溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
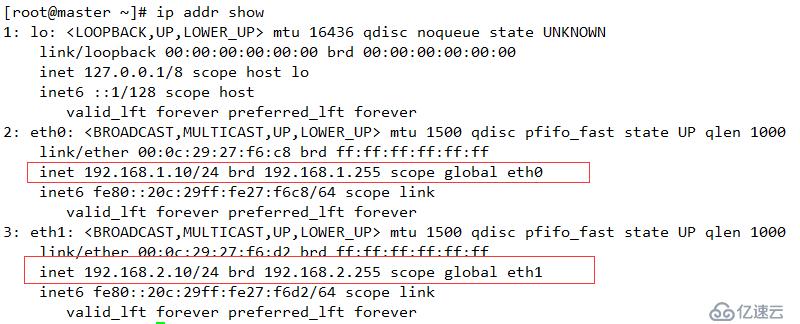
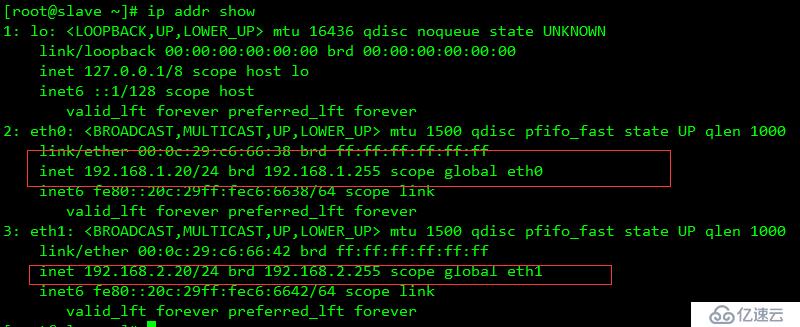
| 主機名 | 網卡 | 磁盤 |
|---|---|---|
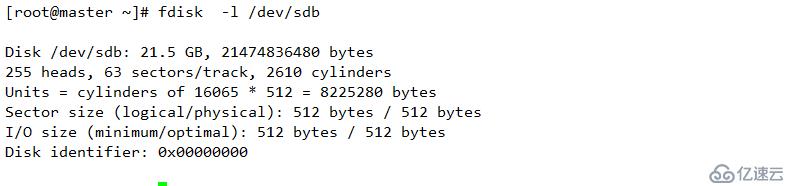
| master | eth0 橋接模式 eth0(192.168.1.10) 自定義模式(VMnet2)(192.168.2.10)VIP 192.168.1.200/210 | 系統盤+20G外接磁盤 |
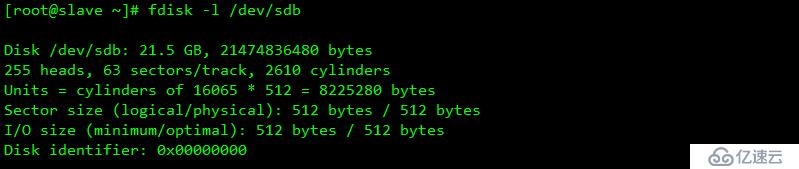
| slave | eth0 橋接模式(192.168.1.20) eth2 自定義模式(VMnet2)(192.168.2.20)VIP 192.168.1.200/210 | 系統盤+20G外接磁盤 |
| server3 | eth0 橋接模式 (192.168.1.30) | 系統盤 |
master 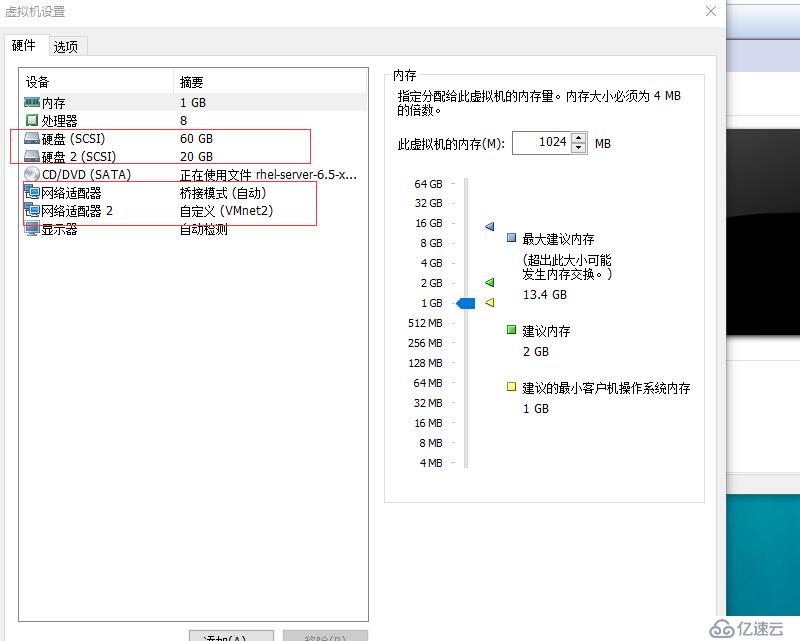
slave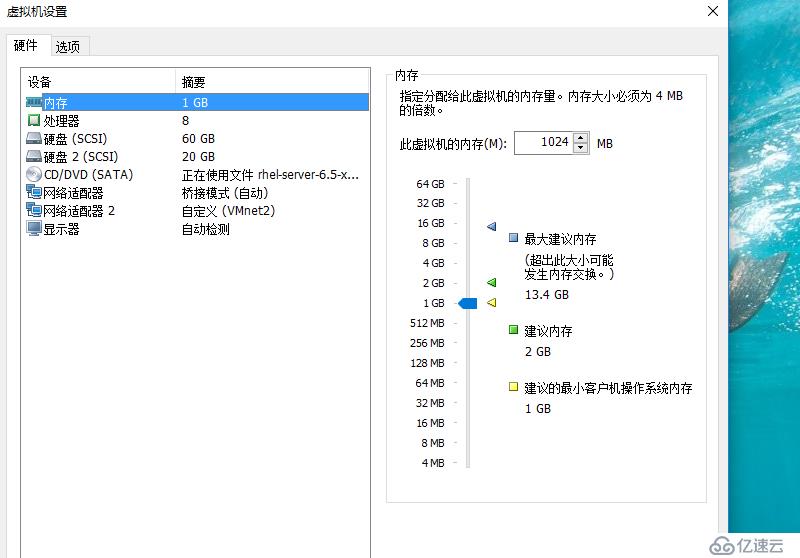
server3 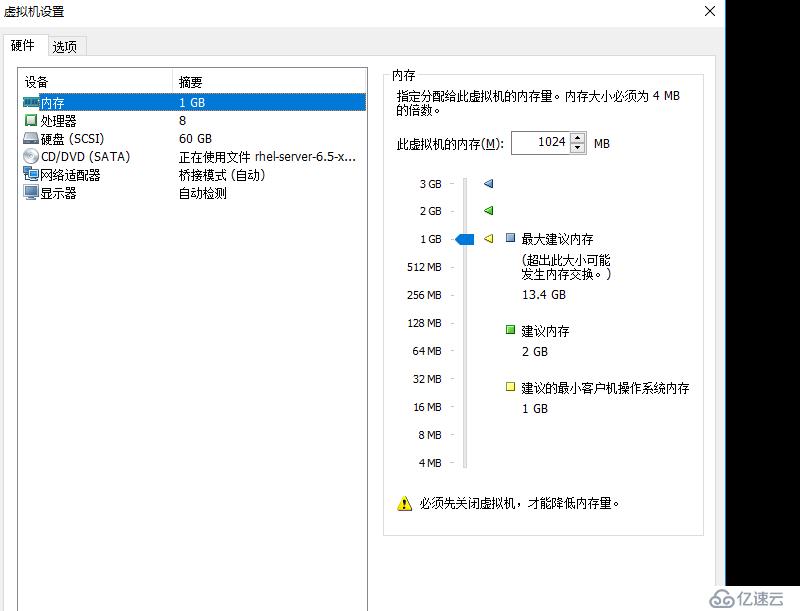
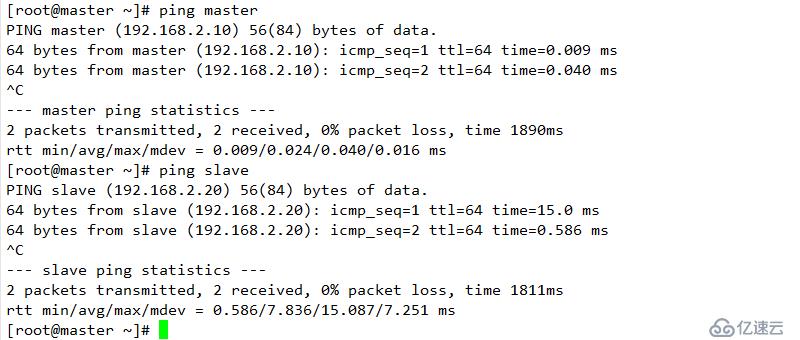


