溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
事務是數據處理的核心,是業務上的一個邏輯單元,它能夠保證其中對數據所有的操作,要么全部成功,要么全部失敗。DBMS通過事務的管理來協調用戶的并發行為,減少用戶訪問資源的沖突。

.
1)顯示提交:當事務遇到COMMIT指令時,將結束事務并永久保存所有的更改的數據。
2)顯示回滾:當事務遇到ROLLBACK指令時,也將結束事務的執行,但是此時它回滾所有更改的數據到事務開始時的原始值,即取消更改,數據沒有變化。
3)DDL語句:一旦用戶執行了DDL(數據定義語言,如create,drop等)語句,則之前的所有DML(數據操作語言)操作作為一個事務提交,這種提交稱為隱示提交。
4)正常結束程序:如果oracle數據庫應用程序正常結束,如使用sqlplus工具更改了數據,而正常退出該程序(exit),則oracle自動提交事務。
5)非正常地結束程序:當程序崩潰或意外終止時,所有數據更改都被回滾,這種回滾成為隱示回滾。
.事務的特點
事務有4個特性,簡寫為ACID特性。
1)原則性:以轉賬操作為例,轉出賬戶余額減少和轉入余額增加是兩個DML語句,但是必須作為一個不可分割的完整操作。要么同時成功,要么同時失敗,只轉出而沒有轉入顯然是不可接受的。
2)一致性:無論是在事務前、事務中、事務后,數據庫始終處于一致的狀態。例如:轉賬前分別是2000和1000,總金額是3000,轉賬300后分別是1700和1300,總金額還是3000.這就叫做一致性。不一致就是在某個時間點查詢到的總金額不是3000.
3)隔離性:在某個時間段,肯定有很多人都在轉賬,每個人的轉賬都是在自己的事務中,所以在一個數據庫中,會有很多事物同時存在。雖然同時存在很多事物,但是事物之間不會相互影響。
4)持久性:如果事物提交成功,則數據修改永遠生效,如果是回滾,則數據完全沒有沒修改,就相當于沒有這件事情發生。
.
事物的控制
1)使用COMMIT和ROLLBACK實現事物控制
COMMIT:提交事物,把事物中對數據庫的修改進行永久保存。
ROLLBACK:回滾事物,取消對數據庫所做的任何修改。
.
例1:使用COMMIT和ROLLBACK實現事物控制

首先執行插入數據。
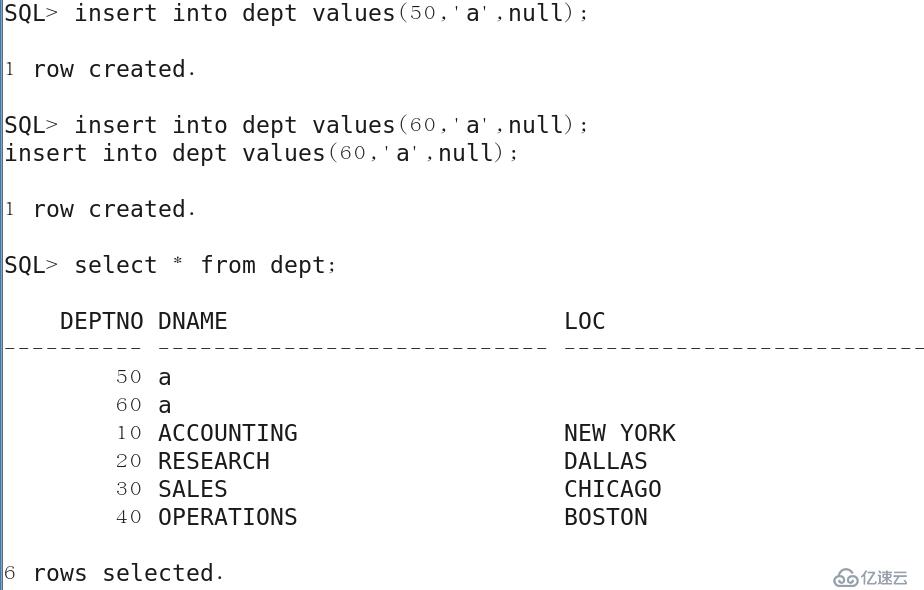
.
執行COMMIT提交事物,數據將會永久保存。

.
再次插入數據,并執行rollback回滾。


查詢沒有發現70這一行數據
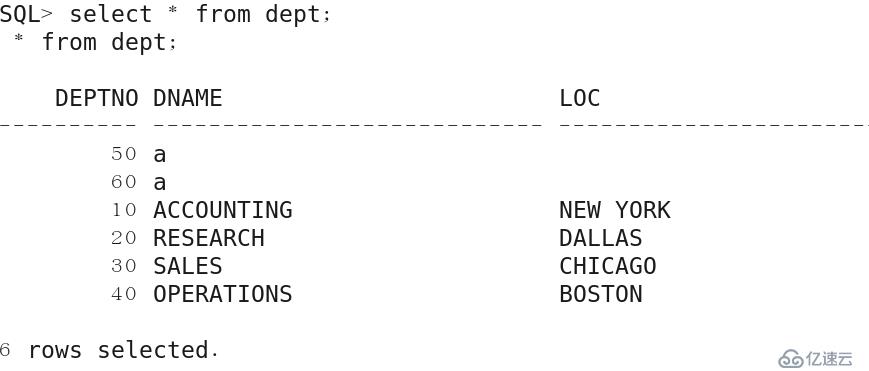
.
2)使用AUTOCOMMIT實現事物的自動提交
Oracle提供了一種自動提交DML操作的方式,這樣一旦用戶執行了DML操作,如UPDATE,DELETE等,數據就會自動提交。
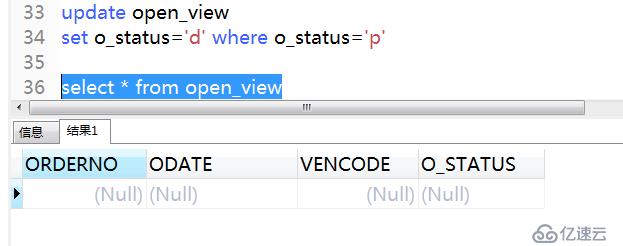
例2:使用autocommit實現事物自動提交,設置autocommit為ON
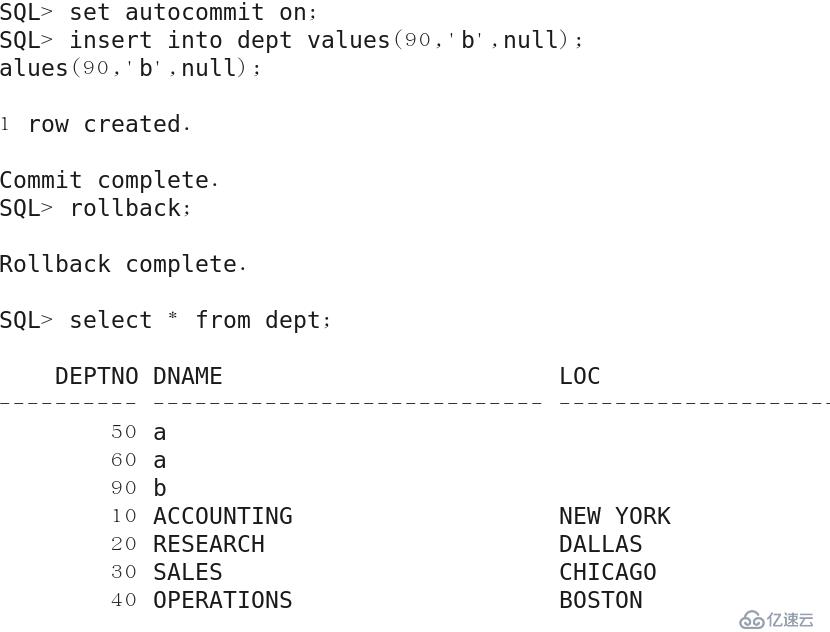
.
只要提前執行了set autocommit on 命令,數據就會自動提交,及時執行了回滾數據也會依然保存。
.
3)驗證隔離性
1)建立表yuangong,并插入數據。

此時insert記錄的事務并沒有提交,沒有提交事務就沒有真正的完成,此時還有rollback的機會。
.
2)查詢一下

.
3)然后打開一個新的sqlplus會話,查看表時會發現并沒有新插入的記錄,這是事物的隔離性。

.
4)在第一個sqlplus會話中提交事物

.
5)提交之后才能在第二個會話中看到被插入的第四條記錄

.
4)驗證持久性
一旦使用commit命令來結束某個事務,那么就必須保證數據庫不丟失這個事務。在事務進行期間,隔離性的原則要求除了指定會話涉及的用戶之外的任何用戶都不能查看當前所做的變化。不過事務一旦完成,所有用戶都必須能夠立即看到所做的變化,同時數據庫必須保證這些變化絕不會丟失。Oracle通過使用日志文件來滿足這個需求。日志文件具有兩種形式:聯機重做日志文件,歸檔重做日志文件。
一個正確配置的oracle數據庫是不可能丟失數據的。當然用戶的錯誤(包括不恰當的DML或刪除對象)也會造成數據的丟失。DDL語句有自動提交功能(create、drop、truncate、alter)
.1)刪除表yuangong,再次查詢提示表不存在

.
2)新建表students,并插入一條數據

.
3)回滾事務

.
4)再次寫入數據

.
5)退出sqlplus(exit)
6)在另外一個sqlplus中查看aa表中的記錄,會發現新插入的lisi的記錄了。如果使用sqlplus工具更改了數據之后,正常退出sqlplus時,oracle會自動提交事物。

