溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“服務器中分布式系統緩存的特征是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
說到分布式系統基本上就離不開緩存,在高并發,大流量的場景下緩存更是扮演著重要的角色。所以作為一個分布式系統的開發人員是必須熟練掌握緩存的使用與設計。下面是一張簡單的系統架構圖
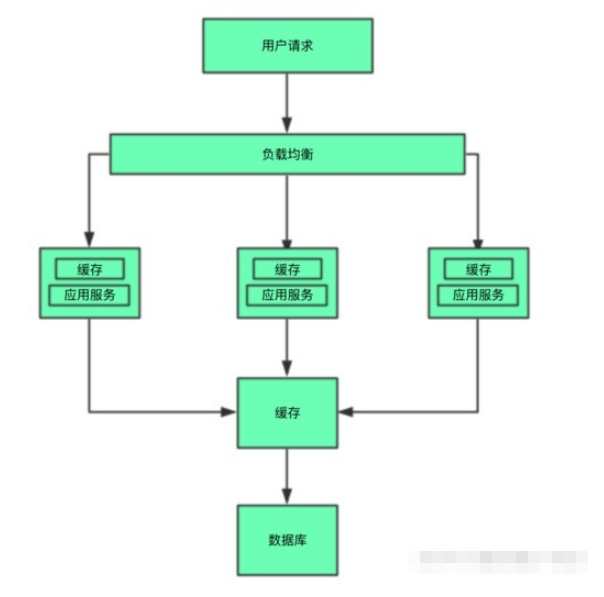
從圖中我們知道了緩存在系統層面的所處位置,可以在應用系統的內部也可以在外部。那緩存的意義又是什么呢?
1、縮短系統的響應時間,提升用戶體驗。如果在系統的內部就已經緩存有了用戶請求所需要的結果,那么就不在需要執行其后面操作如外部RPC,DB查詢,直接返回結果,給用戶流暢般的系統體驗。
2、扛住更大的流量,保護關鍵系統組件。舉個例子在高并發,大流量的場景下如果沒有緩存的保護,所有的請求的都直接穿透到我們底層的DB。DB基本上都是扛不住的,DB一旦宕機基本上整個系統就over了,但很多緩存中間件比如redis,memcache卻可以扛得住。
3、提升系統穩定性,提高整體吞吐量。第三點其實由前面兩點總結出來的。
根據緩存的存儲情況可以分為:集中式緩存,本地緩存,分布式緩存。
集中式緩存:所有的緩存都統一在一個地方管理。
優點:數據集中容易管理,一致性好,實時性好,只要修改一處地方可以立即看到效果。
缺點:集中式緩存通常都存放在系統的外部,高并發請求下帶寬很容易成為瓶頸。
優化:減少不必要的數據,只存儲真正需要的數據。對放進緩存的數據進行壓縮,取出來之后再進行解壓。目的都是為了減少數據傳輸對帶完的占用。
本地緩存:又叫localCache,每個應用的本地都留著一份完整的緩存副本。
優點:性能好,相對于集中式緩存不需要訪問外部并且沒有帶寬的壓力。
缺點:數據分散,不容易管理。數據一致性差,多個副本之間數據同步有延時。
優化:必須給本地緩存加上一個過期失效時間,并且建立一套相對實時數據更新機制,保證副本的數據能夠有效及時更新。
分布式緩存:以集群的方式搭建緩存,比如redis集群。
優點:高性能,支持動態擴展,支持高可用
分布式緩存集群都是以分片的形式數據分散到多臺機器上面去存儲,分片的形式有客戶端分片(memcahed),服務端分片(redis),分片用的hash算法通常采用一致性hash。這一塊涉及的內容比較多,有時間的話后面打算專門獨立討論。
緩存也是一個數據模型對象,那么必然有它的一些特征:
命中率=返回正確結果數/請求緩存次數,命中率問題是緩存中的一個非常重要的問題,它是衡量緩存有效性的重要指標。命中率越高,表明緩存的使用率越高。
緩存中可以存放的最大元素的數量,一旦緩存中元素數量超過這個值(或者緩存數據所占空間超過其最大支持空間),那么將會觸發緩存啟動清空策略根據不同的場景合理的設置最大元素值往往可以一定程度上提高緩存的命中率,從而更有效的時候緩存。
如上描述,緩存的存儲空間有限制,當緩存空間被用滿時,如何保證在穩定服務的同時有效提升命中率?這就由緩存清空策略來處理,設計適合自身數據特征的清空策略能有效提升命中率。常見的一般策略有:
FIFO(first in first out)
先進先出策略,最先進入緩存的數據在緩存空間不夠的情況下(超出最大元素限制)會被優先被清除掉,以騰出新的空間接受新的數據。策略算法主要比較緩存元素的創建時間。在數據實效性要求場景下可選擇該類策略,優先保障最新數據可用。
LFU(less frequently used)
最少使用策略,無論是否過期,根據元素的被使用次數判斷,清除使用次數較少的元素釋放空間。策略算法主要比較元素的hitCount(命中次數)。在保證高頻數據有效性場景下,可選擇這類策略。
LRU(least recently used)
最近最少使用策略,無論是否過期,根據元素最后一次被使用的時間戳,清除最遠使用時間戳的元素釋放空間。策略算法主要比較元素最近一次被get使用時間。在熱點數據場景下較適用,優先保證熱點數據的有效性。
除此之外,還有一些簡單策略比如:
根據過期時間判斷,清理過期時間最長的元素;
根據過期時間判斷,清理最近要過期的元素;
隨機清理;
根據關鍵字(或元素內容)長短清理等。
“服務器中分布式系統緩存的特征是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





