財務室:90:海口
PL/SQL procedure successfully completed.
RETURNING子句用于檢索INSERT語句中所影響的數據行數,當INSERT語句使用VALUES 子句插入數據時,RETURNING 字句還可將列表達式、ROWID和REF值返回到輸出變量中。在使用RETURNING 子句是應注意以下幾點限制:
1.不能與DML語句和遠程對象一起使用;
2.不能檢索LONG 類型信息;
3.當通過視圖向基表中插入數據時,只能與單基表視圖一起使用。
例2. 修改一條記錄并顯示
SQL> DECLARE
2 Row_id ROWID;
3 info VARCHAR2(40);
4 BEGIN
5 UPDATE dept SET deptno=10 WHERE DNAME='ACCOUNTING'
6 RETURNING rowid, dname||':'||to_char(deptno)||':'||loc
7 INTO row_id, info;
8 DBMS_OUTPUT.PUT_LINE('ROWID:'||row_id);
9 DBMS_OUTPUT.PUT_LINE(info);
10 END;
11 /
ROWID:AAAR7ZAALAAAACDAAA
ACCOUNTING:10:NEW YORK
PL/SQL procedure successfully completed.
RETURNING子句用于檢索被修改行的信息。當UPDATE語句修改單行數據時,RETURNING 子句可以檢索被修改行的ROWID和REF值,以及行中被修改列的列表達式,并可將他們存儲到PL/SQL變量或復合變量中;當UPDATE語句修改多行數據時,RETURNING 子句可以將被修改行的ROWID和REF值,以及列表達式值返回到復合變量數組中。在UPDATE中使用RETURNING 子句的限制與INSERT語句中對RETURNING子句的限制相同。
例3.刪除一條記錄并顯示
SQL> DECLARE
2 Row_id ROWID;
3 info VARCHAR2(40);
4 BEGIN
5 DELETE dept WHERE DNAME='OPERATIONS'
6 RETURNING rowid, dname||':'||to_char(deptno)||':'||loc
7 INTO row_id, info;
8 DBMS_OUTPUT.PUT_LINE('ROWID:'||row_id);
9 DBMS_OUTPUT.PUT_LINE(info);
10 END;
11 /
ROWID:AAAR7ZAALAAAACDAAD
OPERATIONS:40:BOSTON
PL/SQL procedure successfully completed.
RETURNING子句用于檢索被刪除行的信息:當DELETE語句刪除單行數據時,RETURNING 子句可以檢索被刪除行的ROWID和REF值,以及被刪除列的列表達式,并可將他們存儲到PL/SQL變量或復合變量中;當DELETE語句刪除多行數據時,RETURNING 子句可以將被刪除行的ROWID和REF值,以及列表達式值返回到復合變量數組中。在DELETE中使用RETURNING 子句的限制與INSERT語句中對RETURNING子句的限制相同。
2.4.2 復合類型
ORACLE 在 PL/SQL 中除了提供象前面介紹的各種類型外,還提供一種稱為復合類型的類型---記錄和表. 2.4.2.1 記錄類型
記錄類型類似于C語言中的結構數據類型,它把邏輯相關的、分離的、基本數據類型的變量組成一個整體存儲起來,它必須包括至少一個標量型或RECORD 數據類型的成員,稱作PL/SQL RECORD 的域(FIELD),其作用是存放互不相同但邏輯相關的信息。在使用記錄數據類型變量時,需要先在聲明部分先定義記錄的組成、記錄的變量,然后在執行部分引用該記錄變量本身或其中的成員。
定義記錄類型語法如下:
TYPE record_name IS RECORD(
v1 data_type1 [NOT NULL] [:= default_value ],
v2 data_type2 [NOT NULL] [:= default_value ],
......
vn data_typen [NOT NULL] [:= default_value ] );
例1 :
SQL> DECLARE
2 TYPE test_rec IS RECORD(
3 Name VARCHAR2(30) NOT NULL := '我的自學',
4 Info VARCHAR2(100));
5 rec_book test_rec;
6 BEGIN
7 rec_book.Info :='Oracle PL/SQL編程;';
8 DBMS_OUTPUT.PUT_LINE(rec_book.Name||' ' ||rec_book.Info);
9 END;
10 /
我的自學 Oracle PL/SQL編程;
PL/SQL procedure successfully completed.
