溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家分析了大數據交叉報表性能優化實例分析的相關知識點,內容詳細易懂,操作細節合理,具有一定參考價值。如果感興趣的話,不妨跟著跟隨小編一起來看看,下面跟著小編一起深入學習“大數據交叉報表性能優化實例分析”的知識吧。
OS:win7
Cpu:8 核
集算報表:1120 安裝版
Jvm:1G
數據庫:oracle11g
有一個交叉匯總報表,其實格式很簡單,行列各一個統計維度。但后臺業務表的數據有 175 萬條,且還要與其他表(大概在 7w 條左右)做 join,如果由 sql 來處理,可以想象到會慢到什么程度,關鍵受各種條件影響,能否查出數據都是問題。
注:ACCORECEIVE 表 175w 條數據
目前,測試 birt 需 5 分鐘,借助各種中間表與視圖。報表友商無法出表。
要求:能做出該報表在 web 展現,且重要的是速度要快,另外,數據(目前大概是 5 年數據)是實時增加的。
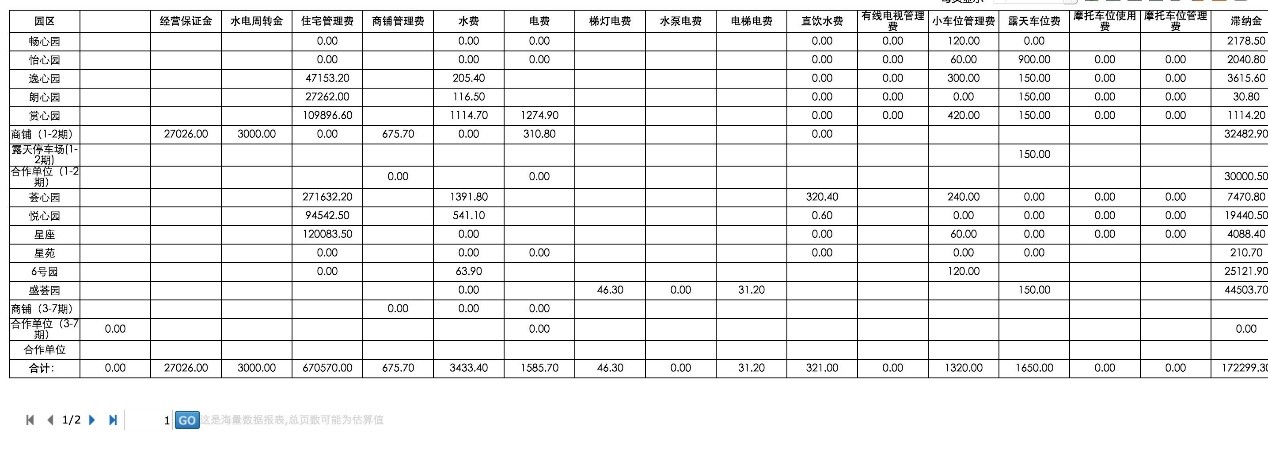
客戶報表格式及目前所用 sql:
報表格式:
Sql:
select LOCATIONS.loupan loupan,
LOCATIONS.LPORDERNUM,
nvl(ACCORECEIVE.RECEIVABLEAMOUNT, 0) yingshou,
chargeproct.Description CHARPNAME,
chargeproct.ordernum chordernum
from ACCORECEIVE,V\_LOCATION\_LP\_LG\_DY LOCATIONS,chargeproct
where ACCORECEIVE.Org\_Id = LOCATIONS.Org\_Id
and ACCORECEIVE.Sub\_Org\_Id = LOCATIONS.Sub\_Org\_Id
and ACCORECEIVE.Fk_Locationid = LOCATIONS.Locationid
and ACCORECEIVE.Fk_Chargeproctid = chargeproct.chargeproctid(+)
and ACCORECEIVE.Wf_Status not in('作廢')常規模式下,大數據要出交叉報表幾乎很難,這里受 sql 效率慢、jvm 等的影響,一次如果把所有數據全部取出則必然極大可能內存溢出。另外,大數據表再有 join,即便能取,那取數速度上肯定也無法保證(sql join 的效率低),上面 sql 中能體現出所有問題。
解決方案:
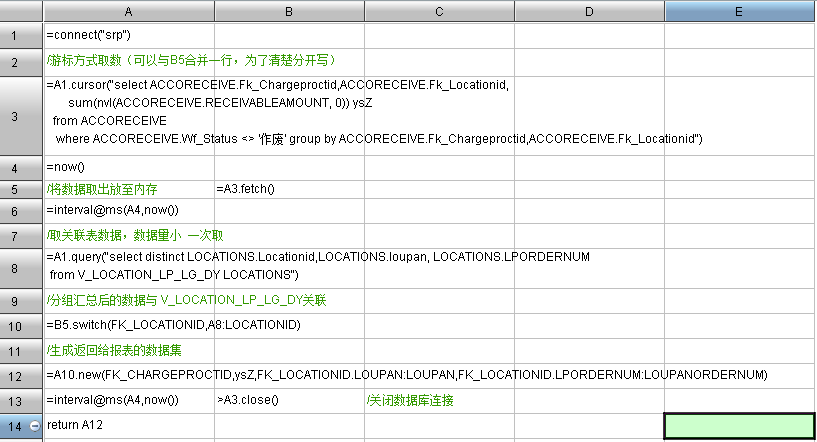
1、為避免一次性取數內存溢出,可采用集算器游標 cursor 取數; –cursor
2、去除不需要字段及 join 字段。分析后發現,客戶實際不需要 org_id、sub_org_id 的關聯;
3、取數后可根據客戶所出報表對應做數據處理,這里可 groups 處理一次分組匯總;–替代報表表達式 group
4、為擺脫 sql join 效率低問題,可將 join 放在集算器內處理,這里 ACCORECEIVE 與 V_LOCATION_LP_LG_DY 表(query 即可,數據不大)分開取數; –switch 連接
注:集算器中測試了兩表 sql 中 join,時間大概需 5 分鐘。
5、結合客戶報表格式及所用的數據庫表,可將上面 sql 中 chargeproct 表放到報表 sql 取數,因其僅體現顯示值作用,且僅幾十條數據。
集算腳本:
注:代碼有每一步的作用說明
關于“大數據交叉報表性能優化實例分析”就介紹到這了,更多相關內容可以搜索億速云以前的文章,希望能夠幫助大家答疑解惑,請多多支持億速云網站!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