.
關于事物的總結:
- 需要注意的是,Commit:只是用來確認這個數據已經正式的修改了,不一定非得寫入硬盤,DBWn什么都不做。執行commit命令時發生的所有物理操作時LGWR進程將日志緩沖區的內容寫入磁盤。DBWN進程完全沒有執行任何操作。DBWN進程與提交事物處理沒有關系,不過最終DBWN進程會將變化的數據塊寫入磁盤。
- commit和rollback語句只應于DML語句,我們無法回滾DDL語句。DDL語句一旦被執行就會立即具有持久狀態。
3.自動提交和隱式提交:oracle在某些情況下可以進行自動提交:執行DDL語句是一種情況,退出某個用戶進程也是一種自動提交。
.
索引
索引的含義
Oracle 數據庫對象又稱模式對象,數據庫對象是邏輯結構的集合,最基本的數據庫對象是表,索引也是其中之一。其他數據庫對象包括:
索引是oracle的一個對象,是與表關聯的可選結構,提供了一種快速訪問數據的途徑,提高了數據庫檢索性能。索引使數據庫程序無需對整個表進行掃描,就可以在其中找到所需要的數據。就像書的目錄,可以通過目錄快速查找所需信息,無需閱讀整本書。
.
索引的特點
適當地使用索引可以提高查詢速度
可以對表的一列或多列建立索引
建立索引的數量沒有限制
索引需要磁盤存儲,可以指定表空間,由oracle自動維護
索引對用戶透明,檢索時是否使用索引由oracle自身決定
Oracle數據庫管理系統在訪問數據時使用以下三種方式:
全表掃描
通過ROWID(行地址,快速訪問表的一行)
使用索引
當沒有索引或者不選擇使用索引時就用全表掃描的方式
.索引的分類
1)B樹索引結構
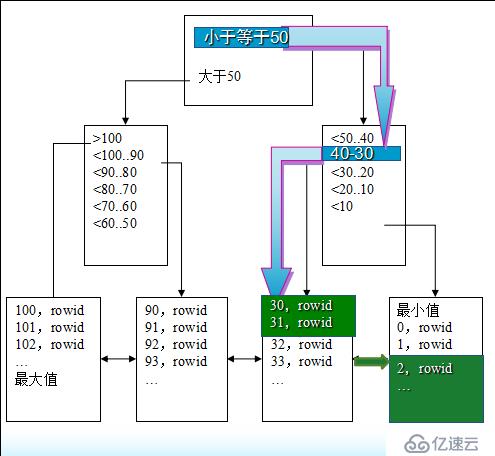
索引的頂部為根,其中包含指向下一級索引的項。下一級為分支塊,分支塊又指向索引中下一級的塊,最低一級的塊稱為葉節點,其中包含指向表數據行的索引項。葉節點為雙向連接,有助于按關鍵字值得升序和降序掃描索引。
例如:查詢id從2到31行的數據
.
上圖中使用索引遍歷過程如下:
先找到id<=50的分支塊,再找到30-40的分支塊,在找到id=31對應的索引項,之后通過葉節點雙向鏈接,平行地找到包含id=2的索引塊,完成對id的查詢
.
4、創建索引的語法
create [unique] index 索引名稱 on 表名(列名)[tablespace 表空間名稱]解釋:
[unique]用于指定唯一索引,默認情況下為非唯一索引
[tablespace]為索引指定表空間1)創建標準索引
SQL> CREATE INDEX index_name ON tablename(columnname)
TABLESPACE index_tbs;
2)重建索引
SQL> ALTER INDEX index_name REBUILD;合并索引碎片
SQL>ALTER INDEX index_name COALESCE;
.
3)刪除索引
SQL> DROP INDEX index_name;
.例1:
1)在雇員表(emp)中,為雇員名稱(ename)列創建b樹索引。
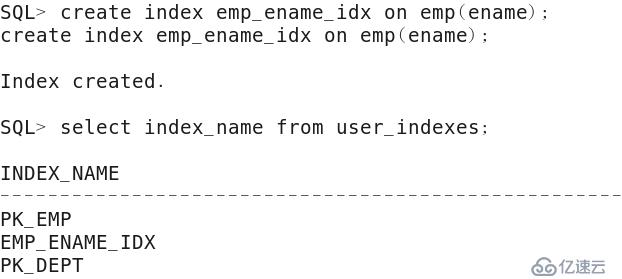
.
創建唯一索
?確保在定義索引的列中沒有重復值
?Oracle 自動在表的主鍵列上創建唯一索引
?使用CREATE UNIQUE INDEX語句創建唯一索引
語法如下:
SQL> CREATE UNIQUE INDEX index_name
ON tablename(columnname);
例:在薪水級別(salgrade)表中,為級別編號grade列創建唯一索引。
.
6、反向鍵索引
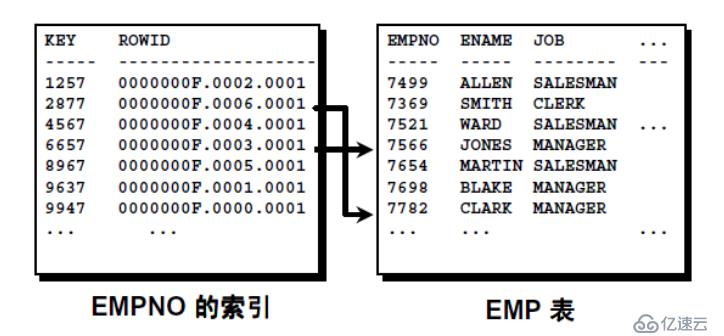
與常規B樹索引相反,反向鍵索引在保持列順序的同時反轉索引列的字節。反向鍵索引通過反轉索引鍵的數據值,使得索引的修改平均分布到整個索引樹上。主要應用于所多個實例同時訪問一個數據庫的場景中。如下圖:
.
如果在常規的B樹索引情況下,由于兩個雇員號empno索引在索引樹種的位置相近而處于同一個索引塊中,多個實例同時更新時會發生沖突,從而導致i/o訪問上的瓶頸。所以這時候可以使用反向鍵索引。反向鍵索引通常建立在一些連續增長的列上,如:編號。
例:在雇員emp表中,為雇員編號empno列創建反向鍵索引。CREATE INDEX emp_empno_reverse_idx ON emp(empno) REVERSE;
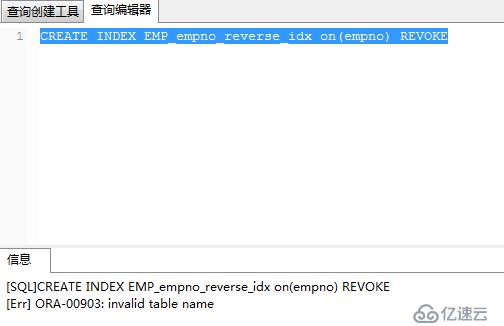
.
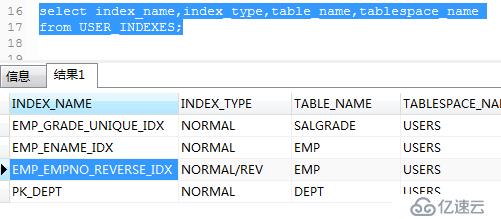
提示此列已經建立索引了,執行下面命令查詢索引有哪些。
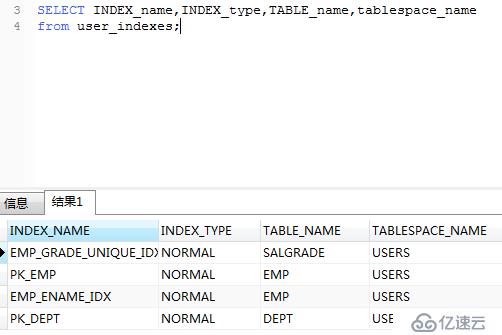
.
下面查詢一下PK_EMP索引是為哪列創建的。
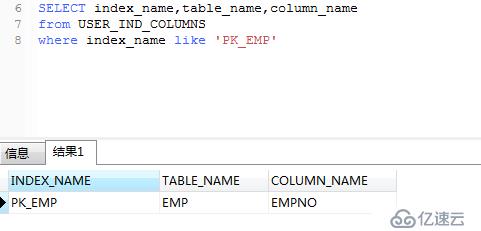
.
由上圖可以看出,PK_EMP索引是為empno列創建的,所以上面創建反向鍵索引創建不了,相同的列不能創建多個索引。
所以要么把PK_EMP索引刪除,要么就保留這個索引,不創建反向鍵索引
那我們現在把原來的PK_EMP刪除
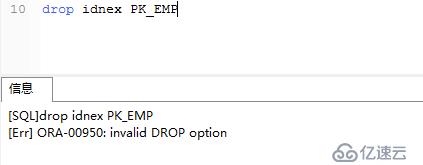
.
提示無法刪除,因為這個索引的表EMP有主鍵,想刪除索引,必須去掉主鍵,命令如下:
alter table 表名 drop constraint 主鍵名
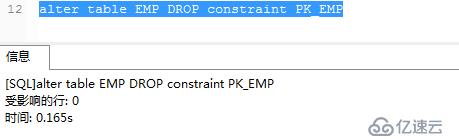
.
然后創建反向鍵索引
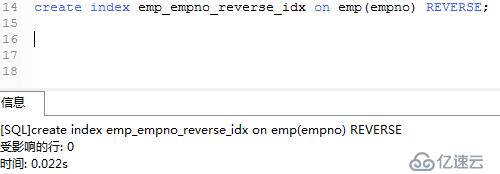
.
查詢建立是否成功.
補充:修改主鍵:
alter table 表名 add constraint 主鍵名 primary key (column1,column2,....,column)
注意:這里的主鍵名是自己定義的一個字符串,可以不是表中字段名(習慣寫成:PK_表名 的格式,oracle 中自動建立的主鍵名是PK_表名 的格式),不過要牢記啊,刪除的時候用到的也是這個名!括號中的才是表中存在的字段。
ALTER TABLE ZFMI.TB_RI_SHARE_BILL ADD?
CONSTRAINT PK_TB_RI_SHARE_BILL
PRIMARY KEY (C_RI_COM_CDE, C_PROD_NO, C_FEE_TYPE, C_SHARE_YM)
ENABLE
VALIDATE
.
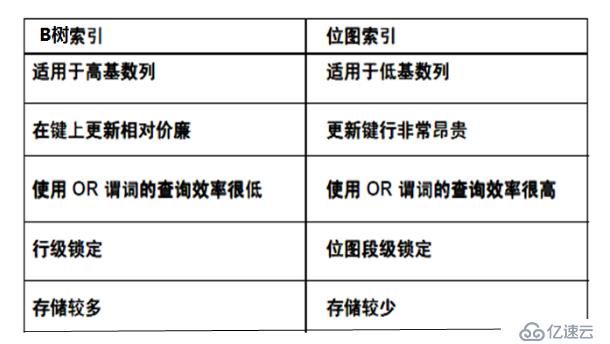
7、位圖索引
位圖索引適合低于基數的列,即該列的值是有限的幾個。例如:雇員表中的工種(job)列,即便是幾百萬條雇員記錄,工種也是有限的。Job列可以作為位圖索引,類似的還有圖書表中的圖書類別列等。
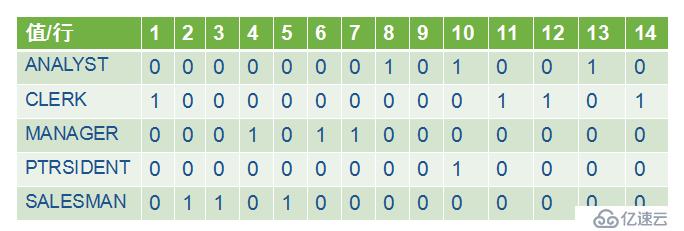
.
位圖索引不直接存儲ROWID,而是存儲字節位到ROWID的映射,減少響應時間,節省空間占用。位圖索引不應當在頻發發生insert、update、delete操作的表上使用,這是因為單個位圖索引指向表的很多數據行,當修改索引項時需要將其指向的數據行全部鎖定,這會嚴重降低數據庫的并發處理能力。位圖索引適合用于數據倉庫和決策支持系統中。
例:在雇員emp表中,為工種(job)列創建位圖索引。
基本語法:
CREATE BITMAP INDEX emp_job_bit_idx ON emp(job);
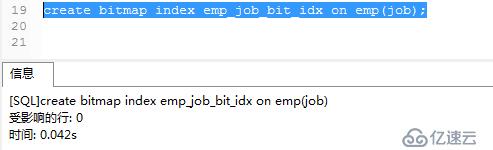