鏈接:https://pan.baidu.com/s/1W2-jeaK_tc-abvSZzmRaiw
提取碼:4evz
drbd 是工作在文件系統之下,是基于塊的遷移
drbd的遷移
文件系統------buffer-cache--------網卡傳遞到另一端------裸設備-----drbd寫入磁盤
drbd 數據分為兩部分,數據存儲部分和元數據部分。
協議A:本地寫成功后就返回給客戶端。
協議B:半同步的協議,本地寫成功,發送到對端后立即返回,
協議C:發送到對端,并成功寫入并進行緩存。
1 單主模式,及主備模式,為典型的高可用性幾圈方案
2 復主模式,需要采用共享cluster文件系統,如GFS和OCFS2
當一端在運行時另一端是不可見的
兩端配置基本相同
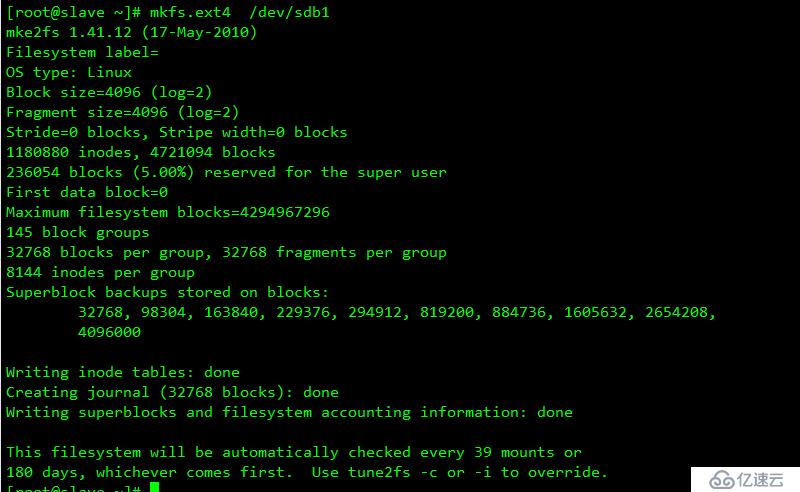
/dev/sdb1 為數據區域
/dev/sdb2 為元數據區域 
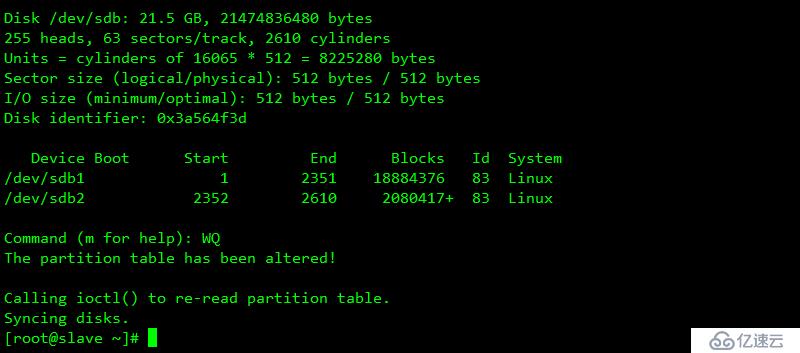
元數據區域不能格式化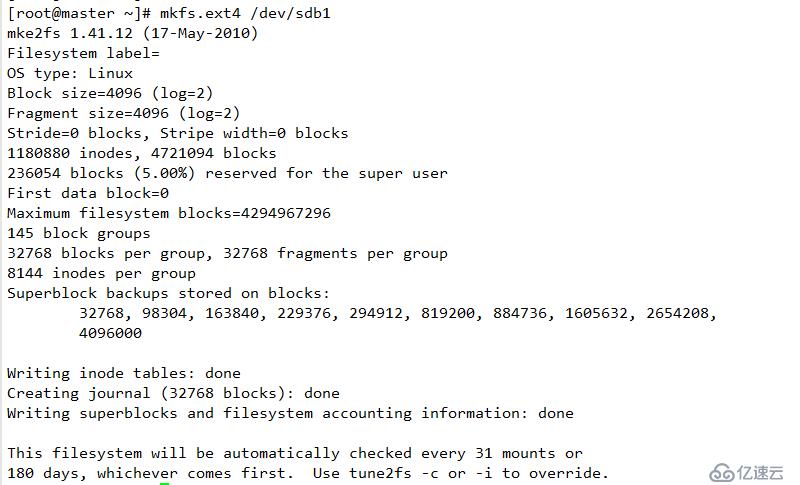
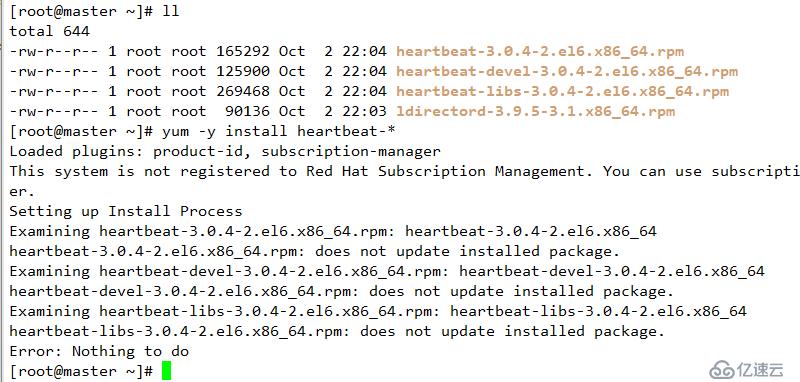
A 解決依賴 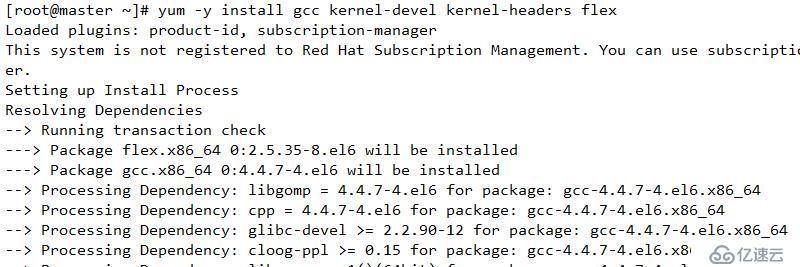
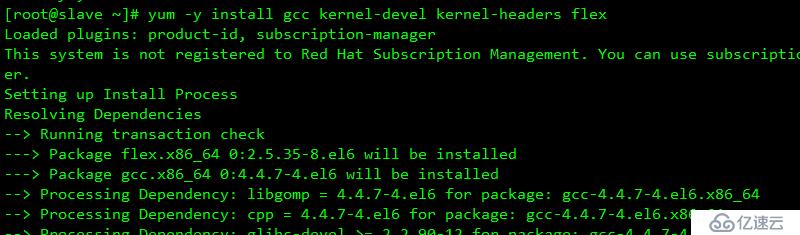
yum -y install gcc kernel-devel kernel-headers flex
B 編譯并安裝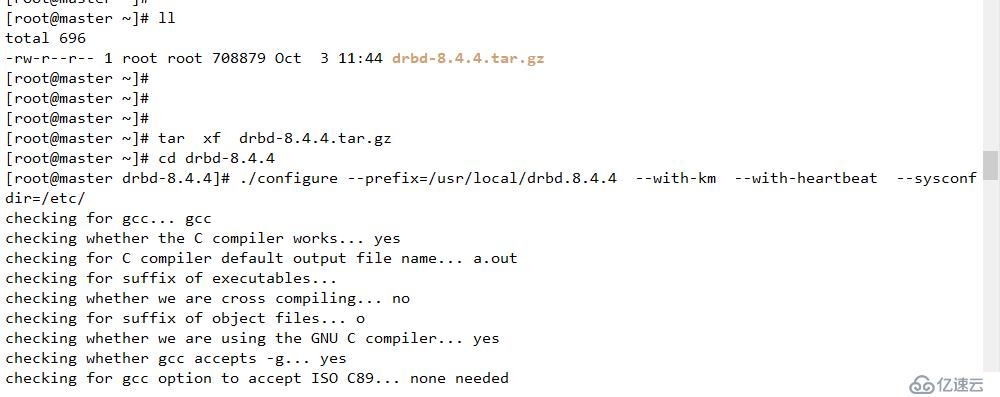
./configure --prefix=/usr/local/drbd.8.4.4 --with-km --with-heartbeat --sysconfdir=/etc/
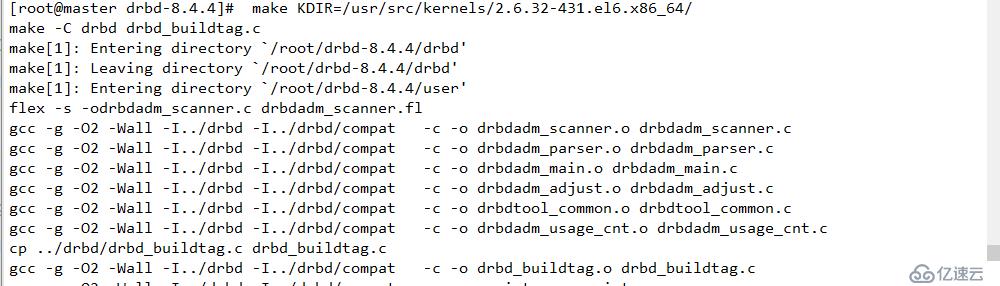
make KDIR=/usr/src/kernels/2.6.32-431.el6.x86_64/
此處必須是自己uname -r 得到的內核,不一定是上面的內核
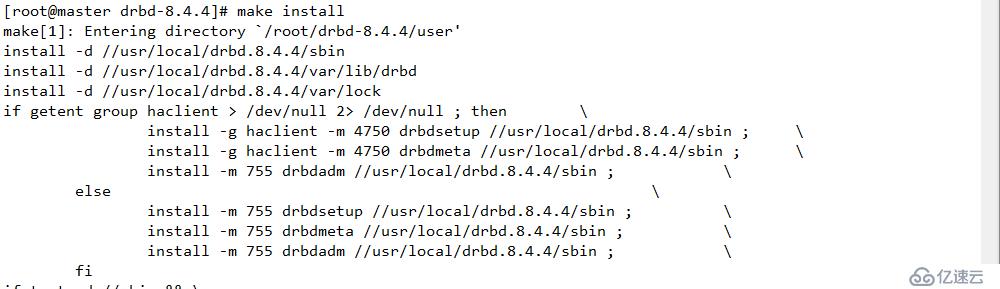
make install
檢驗
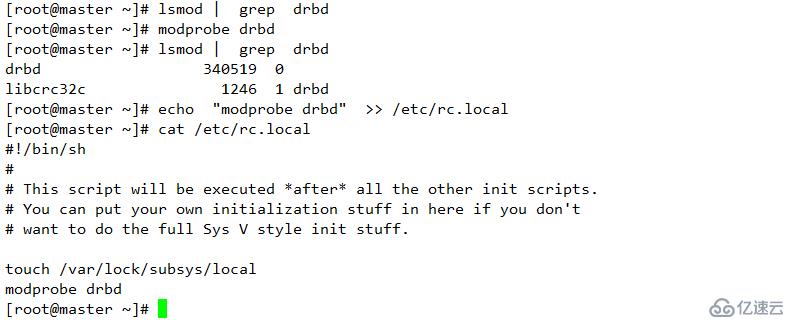
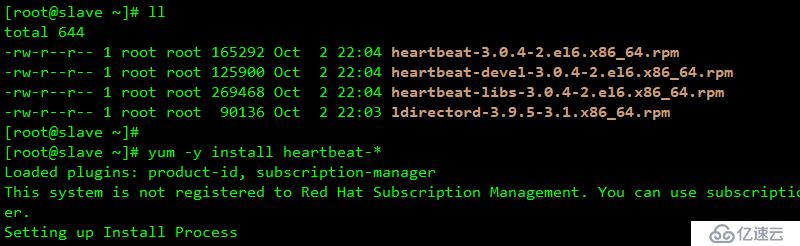
slave 端加載 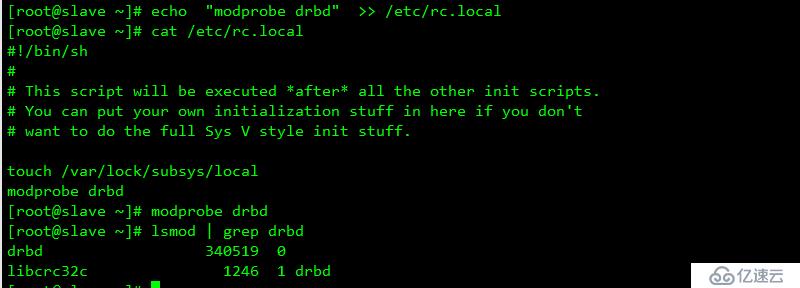