可以用 SELECT語句對記錄變量進行賦值,只要保證記錄字段與查詢結果列表中的字段相配即可。
例2 :
SQL> conn hr/hr@pdbtest
Connected.
SQL> set serveroutput on
SQL> DECLARE
2 --定義與employees表中的這幾個列相同的記錄數據類型
3 TYPE RECORD_TYPE_EMPLOYEES IS RECORD(
4 f_name employees.first_name%TYPE,
5 h_date employees.hire_date%TYPE,
6 j_id employees.job_id%TYPE);
7 --聲明一個該記錄數據類型的記錄變量
8 v_emp_record RECORD_TYPE_EMPLOYEES;
9
10 BEGIN
11 SELECT first_name, hire_date, job_id INTO v_emp_record
12 FROM employees
13 WHERE employee_id = &emp_id;
14
15 DBMS_OUTPUT.PUT_LINE('雇員名稱:'||v_emp_record.f_name
16 ||' 雇傭日期:'||v_emp_record.h_date
17 ||' 崗位:'||v_emp_record.j_id);
18 END;
19 /
Enter value for emp_id: 206
old 13: WHERE employee_id = &emp_id;
new 13: WHERE employee_id = 206;
雇員名稱:William 雇傭日期:2002-06-07 00:00:00 崗位:AC_ACCOUNT
PL/SQL procedure successfully completed.
一個記錄類型的變量只能保存從數據庫中查詢出的一行記錄,若查詢出了多行記錄,就會出現錯誤。
2.4.2.2 數組類型
數據是具有相同數據類型的一組成員的集合。每個成員都有一個唯一的下標,它取決于成員在數組中的位置。在PL/SQL中,數組數據類型是VARRAY。
定義VARRY數據類型語法如下:
TYPE varray_name IS VARRAY(size) OF element_type [NOT NULL];
varray_name是VARRAY數據類型的名稱,size是下整數,表示可容納的成員的最大數量,每個成員的數據類型是element_type。默認成員可以取空值,否則需要使用NOT NULL加以限制。對于VARRAY數據類型來說,必須經過三個步驟,分別是:定義、聲明、初始化。
例1 :
SQL> DECLARE
2 --定義一個最多保存5個VARCHAR(25)數據類型成員的VARRAY數據類型
3 TYPE reg_varray_type IS VARRAY(5) OF VARCHAR(25);
4 --聲明一個該VARRAY數據類型的變量
5 v_reg_varray REG_VARRAY_TYPE;
6
7 BEGIN
8 --用構造函數語法賦予初值
9 v_reg_varray := reg_varray_type
10 ('中國', '美國', '英國', '日本', '法國');
11
12 DBMS_OUTPUT.PUT_LINE('地區名稱:'||v_reg_varray(1)||'、'
13 ||v_reg_varray(2)||'、'
14 ||v_reg_varray(3)||'、'
15 ||v_reg_varray(4));
16 DBMS_OUTPUT.PUT_LINE('賦予初值NULL的第5個成員的值:'||v_reg_varray(5));
17 --用構造函數語法賦予初值后就可以這樣對成員賦值
18 v_reg_varray(5) := '法國';
19 DBMS_OUTPUT.PUT_LINE('第5個成員的值:'||v_reg_varray(5));
20 END;
21 /
地區名稱:中國、美國、英國、日本
賦予初值NULL的第5個成員的值:法國
第5個成員的值:法國
PL/SQL procedure successfully completed.
2.4.2.3 使用%TYPE
定義一個變量,其數據類型與已經定義的某個數據變量(尤其是表的某一列)的數據類型相一致,這時可以使用%TYPE。
使用%TYPE特性的優點在于:
l 所引用的數據庫列的數據類型可以不必知道;
l 所引用的數據庫列的數據類型可以實時改變,容易保持一致,也不用修改PL/SQL程序。
例1:
SQL> conn scott/tiger@clonepdb_plug
Connected.