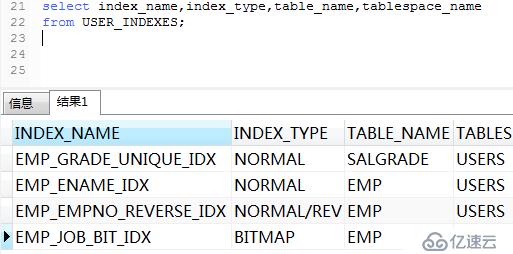
查詢一下建立是否成功。
.
.
組合索引
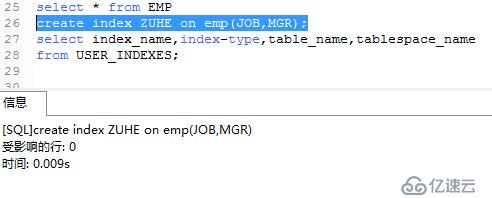
類似sqlserver的復合索引,在表內多列上創建索引。索引中的列不必與表中的列順序一致,也不必相互鄰接。
例:雇員表中部門和職務列上的索引。組合索引的列最多包含32列。
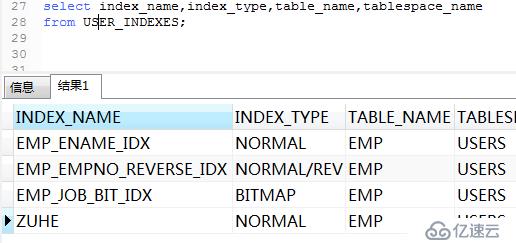
.
基于函數的索引
需要創建的索引需要使用表中一列或多列的函數或表達式,也可以將基于函數的索引創建為B樹索引或位圖索引。
基本語法:
SQL> CREATE INDEX emp_ename_upper_idx
ON tablename (UPPER(columnname));
例:在雇員(emp)表中,為雇員名稱(ename)列創建小寫函數索引。
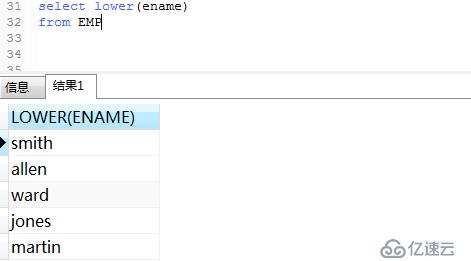
.
建立索引:
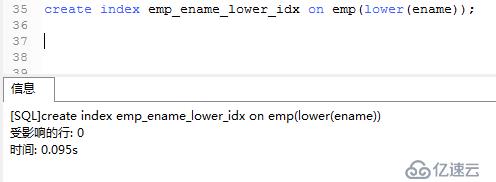
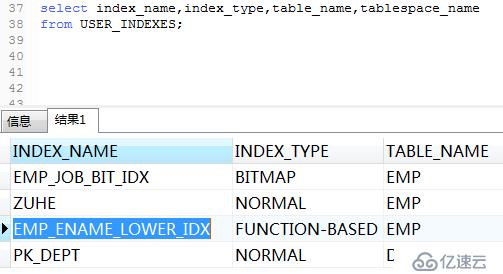
.
創建索引的原則
頻繁搜索的列可以作為索引列
經常排序,分組的列可以作為索引
經常用作連接的列(主鍵/外鍵)可以作為索引
將索引放在一個單獨的表空間中,不要放在有回退段、臨時段和表的表空間中
對于大型索引而言,考慮使用NOLOGIN子句創建大型索引。
根據業務數據發生頻率,定期重新生成或重新組織索引,進行碎片整理。
.例:將索引放在一個單獨的表空間中
1)使用sys登錄創建表空間create tablespace net_tbs
datafile '/opt/oracle/oradata/orcl/worktbs01.dbf'
size 10m autoextend on;
.
2)修改索引到表空間。alter index ZUHE rebuild tablespace NEW_TBS
.
3)查詢一下是否修改。select index_name,index_type,table_name,tablespace_name
from USER_INDEXES
.
由上圖可以看出表空間已經改為了new_tbs。
.
例2:使用nologging子句create index ZUHE2 on emp(JOB,SAL) nologging
select index_name,index_type,table_name,tablespace_name
from USER_INDEXES
.
查看索引列相關的信息:索引名、表名、索引列。select index_name,table_name,column_name
from user_ind_columns
where index_name like 'EMP%'
.維護索引
1)重建索引
索引需要維護,如果建立了索引的表中有大量的刪除和插入操作,會使得索引很大,因為刪除操作后,刪除值的索引空間不能被自動重新使用,對于大表和DML操作很頻繁的表,索引的維護是很重要的。Oracle提供了rebuild指令來重建索引。使索引空間可以重用刪除值所占用的空間,使索引更加緊湊。alter index emp_job_bit_idx rebuild tablespace net_tbs
.
select index_name,index_type,table_name,tablespace_name
from USER_INDEXES2)合并索引碎片
合并索引碎片可以釋放部分磁盤空間,是索引維護的一種重要方式,也是維護磁盤空間的方式,類似于磁盤碎片整理,把不用的空間釋放出來再利用。alter index emp_job_bit_idx COALESCE
.3)刪除索引
drop index emp_job_bit_idx
.
.
視圖
概述
視圖是一個虛表,不占用物理空間,因為視圖本身的定義語句存儲在數據字典里,視圖中的數據是一個或多個實際表中獲得的。那些用于產生視圖的表叫做該視圖的基表。一個視圖也可以從另一個視圖中產生。
.視圖的優點:
1)提供了另外一種級別的表安全性
2)隱藏的數據的復雜性:一個視圖可能是用多表連接定義的,但用戶不需要知道多表連接的語句也可以查詢數據。
3)簡化的用戶的SQL命令:查詢視圖的時候不需要寫出復雜的查詢語句,只需要查詢視圖名稱即可。
4)隔離基表結構的改變:視圖創建好了之后,如果修改了表的結構,也不會影響視圖的。
5)通過重命名列,從另一個角度提供數據:例如在銷售系統中,每日下班前要對當日數據進行匯總,在銷售人員眼中,該匯總表成為日銷售統計表,在財務人眼中,該銷售表成為銷售日報表。
.創建視圖的語法:
1) CREATE [OR REPLACE] [FORCE] VIEW
view_name [(alias[, alias]...)]
AS select_statement
[WITH CHECK OPTION]
[WITH READ ONLY];
解釋:
OR REPLACE:如果視圖已存在,此選項將重新創建該視圖。
FORCE:如果使用此關鍵字,則無論基表是否存在,都將創建視圖。
NOFORCE:這是默認值,如果使用此關鍵字,則僅當基表存在時才創建視圖。
VIEW_NAME:要創建視圖的名稱
Alias:指定由視圖的查詢所選擇的表達式或列的別名。別名的數目必須與視圖所選擇的表達式的數目相匹配。
Select_statement:select語句
WITH CHECK OPTION :此選項指定只能插入或更新視圖可以訪問的行。術語constraint表示為CHECK OPTION約束指定的名稱。
WITH READ ONLY:此選項保證不能在此視圖上執行任何修改操作。
.2)視圖中的ORDER BY子句
可以在創建視圖時在SELECT語句中使用ORDER BY子句,以便按照特定的順序進行排序,這樣,在查詢視圖時即使不使用ORDER BY子句,結果集也會按指定的順序進行排列。
.
3)創建帶有錯誤的視圖
如果在create view語句中使用FORCE選項,即使存在系列情況,oracle也會創建視圖。
?視圖定義的查詢引用了一個不存在的表。
?視圖定義的查詢引用了現有表中無效的列。
?視圖的所有者沒有所需的權限。
在這些情況下,oracle僅檢查create view語句中的語法錯誤。如果語法正確,將會創建視圖,并將視圖的定義存在數據字典中。但是,該視圖卻不能使用。這種視圖被認為是“帶錯誤創建”的。可使用SHOW ERRORS VIEW視圖名來查看錯誤。
.
4、實驗案例:對單表視圖的操作
1)連接到oacle,使用scott用戶登錄
.
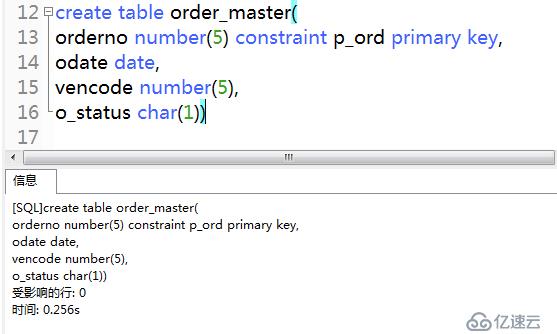
2)創建表order_master
.
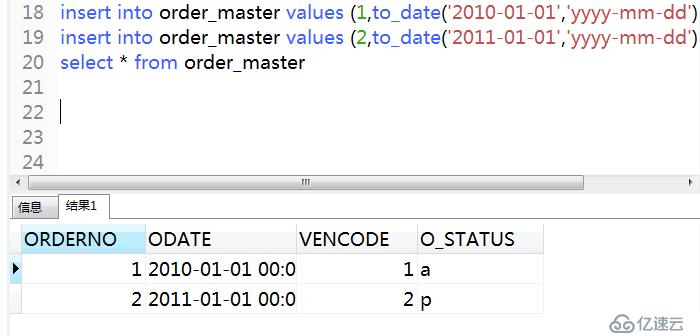
3)插入數據
SQL> insert into order_master values (1,to_date('2010-01-01','yyyy-mm-dd'),1,'a');
SQL> insert into order_master values (2,to_date('2011-01-01','yyyy-mm-dd'),2,'p');
.
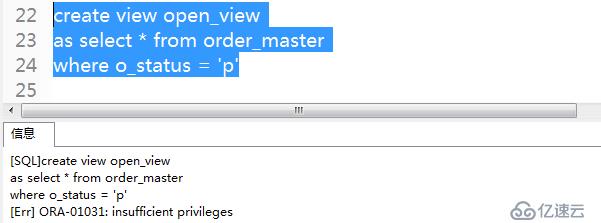
4)創建訂單狀態為"p"的視圖,提示沒有創建視圖的權限。
.
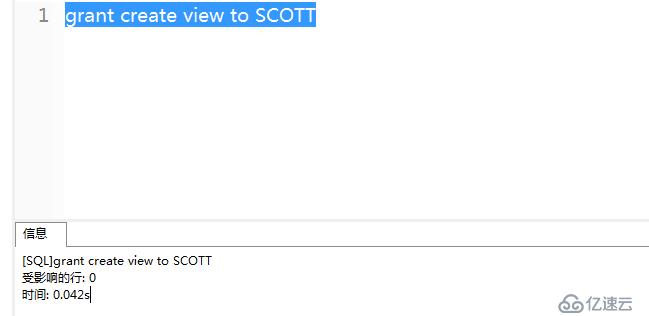
5)授予創建視圖的權限(使用sys用戶登錄)
.
6)再次創建視圖