slave 端相同 
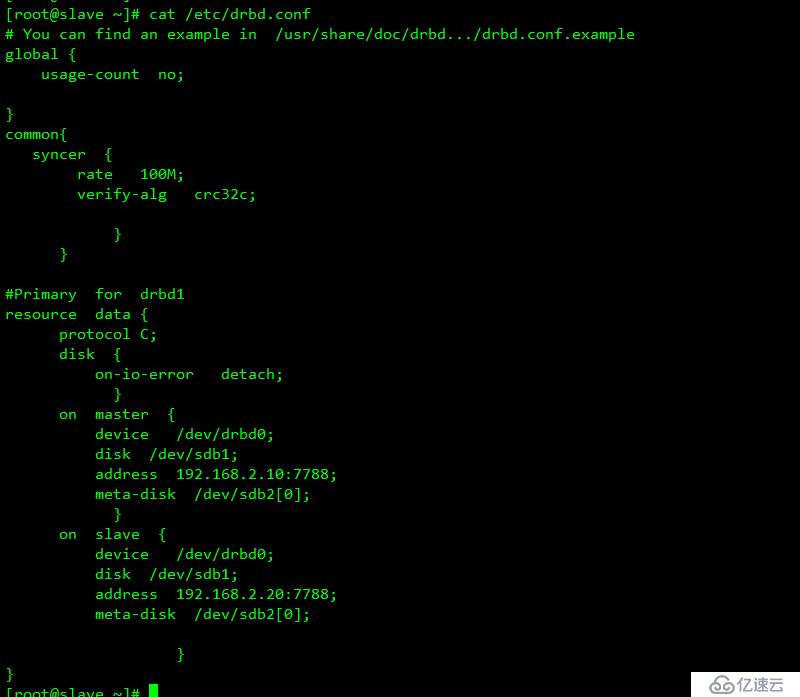
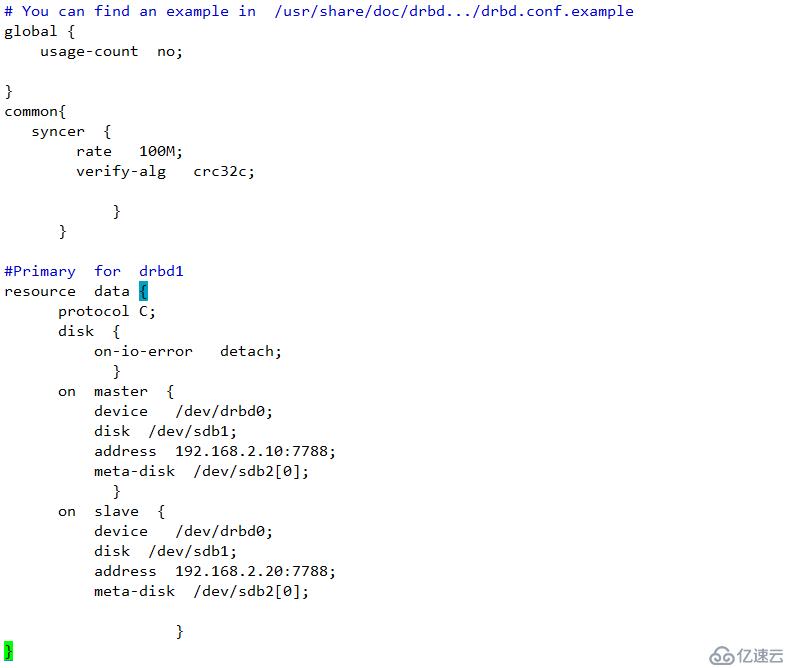
相關解釋
global {
usage-count no;}
common{
syncer {
rate 100M; #同步占用的帶寬
verify-alg crc32c; # 驗證使用的算法} }#Primary for drbd1
resource data{
protocol C; # drbd使用的協議
disk {
on-io-error detach; #出現IO錯誤的處理方式
}
on master {
device /dev/drbd0; #drbd的設備
disk /dev/sdb1; #對應的數據分區
address 192.168.1.10:7788; #地址是監聽自己心跳的IP地址
meta-disk /dev/sdb2[0]; #元數據位置
}
on slave {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.1.20:7788;
meta-disk /dev/sdb2[0];
}}


其中data是上述資源的名稱。




查看啟動參數

相關參數解釋:
注意:只有主備兩邊的DRBD都啟動起來才會生效
cs:鏈接狀態
ro:角色信息,此時的狀態為Secondary/Secondary,表示兩臺主機的狀態都是備機狀態
ds:磁盤狀態,Inconsistent/Inconsistent顯示的狀態內容“不一致”,這是因為DRBD無法判斷哪一方為主機,應以哪一方的磁盤數據作為標準
dw:磁盤寫操作
dr: 磁盤讀操作
ns: 網絡發送
nr: 網絡接受
如果主動端的NS和slave端的NR相同表示發送與接受同步 。
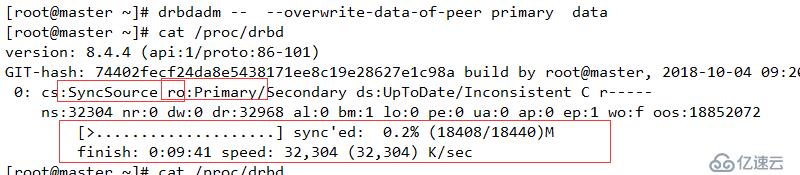
查看同步情況

