溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
下文內容主要給大家帶來SQL執行順序講析,這里所講到的知識,與書籍略有不同,都是億速云專業技術人員在與用戶接觸過程中,總結出來的,具有一定的經驗分享價值,希望給廣大讀者帶來幫助。
一、手寫SQL順序
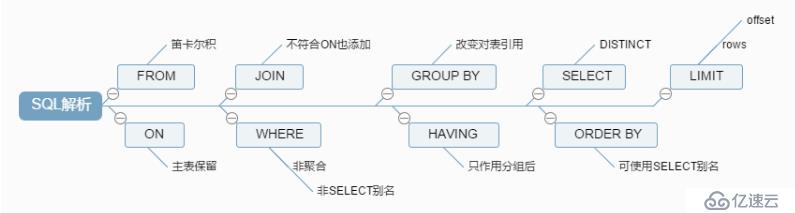
select <select_list> from <table_name> <join_type> join <join_table> on <join_condition> where <where_condition> group by <group_by_list> having <having_condition> order by <order_by_condition> limit <limt_number>
二、MySql執行順序

from <left table> on <on_condition> <join_type> join <join_table> where <where_condition> group by <group_by_list> <sum()avg()等聚合函數> having <having_condition> select <select_list> distinct order by <order_by_condition> limit <limit_number>
三、MySql執行順序理解
第一步:加載from子句的前兩個表計算笛卡爾積,生成虛擬表vt1;
第二步:篩選關聯表符合on表達式的數據,保留主表,生成虛擬表vt2;
第三步:如果使用的是外連接,執行on的時候,會將主表中不符合on條件的數據也加載進來,做為外部行
第四步:如果from子句中的表數量大于2,則重復第一步到第三步,直至所有的表都加載完畢,更新vt3;
第五步:執行where表達式,篩選掉不符合條件的數據生成vt4;
第六步:執行group by子句。group by 子句執行過后,會對子句組合成唯一值并且對每個唯一值只包含一行,生成vt5,。一旦執行group by,后面的所有步驟只能得到vt5中的列(group by的子句包含的列)和聚合函數。
第七步:執行聚合函數,生成vt6;
第八步:執行having表達式,篩選vt6中的數據。having是唯一一個在分組后的條件篩選,生成vt7;
第九步:從vt7中篩選列,生成vt8;
第十步:執行distinct,對vt8去重,生成vt9。其實執行過group by后就沒必要再去執行distinct,因為分組后,每組只會有一條數據,并且每條數據都不相同。
第十一步:對vt9進行排序,此處返回的不是一個虛擬表,而是一個游標,記錄了數據的排序順序,此處可以使用別名;
第十二步:執行limit語句,將結果返回給客戶端
四、其他
1、on和where的區別?
簡單地說,當有外關聯表時,on主要是針對外關聯表進行篩選,主表保留,當沒有關聯表時,二者作用相同。
例如在左外連時,首先執行on,篩選掉外連表中不符合on表達式的數據,而where的篩選是對主表的篩選。
2、圖解
對于以上關于SQL執行順序講析,如果大家還有更多需要了解的可以持續關注我們億速云的行業推新,如需獲取專業解答,可在官網聯系售前售后的,希望該文章可給大家帶來一定的知識更新。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