.
7)查詢視圖
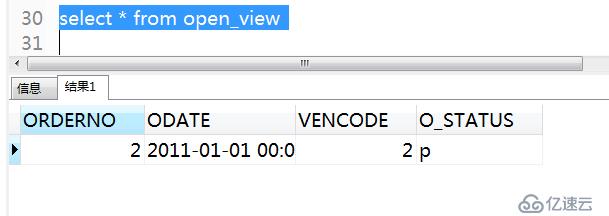
有上圖結果可以看出,查詢視圖也能查出表中的數據。
.
8)通過視圖修改數據,將狀態為p的訂單修改為d,但是修改完成之后再次查詢視圖將查不出任何數據,因為修改了創建視圖時作為條件的列。
.
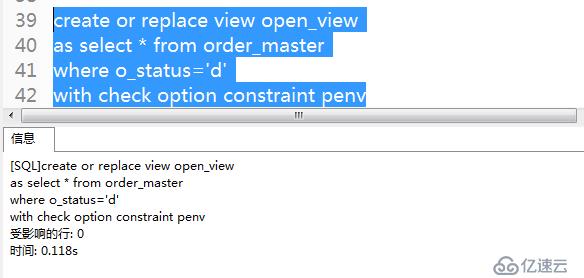
9)為了避免修改視圖后查詢不到的現象,使用with_check_option語句創建檢查約束,以防止上述情況發生,同時可以使用constraint指定約束名稱。
.
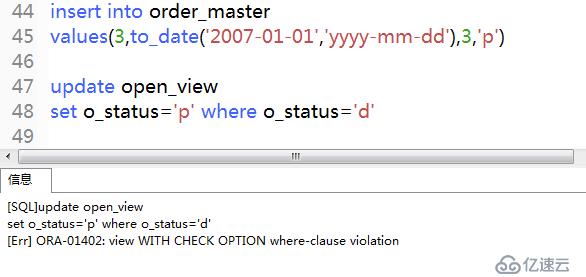
10)再次寫入數據,并且再次更新(出現違規提示)
.
5、實驗案例:創建只讀視圖
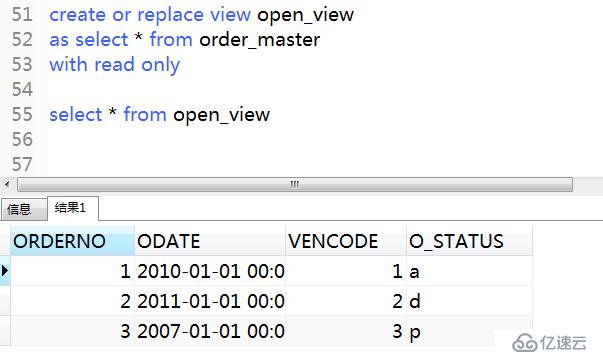
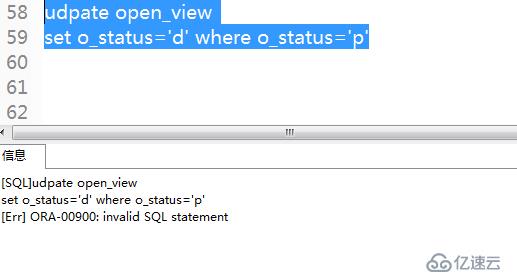
1)使用read only創建只讀視圖,查詢視圖
.
3)再次更新視圖,提示無法對只讀視圖進行dml操作。
.
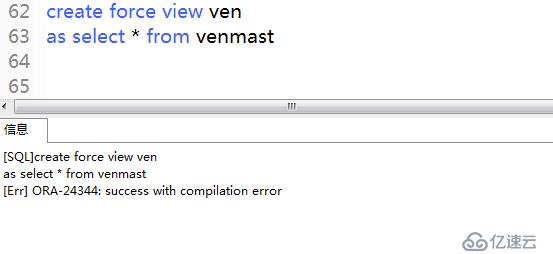
6、實驗案例:創建帶有錯誤的視圖
1)使用force創建帶有錯誤的視圖,其中venmast表不存在,但是也能創建成功。
.
2)創建表