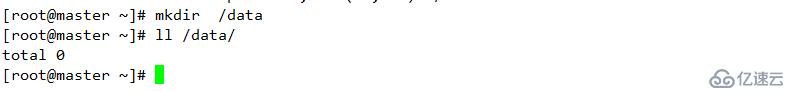

掛載同步測試 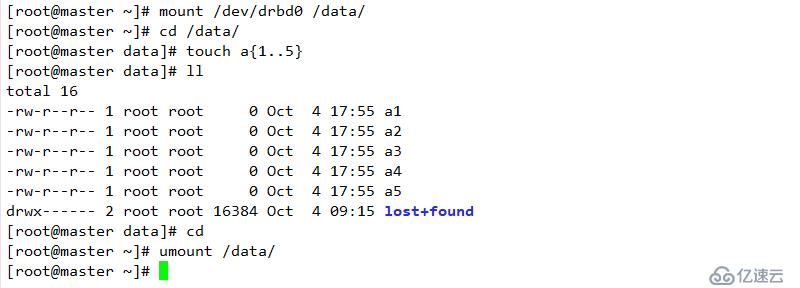

從端測試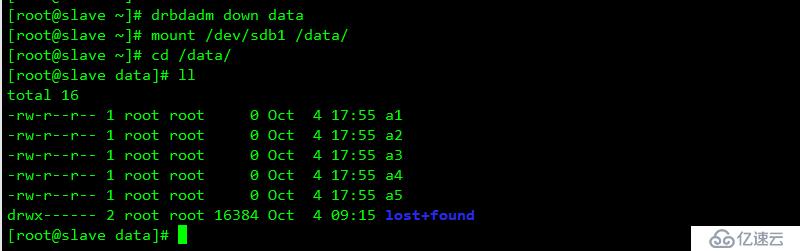
恢復 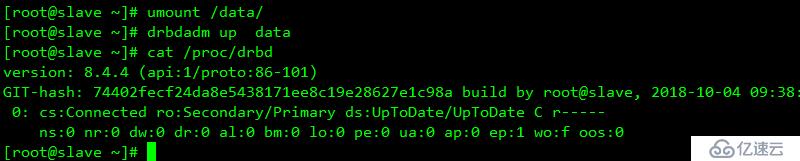
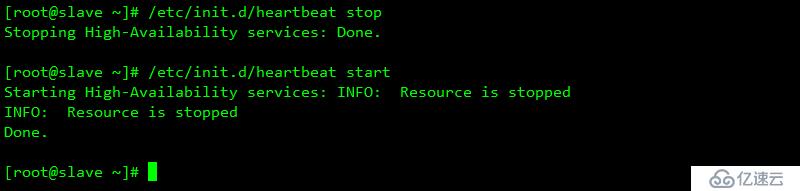
通過heartbeat 可以進行故障轉移并提供相關的服務
在故障轉移期間也需要切換時間,常見的時間是5-20秒左右。但是能夠確保業務一致性
heartbeat的高可用是服務器級別的,不是服務級別的。,服務的down機不會導致服務的切換。
1 服務器down機
2 heartbeat 服務本身down機
3 心跳鏈接線down機
Heartbeat 高可用軟件在工作過程中,一般來說,有三種消息類型,具體為:
1 心跳消息
越150字節,可能為單播,廣播或組播,控制心跳頻率及出現故障要等待多久進行故障轉換2 集群轉換消息
Ip-request 和 ip-request-resp
當主服務器恢復在線狀態后,通過ip-request消息請求備機釋放主服務器失敗時被服務器取得的資源,然后備份服務器關閉釋放主服務器失敗時取得的資源及服務。被服務器釋放主服務器失敗時取得的資源服務后,就會通過ip-request-resp消息通知主服務器他不再擁有該服務器的資源及服務,主服務器收到來自被節點的ip-request-resp消息通知后,啟動失敗時釋放的資源及服務,并開始提供正常的訪問服務。
3 重傳請求
rexmit-request 控制重傳心跳請求。
以上心跳控制消息都使用功能的是UDP協議發送到/etc/ha.d/ha.cf 文件制定的任意接口,或指定的多播地址。
Heartbeat 是通過IP地址接管和ARP廣播進行故障轉移
ARP 廣播在主服務器故障時,備用節點接管資后,會立即強制更新所有客戶端本地的ARP(及清除客戶端本地緩存的失敗服務器的VIP和MAC地址的解析記錄),確保客戶端和新的主服務器之間的對話
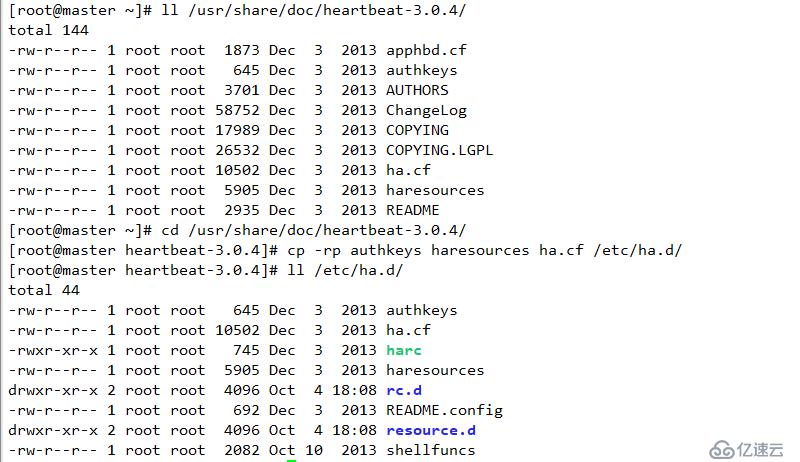
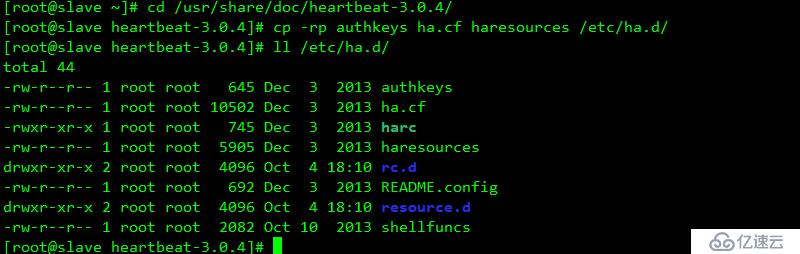
配置密鑰并配置其權限為600,必須為600
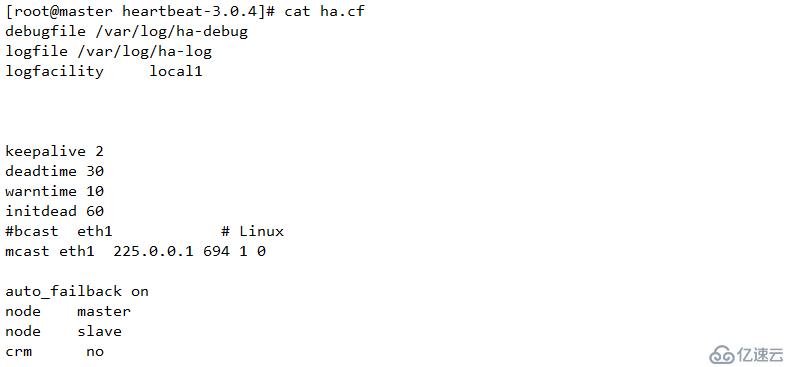
配置文件解析
Debugfile 調試日志存放位置Logfile 日志存放位置
Logfacility local 在syslog 服務中配置通過locally 設備接受日志
Keepalive2 指定心跳間隔時間為2秒
Deadtime 30 指定若備用節點在30秒內沒有接受達到主節點的心跳信號,則立即接管主節點的服務資源
Warntime 10 指定心跳延遲為10秒。當10秒內備份節點不能接受到主節點的心跳信號時,會向日志中寫入一個警告日志,但此時不會切換服務
Initdead 120 指定在heartbeat 首次運行后,需要等待120秒才啟動主服務器的資源,該選項用于解決這種情況產生的時間間隔,取值至少為deadtime的兩倍,單機啟動時會遇到VIP綁定很慢,為正常現象
Bcast eth2 指明心跳使用以太網廣播方式在eth2接口上進行廣播,如使用兩個實際網絡來傳遞心跳則 bcast eth0 eth2
Mcast eht2 225.0.0.1 694 1 0 設置廣播通信使用的端口,694為默認使用的端口,一個是 TTL
Auto_failback on 用來定義當主節點恢復后,是否將服務自動切回
Node master 主節點主機名,
Node slave 備用節點主機名
Crm no 是否開啟cluster resource manager (集群資源管理器)