SQL> set serveroutput on
SQL> DECLARE
2 -- 用%TYPE 類型定義與表相配的字段
3 TYPE T_Record IS RECORD(
4 T_no emp.empno%TYPE,
5 T_name emp.ename%TYPE,
6 T_sal emp.sal%TYPE );
7 -- 聲明接收數據的變量
8 v_emp T_Record;
9 BEGIN
10 SELECT empno, ename, sal INTO v_emp FROM emp WHERE empno=7782;
11 DBMS_OUTPUT.PUT_LINE
12 (TO_CHAR(v_emp.t_no)||' '||v_emp.t_name||' ' || TO_CHAR(v_emp.t_sal));
13 END;
14 /
7782 CLARK 2450
PL/SQL procedure successfully completed.
例2:
SQL> DECLARE
2 v_empno emp.empno%TYPE :=&no;
3 Type t_record is record (
4 v_name emp.ename%TYPE,
5 v_sal emp.sal%TYPE,
6 v_date emp.hiredate%TYPE);
7 Rec t_record;
8 BEGIN
9 SELECT ename, sal, hiredate INTO Rec FROM emp WHERE empno=v_empno;
10 DBMS_OUTPUT.PUT_LINE(Rec.v_name||'---'||Rec.v_sal||'--'||Rec.v_date);
11 END;
12 /
Enter value for no: 7782
old 2: v_empno emp.empno%TYPE :=&no;
new 2: v_empno emp.empno%TYPE :=7782;
CLARK---2450--1981-06-09 00:00:00
PL/SQL procedure successfully completed.
2.4.3 使用%ROWTYPE
PL/SQL 提供%ROWTYPE操作符, 返回一個記錄類型, 其數據類型和數據庫表的數據結構相一致。
使用%ROWTYPE特性的優點在于:
l 所引用的數據庫中列的個數和數據類型可以不必知道;
l 所引用的數據庫中列的個數和數據類型可以實時改變,容易保持一致,也不用修改PL/SQL程序。
例1:
SQL> DECLARE
2 v_empno emp.empno%TYPE :=&no;
3 rec emp%ROWTYPE;
4 BEGIN
5 SELECT * INTO rec FROM emp WHERE empno=v_empno;
6 DBMS_OUTPUT.PUT_LINE('姓名:'||rec.ename||'工資:'||rec.sal||'工作時間:'||rec.hiredate);
7 END;
8 /
Enter value for no: 7782
old 2: v_empno emp.empno%TYPE :=&no;
new 2: v_empno emp.empno%TYPE :=7782;
姓名:CLARK工資:2450工作時間:1981-06-09 00:00:00
PL/SQL procedure successfully completed.
2.4.4 LOB類型
ORACLE提供了LOB (Large OBject)類型,用于存儲大的數據對象的類型。ORACLE目前主要支持BFILE, BLOB, CLOB 及 NCLOB 類型。
BFILE (Movie)
存放大的二進制數據對象,這些數據文件不放在數據庫里,而是放在操作系統的某個目錄里,數據庫的表里只存放文件的目錄。 BLOB(Photo)
存儲大的二進制數據類型。變量存儲大的二進制對象的位置。大二進制對象的大小<=4GB。 CLOB(Book)
存儲大的字符數據類型。每個變量存儲大字符對象的位置,該位置指到大字符數據塊。大字符對象的大小<=4GB。 NCLOB
存儲大的NCHAR字符數據類型。每個變量存儲大字符對象的位置,該位置指到大字符數據塊。大字符對象的大小<=4GB。 2.4.5 BIND 變量
綁定變量是在主機環境中定義的變量。在PL/SQL 程序中可以使用綁定變量作為他們將要使用的其它變量。為了在PL/SQL 環境中聲明綁定變量,使用命令VARIABLE。例如:
VARIABLE return_code NUMBER
VARIABLE return_msg VARCHAR2(20)
可以通過SQLPlus命令中的PRINT 顯示綁定變量的值。例如:
PRINT return_code
PRINT return_msg
例1:
SQL> VARIABLE result NUMBER;
SQL> BEGIN
2 SELECT (sal10)+nvl(comm, 0) INTO :result FROM emp
3 WHERE empno=7844;
4 END;
5 /
PL/SQL procedure successfully completed.