.
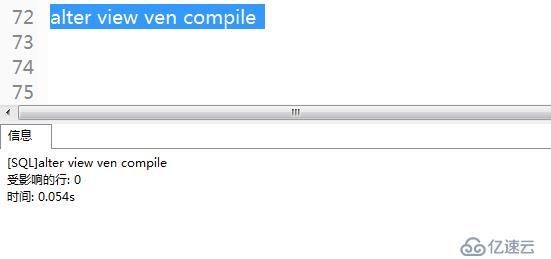
3)重新編譯現有視圖,使其生效。
.
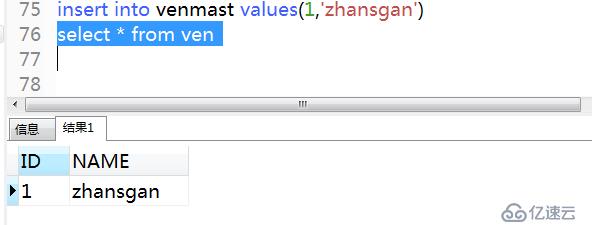
4)測試查詢視圖
.
7、創建order by 子句的視圖(查詢視圖之后會自動排序)
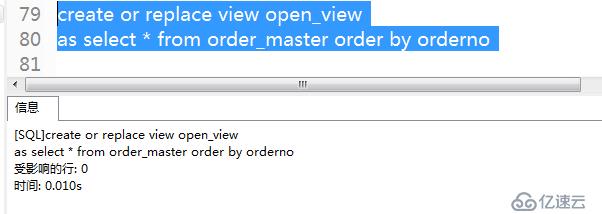
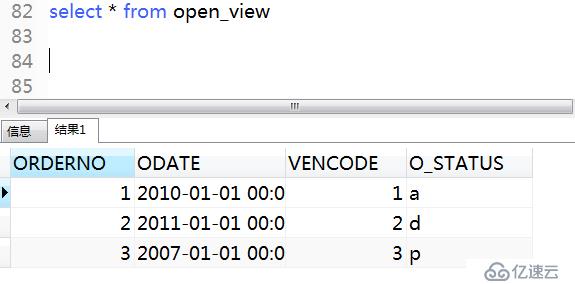
.
然后再創建一個降序的,再次查詢視圖
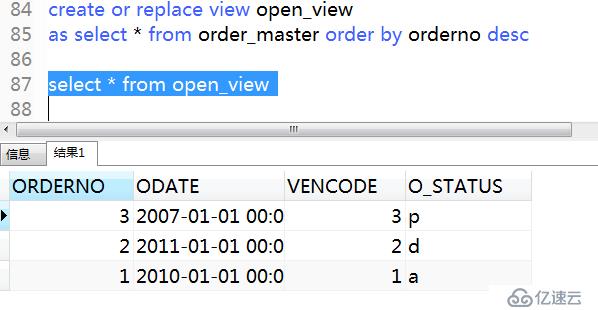
.
DML語句和復雜視圖
DML語句是指用于修改數據的insert、delete和update語句。因為視圖是一個虛擬的表,所以這些語句也可以與視圖一同使用。一般情況下不通過視圖修改數據,而是直接修改基表,因為這樣條例更清晰。在視圖上使用DML語句有如下限制(相對于表)。
1)DML語句只能修改視圖中的一個基表。
2)如果過記錄的修改違反了基表的約束條件,則將無法更新視圖。
3)如果創建的視圖包含連接運算符,DISTINCT運算符、集合運算符、聚合函數和groupby子句,則將無法更新視圖。
4)如果創建的視圖包含偽列表達式,則將無法更新視圖。
.
簡單視圖基于單個基表,不包括函數和分組函數,那么可以在此視圖中進行insert、update、delete操作,這些操作實際上在基表中插入、更新和刪除行。
復雜視圖從多個表提取數據,包括函數分組函數。復雜視圖不一定能進行DML操作。
.1)查詢視圖
通過數據字典USER_VIEWS可以查詢當前用戶下創建的視圖名稱。
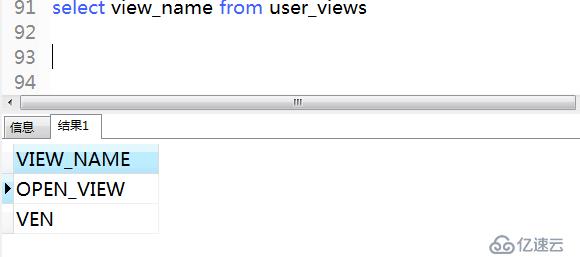
.
2)刪除視圖
要從數據庫中刪除視圖,可以使用drop view命令。
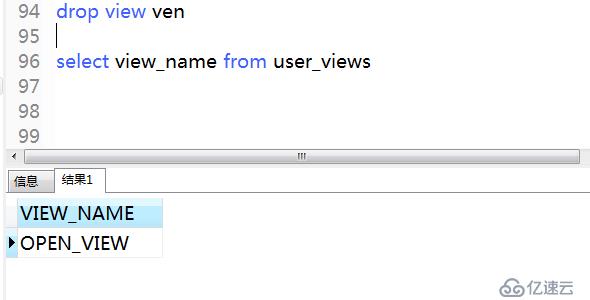
.
物化視圖
1)物化視圖的含義
物化視圖適合普通視圖相對應的。在oracle使用普通視圖時,它會重復執行創建視圖的所有sql語句,如果這樣的sql語句含有多張表的連接或者order by 子句,而且表數據量很大,則會非常耗時,效率非常低下,為了解決這個問題,oracle提出了物化視圖的概念。
簡單的講,物化視圖就是具有物理存儲的特殊視圖,占據物理空間,就像表一樣。物化視圖是基于表、物化視圖等創建的。他需要和源表進行同步,不斷地刷新物化視圖中的數據。
物化視圖中有兩個重要概念:查詢重寫和物化視圖的同步。\