復制到被動端

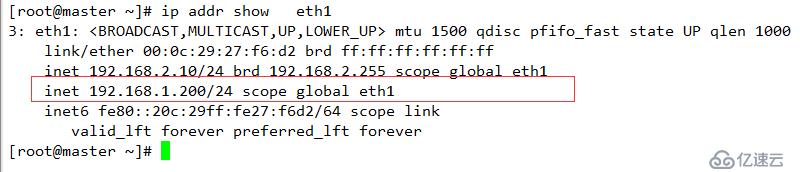

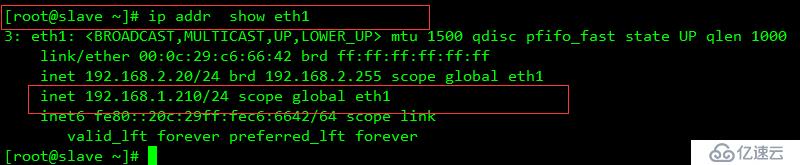


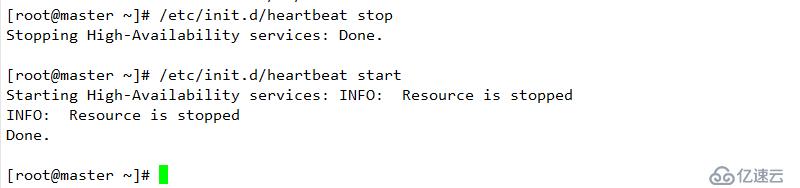
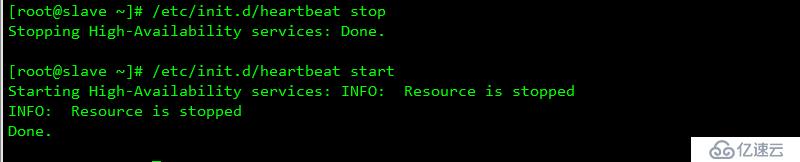
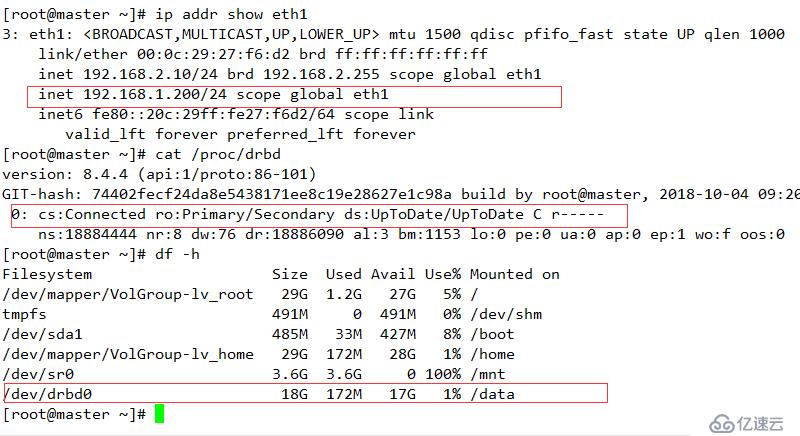
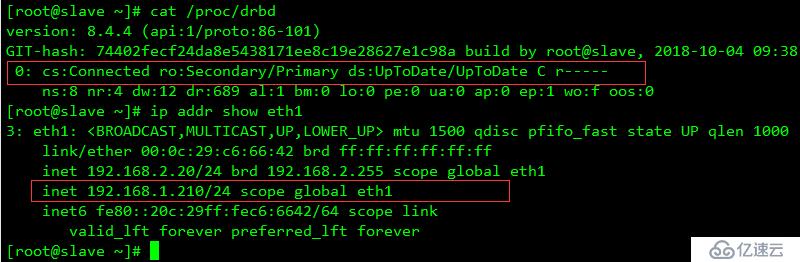
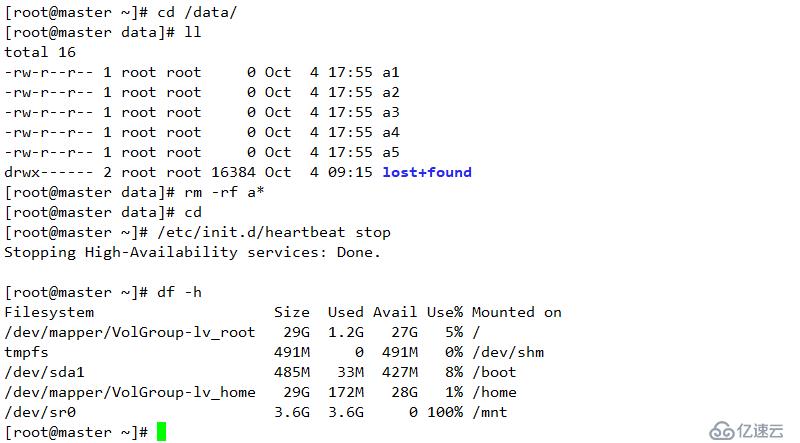
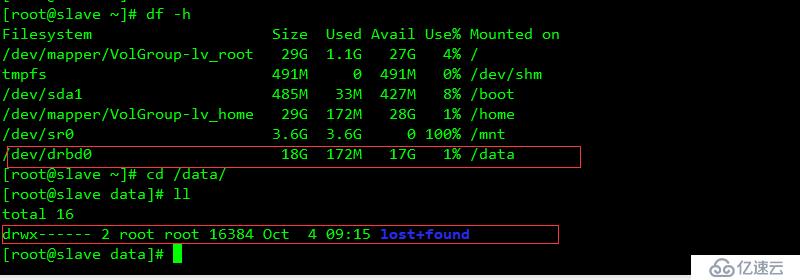




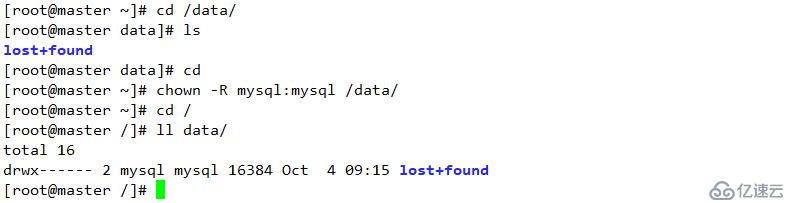
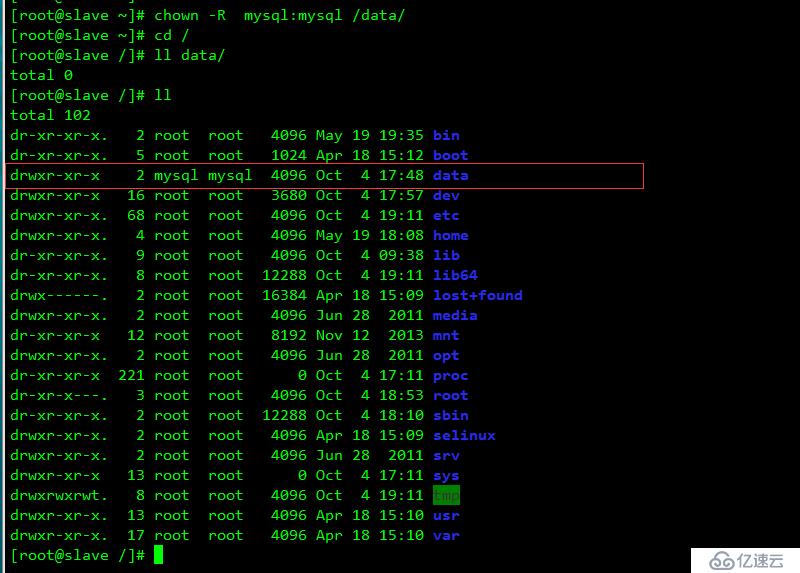