SQL> --然后再執行
SQL> PRINT result
RESULT 150002.4.6 PL/SQL 表(TABLE)
定義記錄表(或索引表)數據類型。它與記錄類型相似,但它是對記錄類型的擴展。它可以處理多行記錄,類似于高級中的二維數組,使得可以在PL/SQL中模仿數據庫中的表。
定義記錄表類型的語法如下:
TYPE table_name IS TABLE OF element_type [NOT NULL]
INDEX BY [BINARY_INTEGER | PLS_INTEGER | VARRAY2];
關鍵字INDEX BY表示創建一個主鍵索引,以便引用記錄表變量中的特定行。 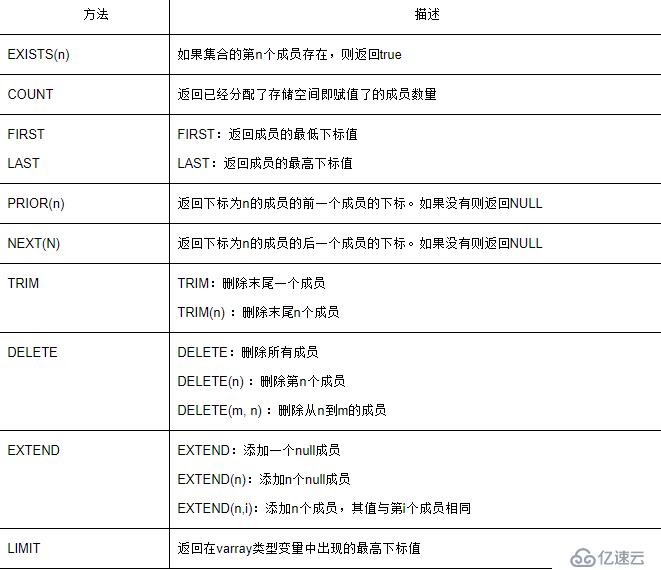
例1:
SQL> DECLARE
2 TYPE dept_table_type IS TABLE OF
3 dept%ROWTYPE INDEX BY BINARY_INTEGER;
4 my_dname_table dept_table_type;
5 v_count number(2) :=3;
6 BEGIN
7 FOR int IN 1 .. v_count LOOP
8 SELECT INTO my_dname_table(int) FROM dept WHERE deptno=int10;
9 END LOOP;
10 FOR int IN my_dname_table.FIRST .. my_dname_table.LAST LOOP
11 DBMS_OUTPUT.PUT_LINE('Department number: '||my_dname_table(int).deptno);
12 DBMS_OUTPUT.PUT_LINE('Department name: '|| my_dname_table(int).dname);
13 END LOOP;
14 END;
15 /
Department number: 10
Department name: ACCOUNTING
Department number: 20
Department name: RESEARCH
Department number: 30
Department name: SALES
PL/SQL procedure successfully completed.
例2:按一維數組使用記錄表
SQL> DECLARE
2 --定義記錄表數據類型
3 TYPE reg_table_type IS TABLE OF varchar2(25)
4 INDEX BY BINARY_INTEGER;
5 --聲明記錄表數據類型的變量
6 v_reg_table REG_TABLE_TYPE;
7
8 BEGIN
9 v_reg_table(1) := 'Europe';
10 v_reg_table(2) := 'Americas';
11 v_reg_table(3) := 'Asia';
12 v_reg_table(4) := 'Middle East and Africa';
13 v_reg_table(5) := 'NULL';
14
15 DBMS_OUTPUT.PUT_LINE('地區名稱:'||v_reg_table (1)||'、'
16 ||v_reg_table (2)||'、'
17 ||v_reg_table (3)||'、'
18 ||v_reg_table (4));
19 DBMS_OUTPUT.PUT_LINE('第5個成員的值:'||v_reg_table(5));
20 END;
21 /
地區名稱:Europe、Americas、Asia、Middle East and Africa
第5個成員的值:NULL
PL/SQL procedure successfully completed
例3:按二維數組使用記錄表
SQL> conn hr/hr@pdbtest
Connected.