.
查詢重寫:
對sql語句進行重寫,當用戶使用sql語句對基表進行查詢時,如果已經建立了基于這些表的物化視圖,oracle將自動計算和使用物化視圖來完成查詢,在某些情況下可以節約查詢時間,減少系統i/o。Oracle將這種查詢優化技術成為查詢重寫。參數QUERY_REWRITE_ENABLED決定是否使用重寫查詢,該參數為布爾型。在創建物化視圖需要使用ENABLE_QUERY REWRITE來啟動查詢重寫功能。通過SHOW指令可以查看該參數的值。

.
2)物化視圖的同步:
物化視圖是基于表創建的,所以當基表變化時,需要同步數據以更新物化視圖中的數據,這樣保持物化視圖中的數據和基表的數據一致性。Oracle提供了兩種物化視圖的刷新方式,決定何時進行刷新,即ON COMMIT方式和ON DEMAND方式。
ON COMMIT方式:指物化視圖在對基表的DML操作事務提交的同時進行刷新。
ON DEMAND方式:指物化視圖在用戶需要的時候進行更新,可以手工通過DBMS_MVIEW.REFRESH等方式來進行刷新,也可以通過JOB定時進行刷新。
選擇刷新方式之后,還需要選擇一種刷新類型,刷新類型指定刷新時基表與物化視圖如何實現數據的同步,oracle提供了以下4種刷新類型。
COMPLETE:對整個物化視圖進行完全的刷新。
FAST:采用增量刷新,只刷新自上次刷新后進行的修改。
FORCE:oracle在刷新時會去判斷是否可以進行快速刷新,如果可以則采用FAST方式,否則采用COMPLETE方式。
NEVER:物化視圖不進行任何刷新。
默認值是FORCE刷新類型。
.3)創建物化視圖
① 創建物化視圖的前提條件
具備創建物化視圖的權限,QUERY REWRITE的權限,以及對創建物化視圖所涉及的表的訪問權限和創建表的權限。
以sys身份登錄,之后授予scott用戶創建物化視圖的權限。
grant create materialized view to scott;
grant query rewrite to scott;
grant create any table to scott;
grant select any table to scott;