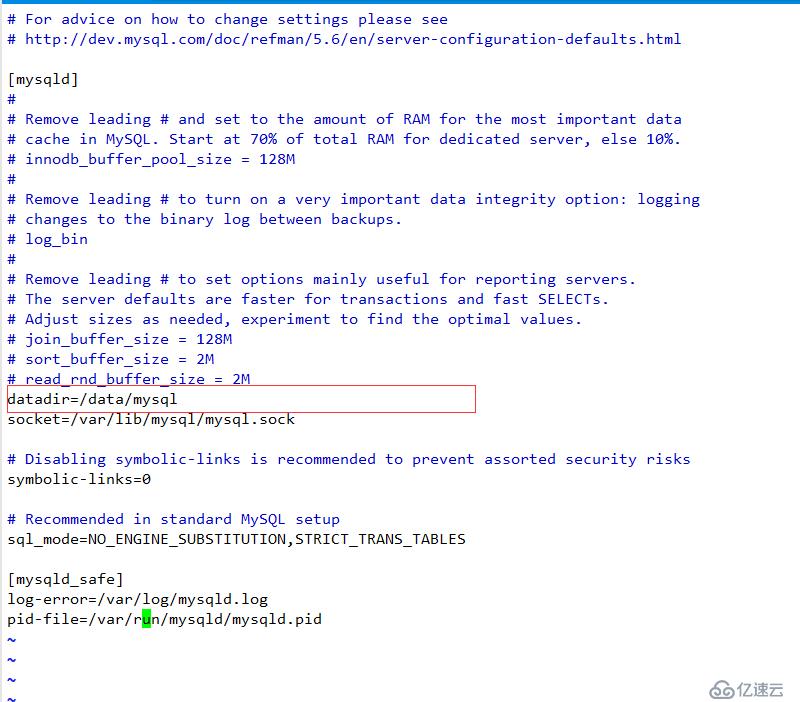

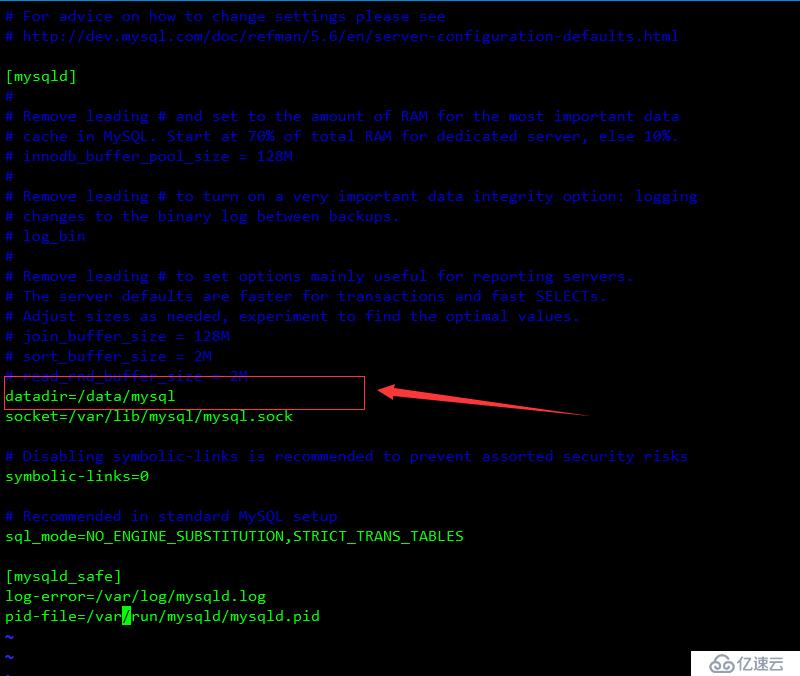
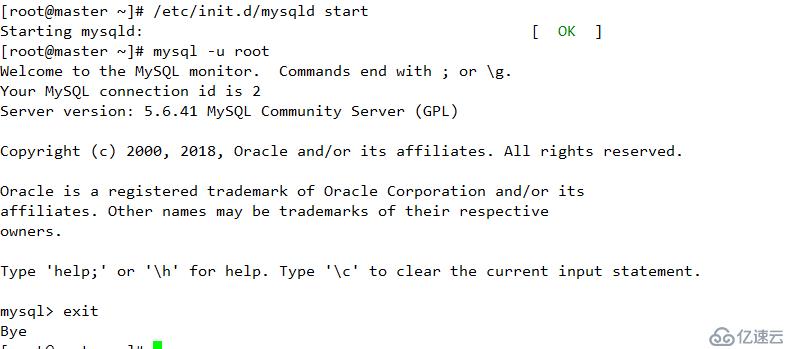
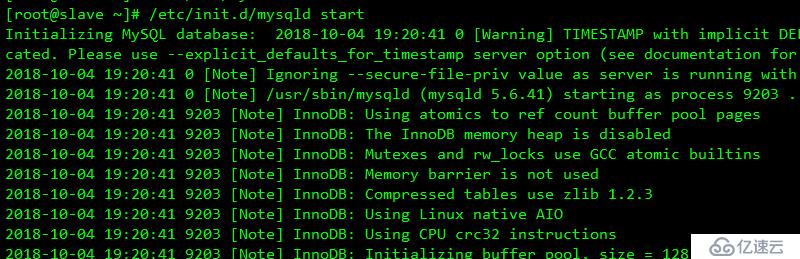
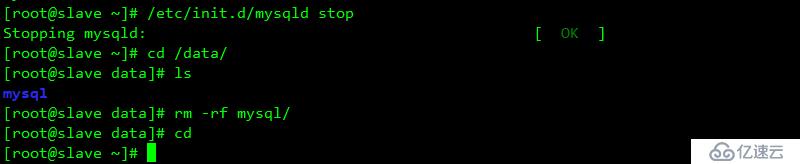
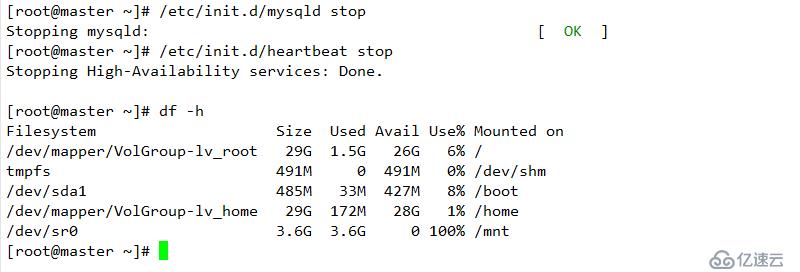
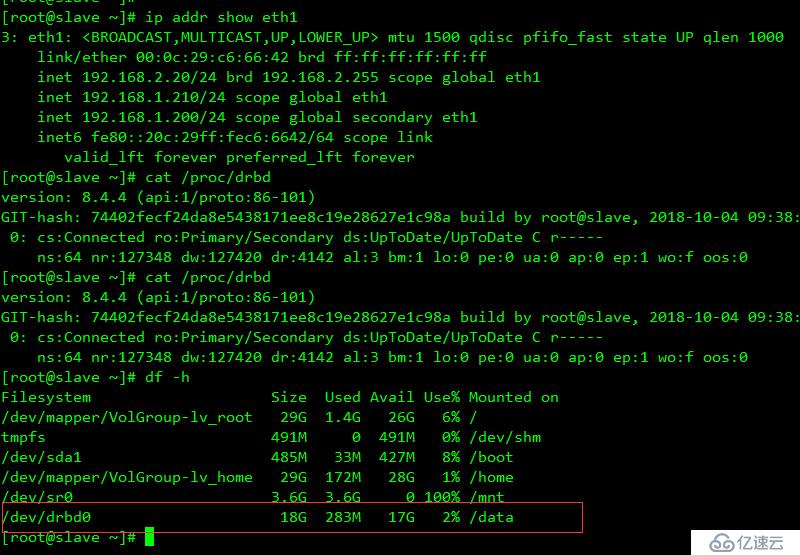
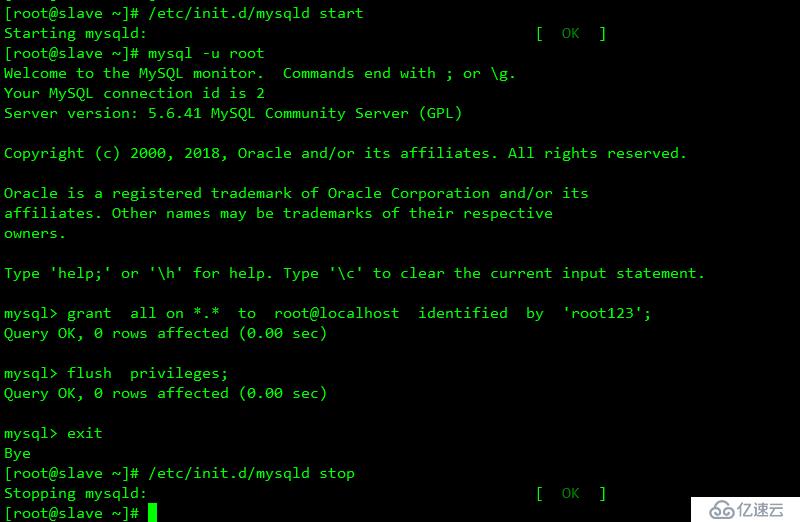
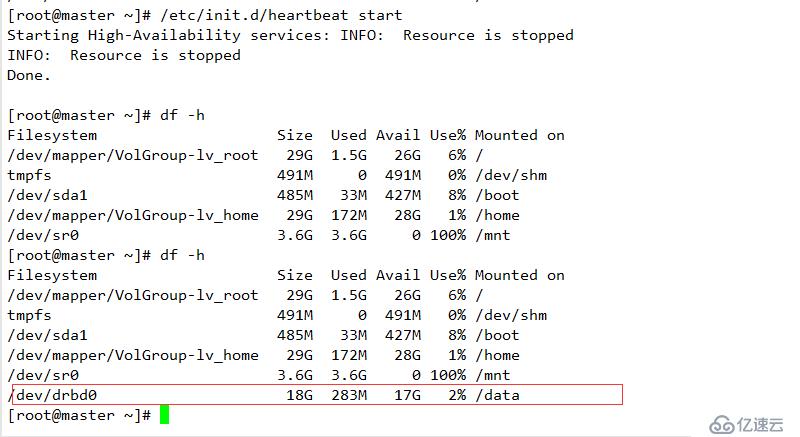
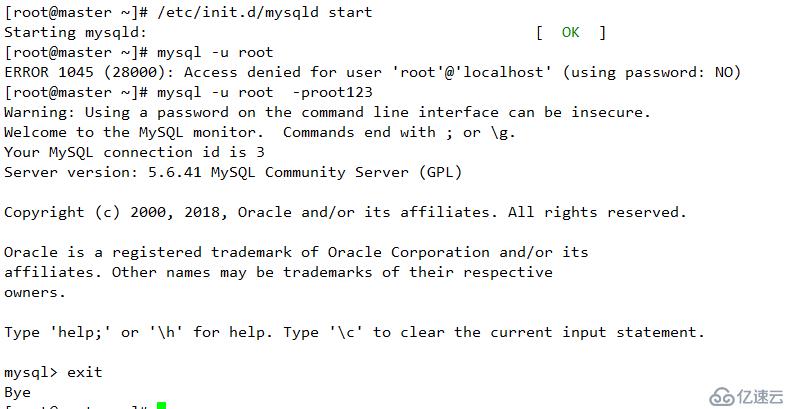




