溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文主要給大家介紹線上mysql主從架構恢復異常案例分析,文章內容都是筆者用心摘選和編輯的,線上mysql主從架構恢復異常案例分析具有一定的針對性,對大家的參考意義還是比較大的,下面跟筆者一起了解下主題內容吧。
前提:之前一位同事負責的一位客戶,因后期轉到devops小組。所以將此用戶交接給我,在后期發現有一套數據庫主從環境,從庫已經無法正常使用。查看slave 狀態為: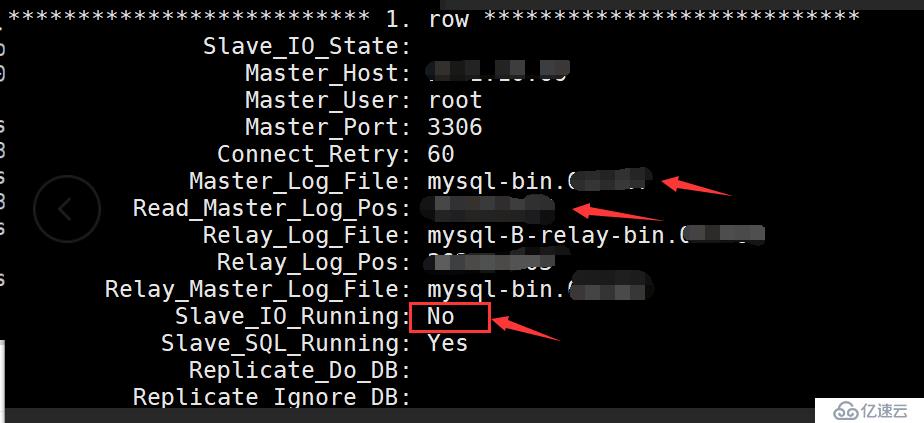
其中:
Master_Log_File:#此處顯示的bin-log已經在master上找不見了
Read_Master_Log_Pos:#顯示的行數也就存在沒有意義了
Slave_IO_Running:NO #salve io進程顯示為no,無法從master同步數據
因此判定從庫已經無法使用,需要及時修復。保證主從架構正常使用。
以下是恢復的全部過程:
##########################################################
主要思路:
1、在不鎖表的情況下備份master數據庫的所有數據文件
2、將slave數據庫進程停掉。并將備份文件從master傳輸到slave端,解壓
3、重新執行 change master設置bin-log文件名稱,和position
##########################################################一、在數據庫的Master端使用percona-xtrabackup進行文件級別的數據庫備份。
在master數據庫執行下面命令:(需要根據實際情況修改)
innobackupex --defaults-file=/etc/my.cnf --user=root --password=51idc --no-lock --use-memory=4G --compress --compress-threads=8 --stream=xbstream --parallel=4 /backup > /backup/$(date +%Y-%m-%d_%H-%M-%S).xbstream
注意:其中
1、/backup這個目錄可以自定義,他代表備份文件存放的位置。
2、/etc/my.cnf這個文件是數據庫啟動時讀取的默認配置文件,需要根據實際情況進行修改;我這邊使用的是/etc/my.cnf
3、修改數據庫連接密碼
4、--no-lock代表不鎖表進行備份,保證線上業務正常運行的同時進行數據備份。
這個操作時間依據數據量的大小,我自己備份花費了30min左右(130G數據)。備份完成后出現一個文件:
2019-02-27_11-12-21.xbstream
二、在數據庫的slave端使用命令進行恢復數據,因為在恢復之前需要保證主從數據庫的數據一致,但是之前因為從數據庫很久都沒有同步master的數據了,因此目前主從數據量差的較多。
a、需要先停掉數據庫
/etc/init.d/mysql stop #停掉數據庫
b、刪除之前的數據文件,默認在/var/lib/mysql下;刪除mysql目錄下的所有文件,因為接下來我們需要將備份數據解壓到此目錄下。
c、在slave數據庫的機器上執行兩次解壓操作,將備份文件解壓到本地。