.
② 創建物化視圖日志
物化視圖日志是用戶選擇了FAST刷新類型時使用的,以增量同步基表的變化。
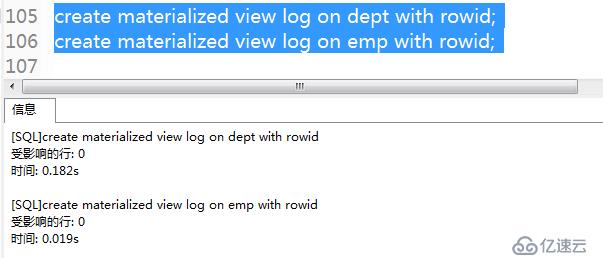
對scott用戶的表DETP和表EMP創建物化視圖,所以對這兩個基表創建物化視圖日志。
create materialized view log on dept with rowid;
create materialized view log on emp with rowid;
.
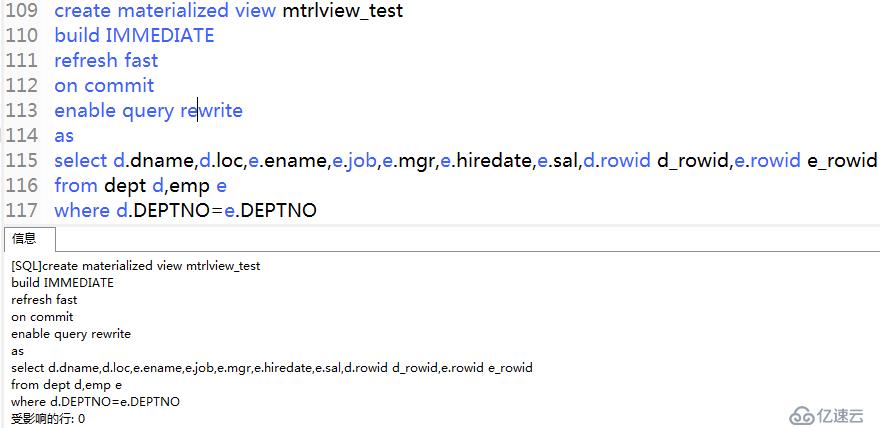
③ 創建物化視圖語句
通過create materialized view 語句創建物化視圖,需要注意各個參數的含義
create materialized view mtrlview_test
build IMMEDIATE
refresh fast
on commit
enable query rewrite
as
select d.dname,d.loc,e.ename,e.job,e.mgr,e.hiredate,e.sal,d.rowid d_rowid,e.rowid e_rowid
from dept d,emp e
where d.DEPTNO=e.DEPTNO
命令解釋:bulid immediate:該參數的含義是立即創建物化視圖,也可以選擇build deffered,該參數說明在物化視圖定以后不會立即執行,而是延遲執行,在使用該視圖時再創建。
Reffesh fast:刷新數據的類型選擇FAST類型。
ON COMMIT:在基表有更新時提交后立即更新物化視圖。
ENABLE QUERY REWRITE:啟動查詢重寫功能。在創建物化視圖時明確說明啟用查詢重寫功能。
As:定義后面的查詢語句。
查詢體:物化視圖的查詢內容,該sql語句的查詢結果集輸出到物化視圖中,保存在由oracle自動創建的表中。
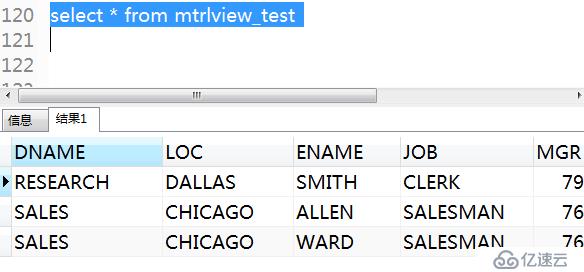
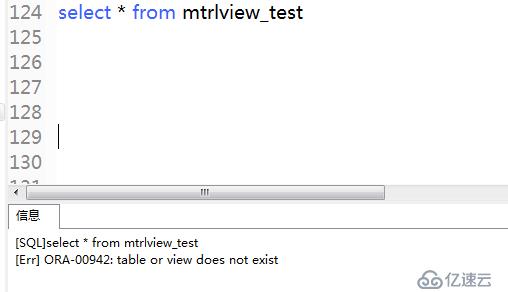
.查詢物化視圖:
select * from mtrlview_test
④ 刪除物化視圖
與刪除普通視圖相似,需要添加一個materialized關鍵字。
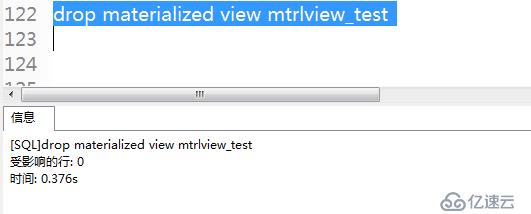
再次查詢視圖,提示視圖不存在。
.
.
序列
序列是用來生成唯一、連續的整數數據庫對象。序列通常用來自動生成主鍵或唯一鍵的值。序列可以按升序排列,也可以按降序排列,與excel的自動排序,以及sqlserver的標識符是一樣的。\1、創建序列
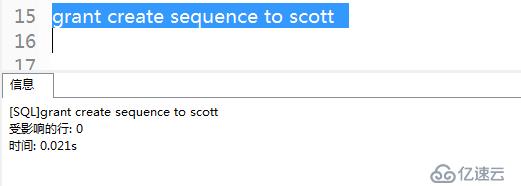
1)使用sys登錄授予scott創建序列的權限。
grant create sequence to scott;
語法:
CREATE SEQUENCE 名字
[START WITH integer]
[INCREMENT BY integer]
[MAXVALUE integer | NOMAXVALUE]
[MAXVALUE integer | NOMINVALUE]
[CYCLE|NOCYCLE]
[CACHE integer |NOCACHE];
.
解釋:START WITH:指定要生成的第一個序列號,對于升序序列,其默認值為序列的最小值,對于降序序列,其默認值為序列的最大值。
INCREMENT BY:用于指定序列號之間的間隔,默認值為1,如果n為正值,則生成的序列將按升序排序,如果n為負值,則生成的序列按降序排列。MAXVALUE:指定序列可以生成的最大值
NOMAXVALUE:如果指定了NOMAXVALUE,oracle將升序序列的最大值設為1027,將降序序列的最大值設為-1。
MINVALUE:指定序列最小值。MINVALUE必須小于或等于START WITH的值,并且必須小于MAXVALUE。
NOMINVALUE:如果指定了NOMINVALUE,oracle將升序序列的最小值設為1,或將降序列的值設置為-1026。
CYCLE:指定序列在達到最大值或最小值后,將繼續從頭開始生成值。
NOCYCLE:指定序列在達到最大值或最小值后,將不在繼續生成值。
CHCHE:使用CACHE選項可以預先分配一組序列號,并將其保留在內存中,這樣可以更快地訪問序列號,當用完緩存中的所有序列號時,oracle將生成另一組數值,并將其保留在緩存中。
NOCACHE:使用NOCACHE選項,則不會為加快訪問速度而預先分配序列號。如果在創建序列時忽略了CACHE和NOCACHE選項,oracle將默認緩存20個序列號。
.
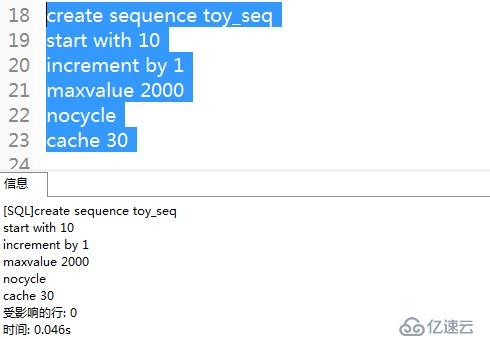
例1:創建序列號,從序號10開始,每次增加1,最大為2000,不循環,再增加會報錯。
create sequence toy_seq
start with 10
increment by 1
maxvalue 2000
nocycle
cache 30;
.
2、訪問序列
創建了序列之后,可以通過NEXTVAL和CURRVAL偽列來訪問該序列的值。可以從偽列中選擇值。但是不能操縱他們的值。
NETXVAL:創建序列后第一次使用NEXTVAL時,將返回該序列的初始值。以后再引用NETXVAL時,將使用INCREMENT BY子句的值來增加序列值,并返回這個新值。
CURRVAL:返回序列的當前值,即最后一次引用NEXTVAL時返回的值。
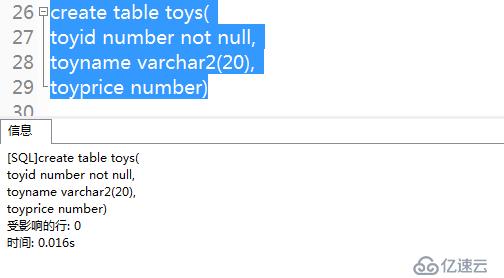
例2:在玩具表中,需要標識列toyid作為標識,不需要有任何含義,可以做為主鍵。1)創建表
create table toys(
toyid number not null,
toyname varchar2(20),
toyprice number
)
.
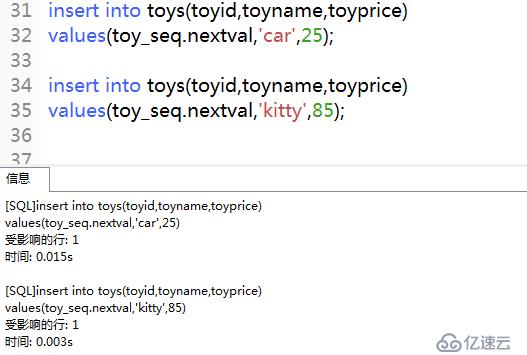
2)插入數據
insert into toys(toyid,toyname,toyprice)
values(toy_seq.nextval,'car',25);insert into toys(toyid,toyname,toyprice)
values(toy_seq.nextval,'kitty',85);
.
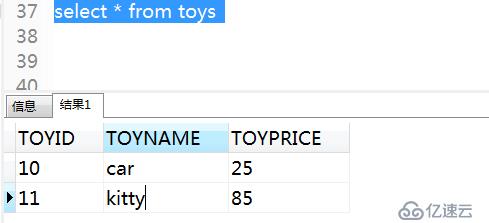
3)查詢數據
select * from toys;
.
4)查看序列當前值
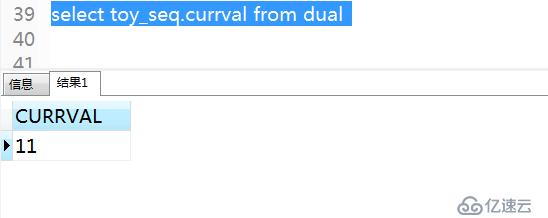
Currval返回序列的當前值,即最后一次引用NEXTVAL時返回的值。
.
5)測試currval
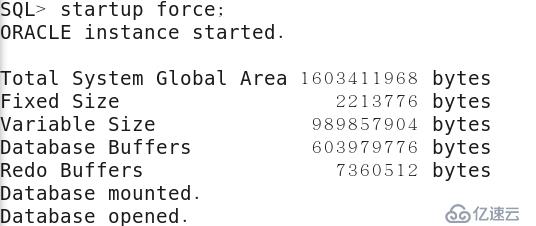
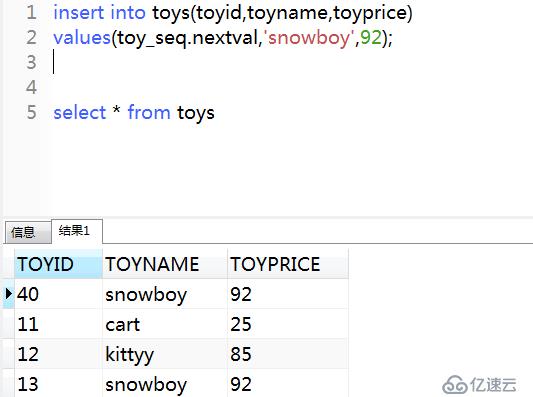
重啟實例之后再次寫入數據發現從40開始,因為按創建序列的要求,每次會拿30個序列號放到緩存中,實例重啟后,緩存中的序列就會消失。
insert into toys(toyid,toyname,toyprice)
values(toy_seq.nextval,'snowboy',92);
.
3、更改序列
Alter sequence命令用于修改序列的定義。如果要進行下列操作,則會修改序列。
設置或刪除MINVALUE 或MAXVALUE
修改增量值
修改緩存中的序列號的數目不能更改序列的START WITH參數
.
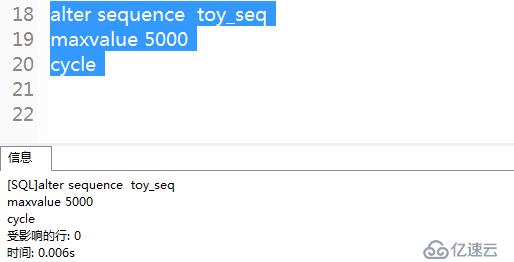
例3: 設置一個新的MAXVALUE,并為toy_seq序列打開了CYCLE。
ALTER SEQUENCE toys_seq MAXVALUE 5000 CYCLE;
.
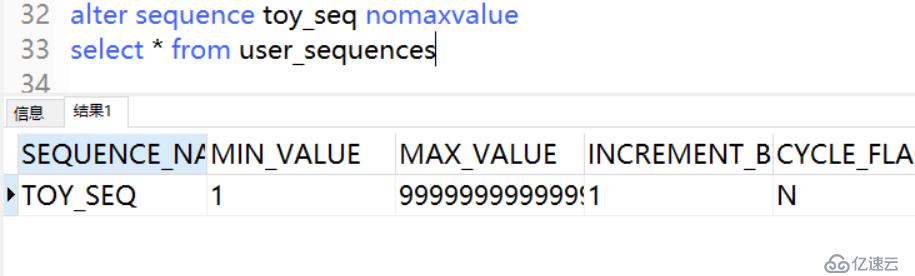
例4:修改序列為沒有最大封頂值
.
例5:將每次增量設置為10
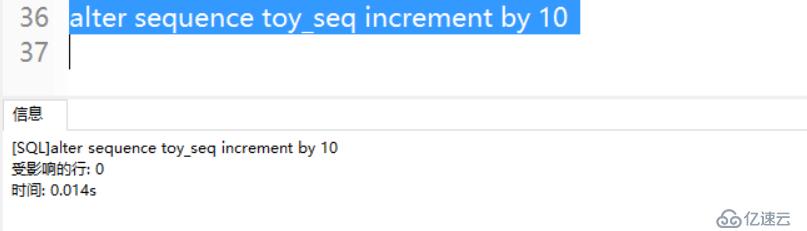
.
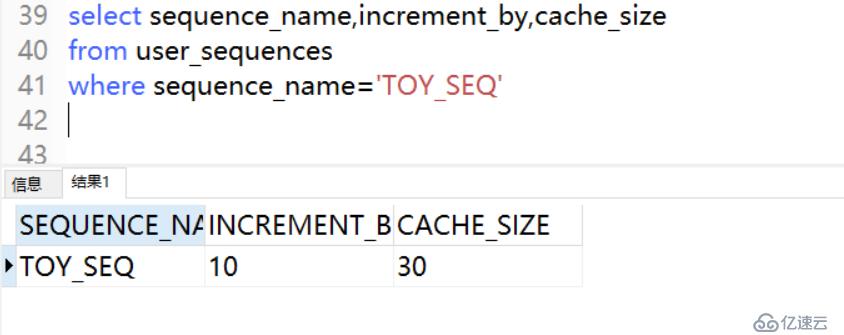
4、查看序列
可以通過查詢名為USER_SEQUENCES的數據字典視圖,來獲取用戶所創建的序列的詳細信息。
.
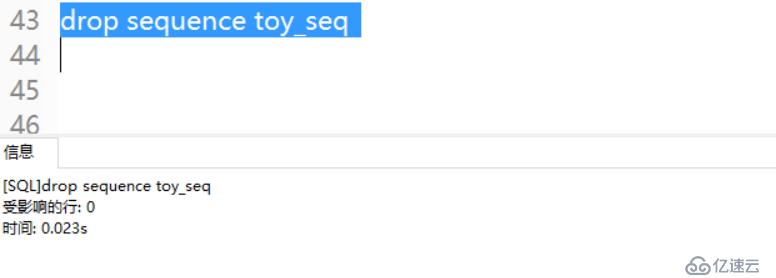
5、刪除序列
DROP SEQUENCE命令用于刪除序列。
DROP SEQUENCE toys_seq;
.
同義詞
同義詞是對象的一個別名,不占用任何的實際存儲空間,只在oracle的數據字典中保存其定義描述,在使用同義詞時,oracle會將其翻譯為對應對象的名稱。
1、同義詞的用途
1)簡化sql語句
如果用戶創建的表的名字很長,可以為這個表創建一個oracle同義詞來簡化語句。
2)隱藏對象的名稱和所有者
多用戶協同開發中,可以屏蔽對象的名稱及持有者。如果沒有同義詞,當操作其他用戶的表時,必須通過“用戶名.表名”的形式操作,采用了oracle同義詞之后就可以隱藏掉用戶名。例如:用戶user1要訪問用戶的SCOTT的EMP表,必須使用SCOTT.emp來引用。如果為用戶創建一個名為emp的同義詞代表SCOTT.emp,那么user1就可以用該同義詞像訪問自己的表一樣引用SCOTT.emp了。
3)為分布式數據庫的遠程對象提供位置透明性
要完成遠程對象的訪問,先要了解數據庫連接的概念。數據庫鏈接是一個命名的對象,說明一個數據庫到另一個數據庫的路徑,通過其可以實現不同的數據庫之間的通信。同義詞在數據庫鏈接中的作用就是提供位置透明性。
4)提供對數據庫對象的公共訪問
公有同義詞只是為數據庫對象定義了一個公共的別名,即其他用戶都可以通過這個別名訪問,但能夠通過該別名訪問成功,還要看是否已經具有數據庫對象的訪問權限。
.2、同義詞的分類
同義詞分為以下兩類:私有同義詞和公有同義詞
私有同義詞只能在其模式內訪問,且不能與當前模式的對象同名
公有同義詞可被所有的數據庫用戶訪問
.2-1:私有同義詞
私有同義詞只能被當前模式的用戶訪問,私有同義詞名稱不可與當前模式的對象名稱相同。要在自身的模式創建私有同義詞,用戶必須擁有create synonym系統權限。要在其他用戶模式創建私有同義詞,用戶必須擁有create any synonym系統權限。2)創建私有同義詞的語法如下:
CREATE OR REPLACE SYNONYM [schema.]synonym_name FOR [schema.]object_name;synonym_name:要創建同義詞的名稱
object_name:指定要為之創建同義詞的對象的名稱。
.
例1:在SYSTEM模式下創建私有同義詞訪問SCOTT模式下EMP表。
1)以SYSTEM用戶身份登錄數據庫,并訪問SCOTT下的EMP表。
.
SQL> conn system/123456
SQL>select * from scott.emp;
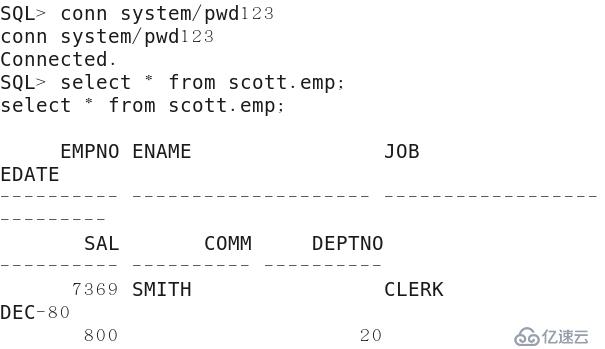
由上圖可以看出,使用模式名確實實現了查詢,但卻暴露了emp表的模式信息,使用私有同義詞可以避免這個問題。
.
2)以SYSTEM身份登錄數據庫,創建同義詞。SQL> create synonym SY_EMP for scott.emp;
。
3)訪問同義詞sy_emp,實際訪問的是SCOTT的emp表(隱藏了真實的表名,提高了安全性)
select * from sy_emp;
.
例2:訪問網絡服務名為orclsv的遠程數據庫中的表scott.emp
(我這里只有一臺服務器,所以我就把自己當做遠程服務器,效果是一樣的)
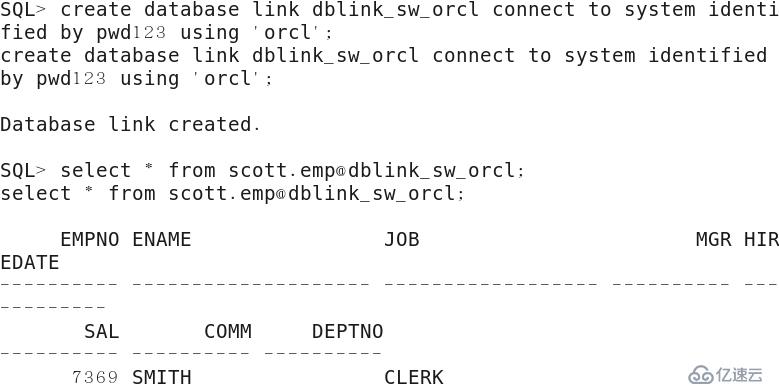
1)以SYSTEM用戶身份登錄數據庫,創建數據庫連接dblink_sw_orcl來連接遠程數據庫,其中遠程數據庫用戶名為system,密碼為pwd123,本地網絡服務器名為orcl,最后查詢遠程數據庫中的表emp。SQL> create database link dblink_sw_orcl connect to system identified by pwd123 using 'orcl';
SQL> select * from scott.emp@dblink_sw_orcl;
.
2)創建私有同義詞sy_t作為遠程數據庫表emp的別名
SQL> create synonym sy_t FOR scott.emp@dblink_sw_orcl;
。3)訪問同義詞sy_t,對應的是遠程數據庫中的表。
SQL> select * from sy_t;
。
.
.
.
公有同義詞
公有同義詞被所有的數據庫訪問。公有同義詞可以隱藏基表的身份,并降低sql語句的復雜性。要創建公有公有同義詞,用戶必須擁有create public SYNOYM的系統權限。
例3:在scott模式下對部門表dept創建公有同義詞public_sy_dept,目的是使其他用戶可以直接訪問public_sy_dept。
注意:如果不創建公有同義詞,那么其他用戶訪問scott模式下創建的同義詞,一定要加scott前綴,即SCOTT.xxx。如果創建了公有同義詞,同義詞有了公有屬性,那么其他用戶都可以使用了。
1)以system用戶身份登錄數據庫,將創建公有同義詞權限給SCOTT用戶。
.
SQL> grant create public synoym to scott;