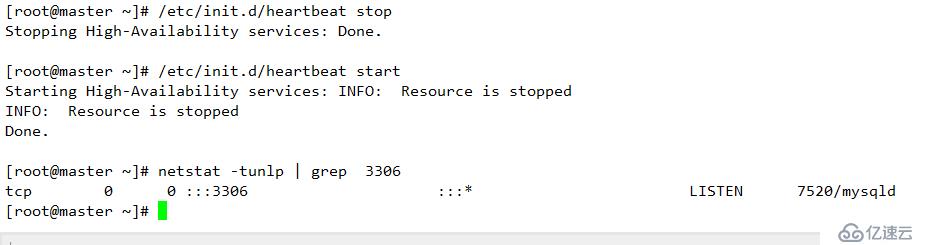





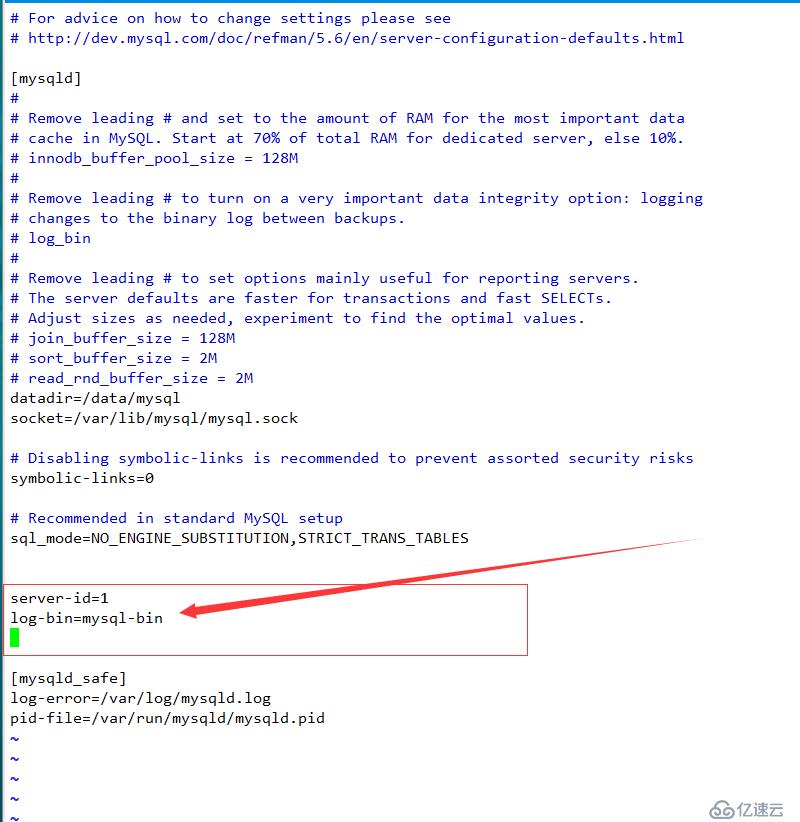

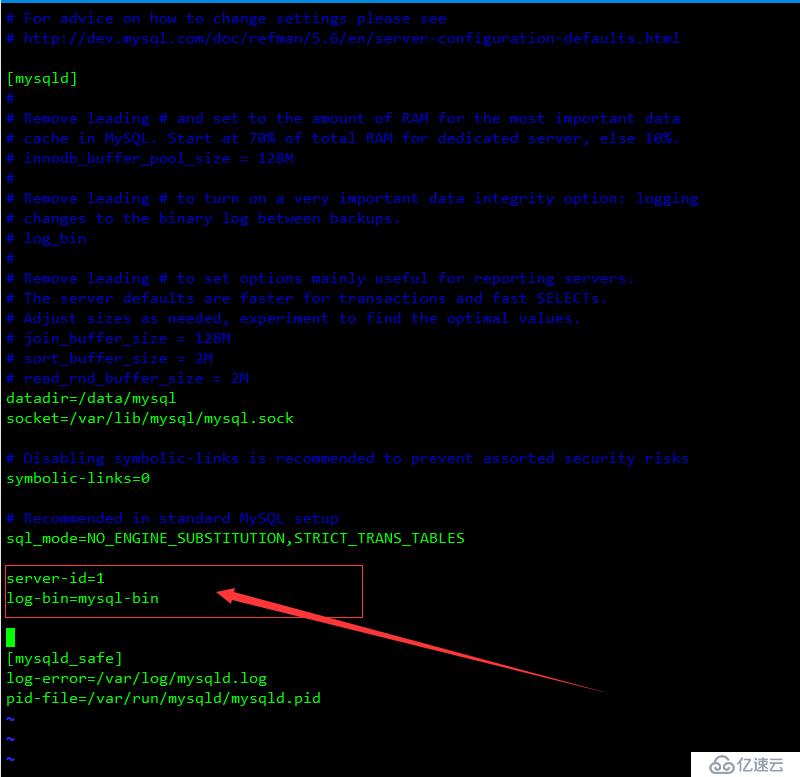

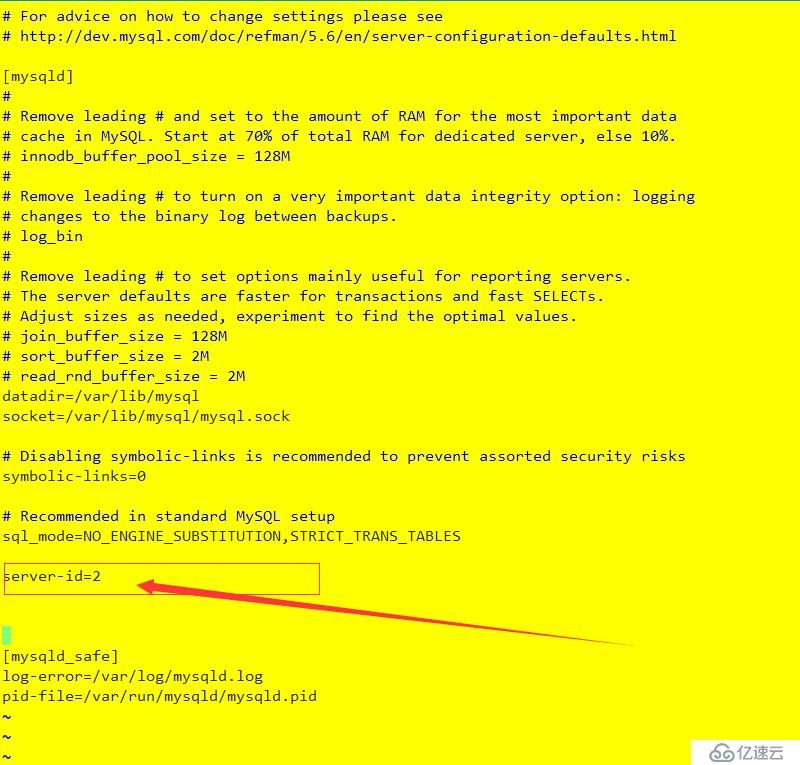

重啟服務器 
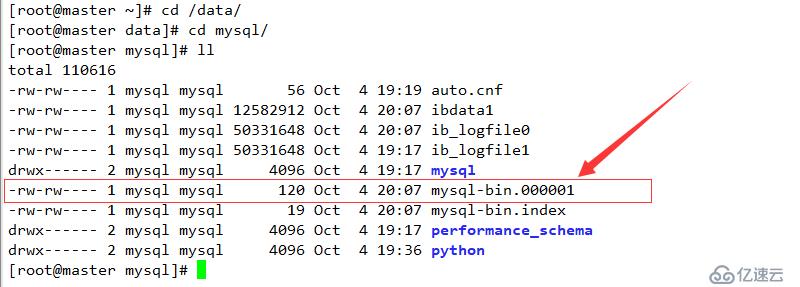
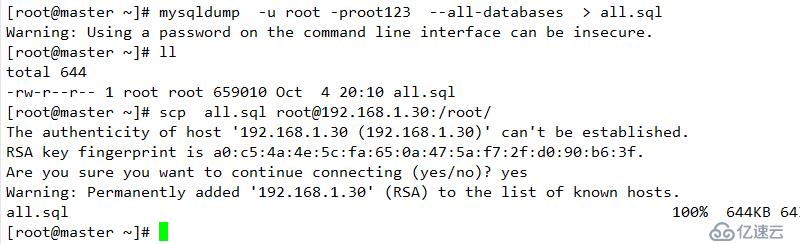
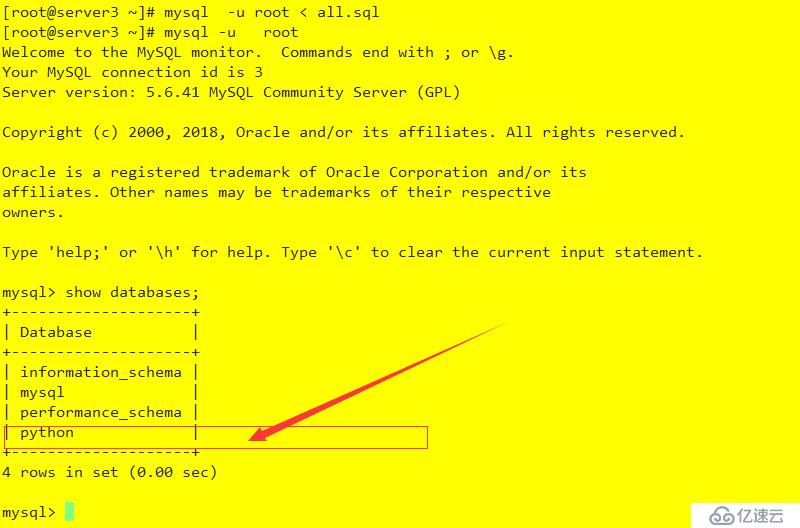
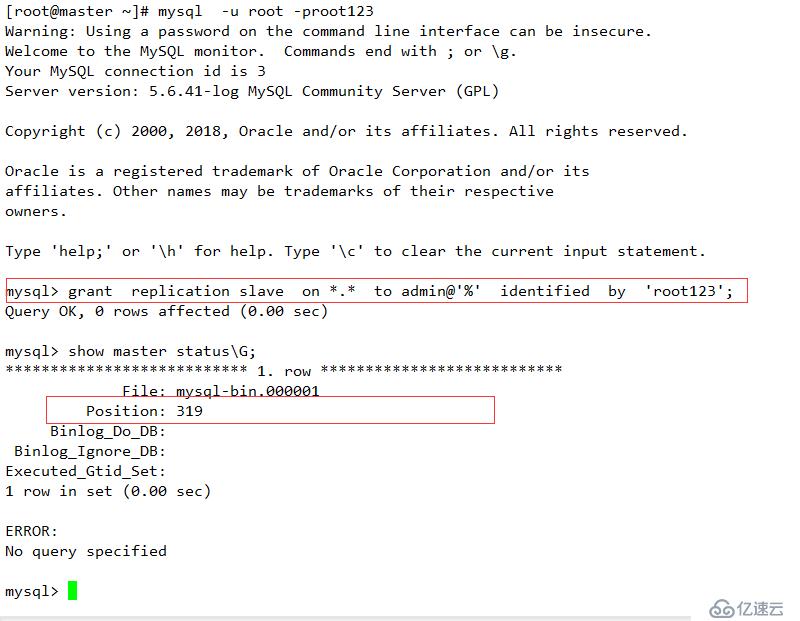
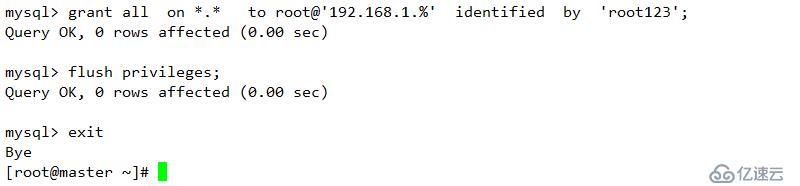
grant replication slave on . to admin@'%' identified by 'root123';