xbstream -x < /backup/2019-02-27_11-12-21.xbstream -C /backup/2019-02-27_11-12-21
innobackupex --decompress --parallel=4 /backup/2019-02-27_11-12-21
d、刪除所有以 .qp結尾的文件
find /backup/2019-02-27_11-12-21 -name "*.qp" -delete
e、創建完備份之后數據被沒有馬上可以被還原,需要回滾未提交事務前滾提交事務,讓數據庫文件保持一致性。
innobackupex使用—apply-log來做預備備份
--user-memory:指定預備階段可使用的內存,內存多則速度快,默認為10MB
innobackupex --apply-log --use-memory=4G /backup/2016-03-16_15-25-55
f、再將還原的數據文件拷貝到/var/lib/mysql目錄下,其中/var/lib/mysql目錄在/etc/my.cnf文件中指定的datadir
innobackupex --defaults-file=/etc/my.cnf --copy-back --use-memory=4G /backup/2019-02-27_11-12-21
此過程需要的時間較長,我這邊還原大概是2H左右。還原完成后,在/var/lib/mysql目錄下有兩個文件,可以看到salve目前保存的最近的bin-log文件和position
若出現找不到qpress命令的報錯可以安裝repo.percona源后使用 yum -y install qpress 進行安裝
repo.percona源安裝命令:
yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm
g、修改/var/lib/mysql的屬主屬組
chown -R mysql.mysql /var/lib/mysql
h、啟動數據庫;
/etc/init.d/mysql start
I、重做主從配置
mysql -uroot -p #進入到數據庫內
change master to master_host='主xxx.xxx.xxx.xx',master_port=3306,master_user='root',master_password='51idc',master_lo_file='master-bin.xxx',master_log_pos=xxx;
其中:master IP 、master_password根據實際情況確定。
bin-log日志文件名、master_log_pos的位置需要在這兩個文件中查看。
h、啟動slave
mysql> start slave;
j、查看slave狀態:
mysql> show slave status\G;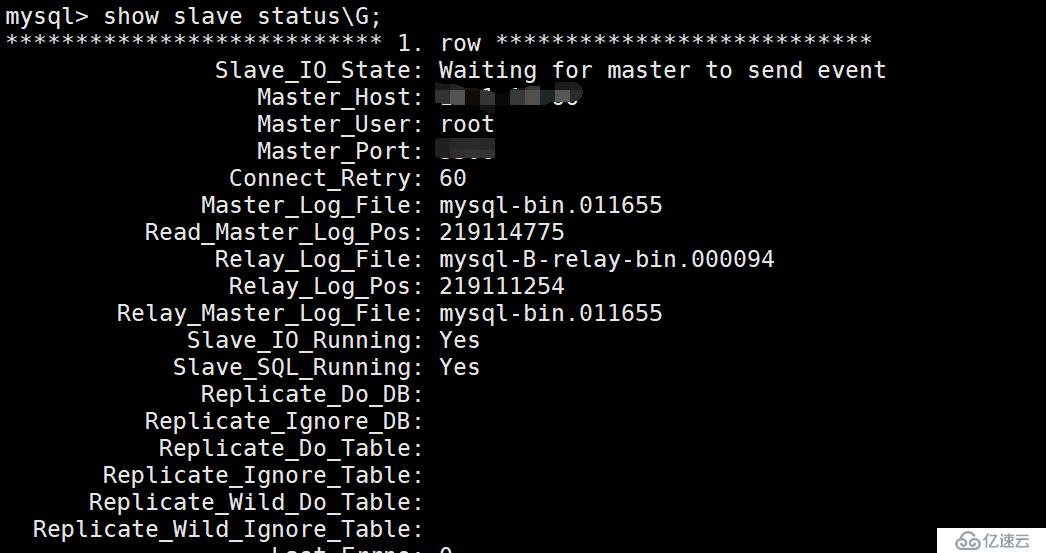
可以看到從數據庫slave的Slave_IO_Running: Yes、Slave_SQL_Running: Yes均是yes
并且有了新的bin-log文件和position位置了。后面就可以正常工作,進行主從同步了。
看完以上關于線上mysql主從架構恢復異常案例分析,很多讀者朋友肯定多少有一定的了解,如需獲取更多的行業知識信息 ,可以持續關注我們的行業資訊欄目的。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