SQL> set serveroutput on
SQL> DECLARE
2 --定義記錄表數據類型
3 TYPE emp_table_type IS TABLE OF employees%ROWTYPE
4 INDEX BY BINARY_INTEGER;
5 --聲明記錄表數據類型的變量
6 v_emp_table EMP_TABLE_TYPE;
7 BEGIN
8 SELECT first_name, hire_date, job_id INTO
9 v_emp_table(1).first_name,v_emp_table(1).hire_date, v_emp_table(1).job_id
10 FROM employees WHERE employee_id = 177;
11 SELECT first_name, hire_date, job_id INTO
12 v_emp_table(2).first_name,v_emp_table(2).hire_date, v_emp_table(2).job_id
13 FROM employees WHERE employee_id = 178;
14
15 DBMS_OUTPUT.PUT_LINE('177雇員名稱:'||v_emp_table(1).first_name
16 ||' 雇傭日期:'||v_emp_table(1).hire_date
17 ||' 崗位:'||v_emp_table(1).job_id);
18 DBMS_OUTPUT.PUT_LINE('178雇員名稱:'||v_emp_table(2).first_name
19 ||' 雇傭日期:'||v_emp_table(2).hire_date
20 ||' 崗位:'||v_emp_table(2).job_id);
21 END;
22 /
177雇員名稱:Jack 雇傭日期:2006-04-23 00:00:00 崗位:SA_REP
178雇員名稱:Kimberely 雇傭日期:2007-05-24 00:00:00 崗位:SA_REP
PL/SQL procedure successfully completed.
2.5 運算符和表達式(數據定義)
2.5.1 關系運算符 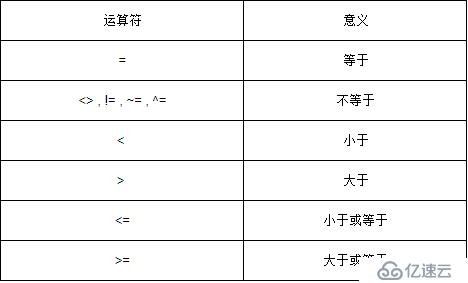
2.5.2 一般運算符 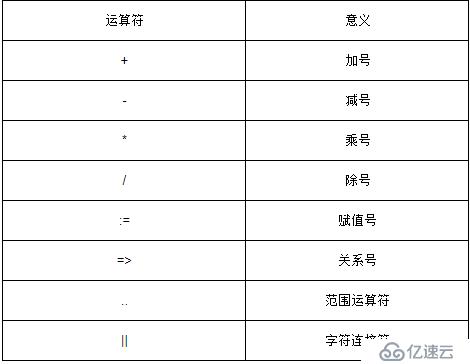
2.5.3 邏輯運算符 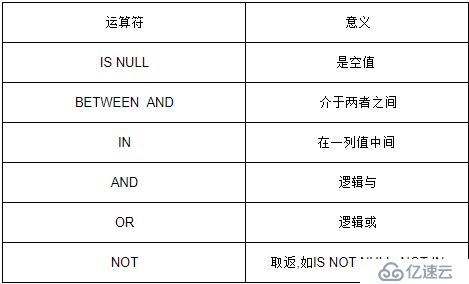
2.6 變量賦值
在PL/SQL編程中,變量賦值是一個值得注意的地方,它的語法如下:
variable := expression ;
variable 是一個PL/SQL變量, expression 是一個PL/SQL 表達式.