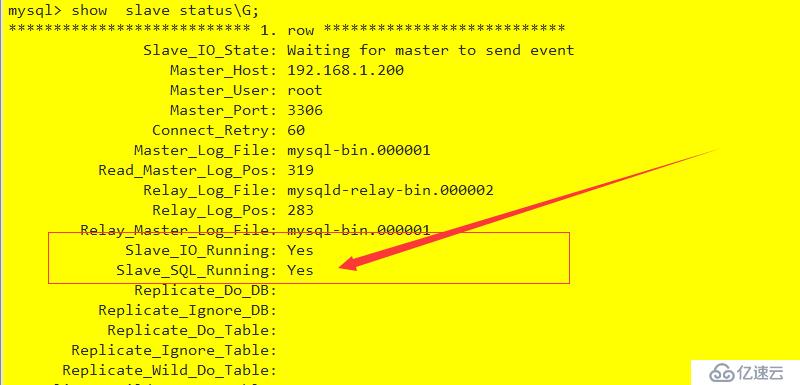
change master to master_host='192.168.1.200',master_user='root',master_password='root123',master_log_file='mysql-bin.000001',master_log_pos=319;
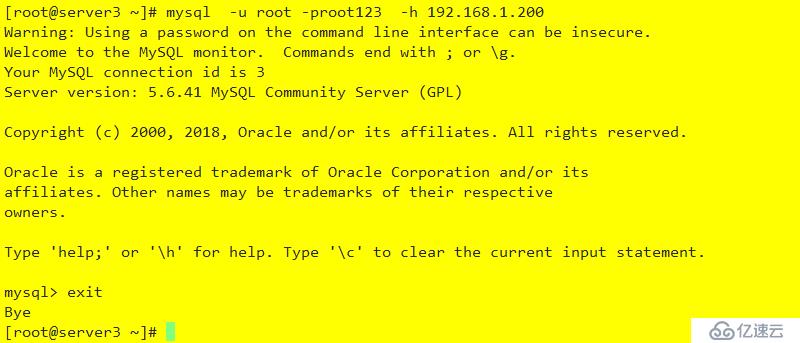
此 192.168.1.200為heartbeat 的VIP,專用于數據鏈接
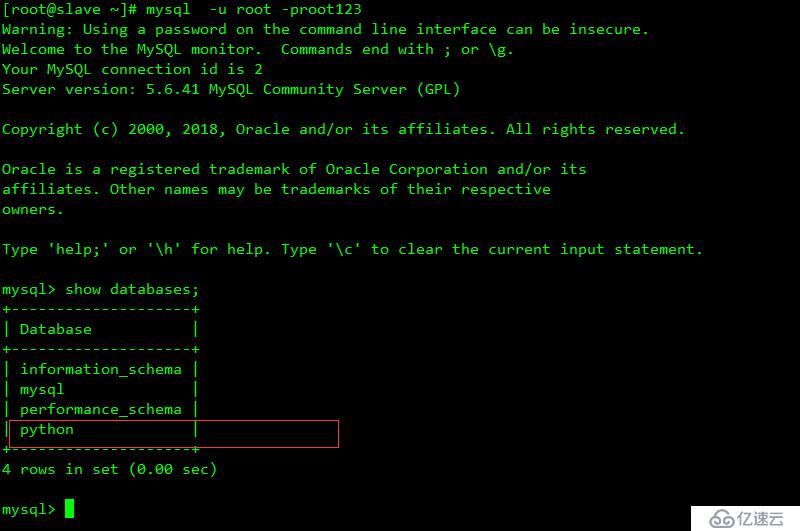
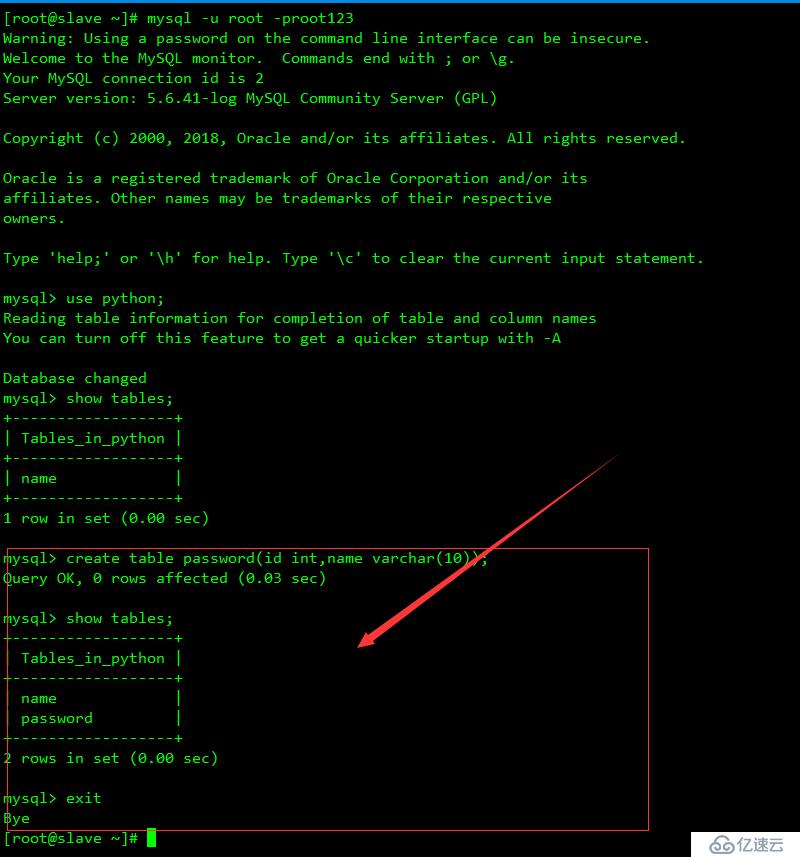
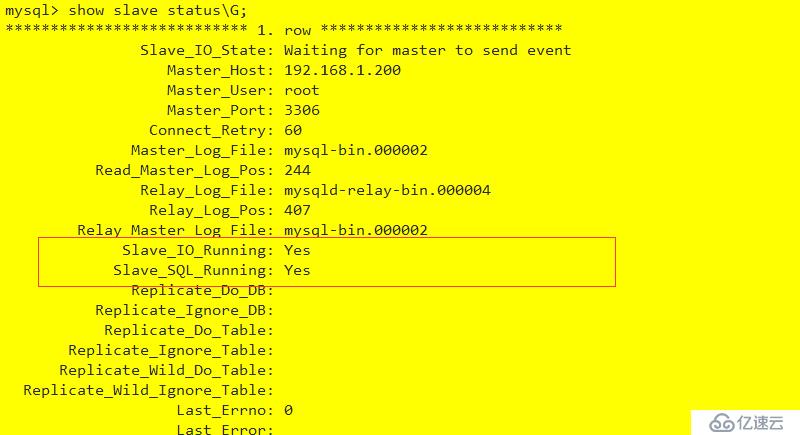
測試

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