.
2)以SCOTT用戶身份登錄數據庫
.
SQL> conn soctt/123456
.3)將查詢tmp權限給ydw
SQL> gran select on dept to ydw;
.
.
4)創建公有同義詞PUBLIC_SY_DEPT作為SCOTT用戶dept表的別名
SQL> create public synonym public_sy_dept FOR dept;

.
5)以ydw身份登錄數據庫
SQL> conn ydw/123456
SQL> select * from public_sy_dept;
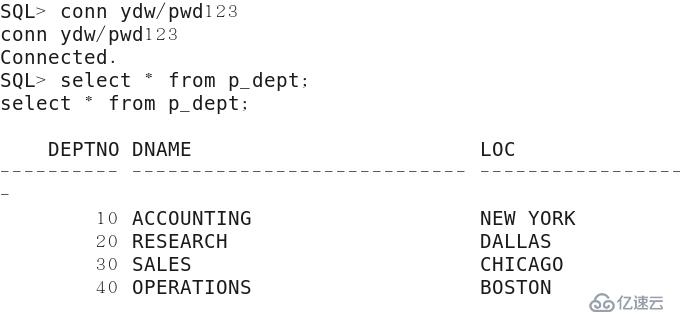
.
3、刪除同義詞
要刪除同義詞,用戶必須擁有相應的權限。
例:刪除同義詞sy_emp和公有同義詞public_sy_dept,可以執行如下語句。SQL> drop synonym sy_emp;
SQL> drop public synonym public_sy_dept;
.
分區表
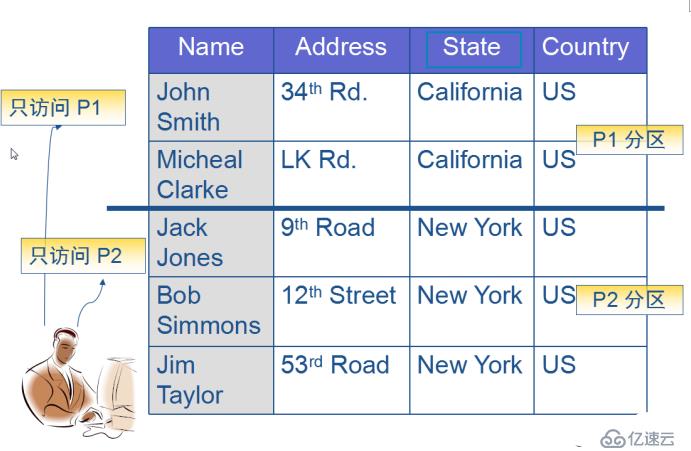
1、分區表的含義
Oracle允許把一個表重的所有行分成幾個部分,并將它們存儲在不通的表空間,分成的每一部分成為一個分區,被分區的表成為分區表。
.
對于包含大量數據的表來說,分區很有用,優點有以下幾點:
1)改善表的查詢性能。在對表進行分區后,用戶執行sql查詢時可以只訪問表中的特定分區而非整個表。
2)表更容易管理。因為分區表的數據存儲在多個部分中,按分區加載和刪除數據比在表中加載和刪除更容易。
3)便于備份和恢復。可以獨立地備份和恢復每個分區。
4)提高數據安全性。將不同的分區分布在不同的磁盤,可以減少所有分區的數據同時損壞的可能性。
.復合一下條件的表可以建成分區表:
1)數據量大于2GB。
2)已有的數據和新添加的數據有明顯的界限劃分。
表分區對用戶是透明的,及應用程序可以不知道表已被分區,在更新和查詢分區表時當做普通表來操作,但oracle優化程序知道表已被分區。
.
注意:要分區的表不能具有LONG和LONG RAW數據類型的列。
.
分區表的分類
Oracle提供的分區方法有范圍分區、列表分區、散列分區、復合分區、間隔分區和虛擬列分區等。其中間隔分區和虛擬列分區是oracle11g的新特性
.
范圍分區案例:
是一種常用的表分區方法,它是oracle引進的第一個分區類型。范圍分區用于可以根據某些條件按范圍分開的數據。如果數據均勻的分布在所建立的不同的范圍內,那么使用范圍分區將得到最好的分區效果。范圍可以基于順序數或部分數,范圍分區技術通常基于時間(例如月或季度)
1)創建表并且分區,以age分區。create table student(
id number,
name varchar2(10),
age number )partition by range (age)
( partition p100 values less than (10),
partition p200 values less than (20), )

.
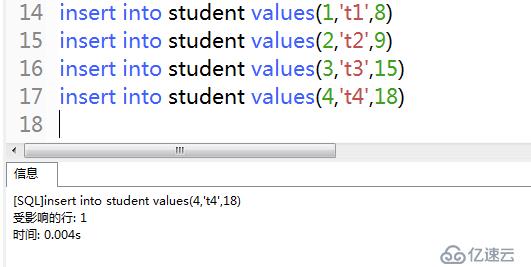
2)向表中插入數據
insert into student values(1,'t1',8)
insert into student values(2,'t2',9)
insert into student values(3,'t3',15)
insert into student values(4,'t4',18)
.
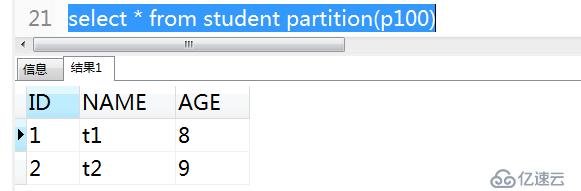
3)查詢P100區的數據
select from student partition(p100)*
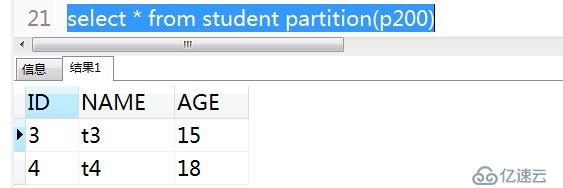
查詢p200區的數據
.
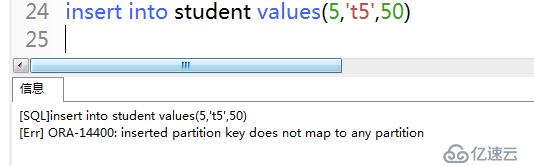
4)如果向表中插入以下記錄,會提示插入的分區關鍵字未映射到任何分區
insert into student values(5,'t5',50)
.
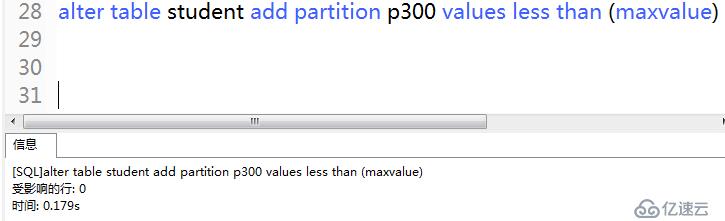
5)按范圍分區是,如果某些記錄暫時無法預測范圍,可以創建maxvalue分區,所有不在指定范圍內的記錄都會被存儲到maxvalue所在的分區中。
alter table student add partition p300 values less than (maxvalue)
.
6)再次插入以下數據
insert into student values(5,'t5',50)
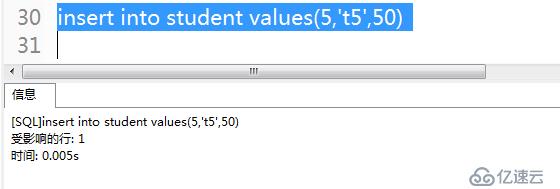
.
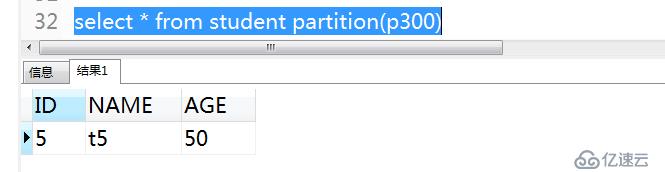
7)查詢
select * from student partition(p300)
.
8)查看所有分區的命令
select partition_name,table_name
from user_tab_partitions
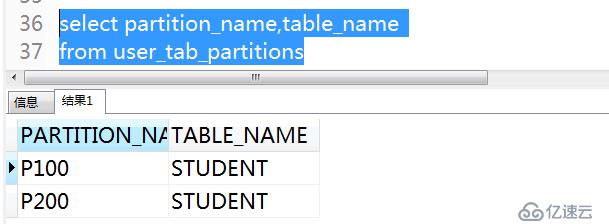
一般創建范圍分區時都會將最后一個分區設置為maxvalue,將其他數據落入此分區,一旦需要時可以利用拆分分區的技術將需要的數據從最后一個分區分離出入,單獨形成一個分區,如果沒有創建最大的分區,插入的數據查出范圍就會報錯。如果插入的數據是分區鍵上的值,則該數據落入下一個分區,例如:插入數據為10就會落入p200分區。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。