2.6.1 字符及數字運算特點
空值加數字仍是空值:NULL + < 數字> = NULL
空值加(連接)字符,結果為字符:NULL || <字符串> = < 字符串>
2.6.2 BOOLEAN 賦值
布爾值只有TRUE, FALSE及 NULL 三個值。
2.6.3 數據庫賦值
數據庫賦值是通過 SELECT語句來完成的,每次執行 SELECT語句就賦值一次,一般要求被賦值的變量與SELECT中的列名要一一對應。如:
例1:
SQL> DECLARE
2 emp_id emp.empno%TYPE :=7782;
3 emp_name emp.ename%TYPE;
4 wages emp.sal%TYPE;
5 BEGIN
6 SELECT ename, NVL(sal,0) + NVL(comm,0) INTO emp_name, wages
7 FROM emp WHERE empno = emp_id;
8 DBMS_OUTPUT.PUT_LINE(emp_name||'----'||to_char(wages));
9 END;
10 /
CLARK----2450
PL/SQL procedure successfully completed.
提示:不能將SELECT語句中的列賦值給布爾變量。
2.6.4 可轉換的類型賦值
l CHAR 轉換為 NUMBER:
使用 TO_NUMBER 函數來完成字符到數字的轉換,如:
v_total := TO_NUMBER('100.0') + sal;
l NUMBER 轉換為CHAR:
使用 TO_CHAR函數可以實現數字到字符的轉換,如:v_comm := TO_CHAR('123.45') || '元' ;
l 字符轉換為日期:
使用 TO_DATE函數可以實現 字符到日期的轉換,如:
v_date := TO_DATE('2001.07.03','yyyy.mm.dd');
l 日期轉換為字符
使用 TO_CHAR函數可以實現日期到字符的轉換,如:
v_to_day := TO_CHAR(SYSDATE, 'yyyy.mm.dd hh34:mi:ss') ;
2.7 變量作用范圍及可見性
在PL/SQL編程中,如果在變量的定義上沒有做到統一的話,可能會隱藏一些危險的錯誤,這樣的原因主要是變量的作用范圍所致。變量的作用域是指變量的有效作用范圍,與其它高級語言類似,PL/SQL的變量作用范圍特點是:
l 變量的作用范圍是在你所引用的程序單元(塊、子程序、包)內。即從聲明變量開始到該塊的結束。
l 一個變量(標識)只能在你所引用的塊內是可見的。
l 當一個變量超出了作用范圍,PL/SQL引擎就釋放用來存放該變量的空間(因為它可能不用了)。
l 在子塊中重新定義該變量后,它的作用僅在該塊內。
例1:
SQL> DECLARE
2 Emess char(80);
3 BEGIN
4
5 DECLARE
6 V1 NUMBER(4);
7 BEGIN
8 SELECT empno INTO v1 FROM emp WHERE LOWER(job)='president';
9 DBMS_OUTPUT.PUT_LINE(V1);
10 EXCEPTION
11 When TOO_MANY_ROWS THEN
12 DBMS_OUTPUT.PUT_LINE ('More than one president');
13 END;
14
15 DECLARE
16 V1 NUMBER(4);
17 BEGIN
18 SELECT empno INTO v1 FROM emp WHERE LOWER(job)='manager';
19 EXCEPTION
20 When TOO_MANY_ROWS THEN
21 DBMS_OUTPUT.PUT_LINE ('More than one manager');
22 END;
23
24 EXCEPTION
25 When others THEN
26 Emess:=substr(SQLERRM,1,80);
27 DBMS_OUTPUT.PUT_LINE(emess);
28 END;
29 /
7839
More than one manager
PL/SQL procedure successfully completed.
2.8 注釋
在PL/SQL里,可以使用兩種符號來寫注釋,即:l 使用雙 ‘-‘ ( 減號) 加注釋
PL/SQL允許用 – 來寫注釋,它的作用范圍是只能在一行有效。如:
V_Sal NUMBER(12,2); -- 人員的工資變量。
l 使用 / / 來加一行或多行注釋,如:
//
/ 文件名: /
/ 作 者: /
/ 時 間: /
//
提示:被解釋后存放在數據庫中的 PL/SQL 程序,一般系統自動將程序頭部的注釋去掉。只有在 PROCEDURE 之后的注釋才被保留;另外程序中的空行也自動被去掉。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





