溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關如何分析基于結構化平均感知機的分詞器Java實現,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
基于結構化平均感知機的分詞器Java實現
最近高產似母豬,寫了個基于AP的中文分詞器,在Bakeoff-05的MSR語料上F值有96.11%。最重要的是,只訓練了5個迭代;包含語料加載等IO操作在內,整個訓練一共才花費23秒。應用裁剪算法去掉模型中80%的特征后,F值才下降不到0.1個百分點,體積控制在11兆。如果訓練一百個迭代,F值可達到96.31%,訓練時間兩分多鐘。
數據在一臺普通的IBM兼容機上得到:

本模塊已集成到HanLP 1.6以上版本開源,文檔位于項目wiki中,歡迎使用!【hanlp1.7新版本已經發布,可以去新版本查到看使用】
結構化預測
關于結構化預測和非結構化預測的區別一張講義說明如下:
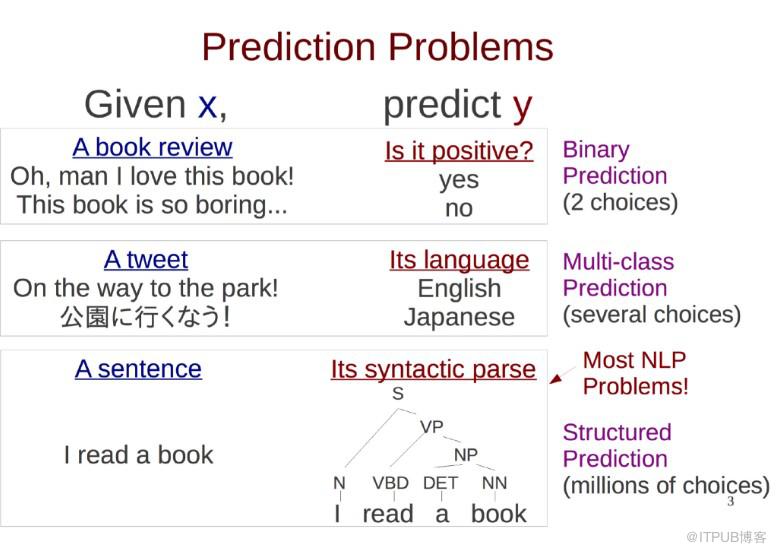
更多知識請參考Neubig的講義《The Structured Perceptron》。
本文實現的AP分詞器預測是整個句子的BMES標注序列,當然屬于結構化預測問題了。
感知機
二分類
感知機的基礎形式如《統計學習方法》所述,是定義在一個超平面上的線性二分類模型。作為原著第二章,實在是簡單得不能再簡單了。然而實際運用中,越簡單的模型往往生命力越頑強。
這里唯一需要補充的是,感知機是個在線學習模型,學習一個訓練實例后,就可以更新整個模型。
多分類
怎么把二分類拓展到多分類呢?可以用多個分類器,對于BMES這4種分類,就是4個感知機了。每個感知機分別負責分辨“是不是B”“是不是M”“是不是E”“是不是S”這4個二分類問題。在實現中,當然不必傻乎乎地創建4個感知機啦。把它們的權值向量拼接在一起,就可以輸出“是B的分數”“是M的分數”“是E的分數”“是S的分數”了。取其最大者,就可以初步實現多分類。但在分詞中,還涉及到轉移特征和HMM-viterbi搜索算法等,留到下文再說。
平均感知機
平均感知機指的是記錄每個特征權值的累計值,最后平均得出最終模型的感知機。為什么要大費周章搞個平均算法出來呢?
前面提到過,感知機是個在線學習模型,學習一個訓練實例后,就可以更新整個模型。假設有10000個實例,模型在前9999個實例的學習中都完美地得到正確答案,說明此時的模型接近完美了。可是最后一個實例是個噪音點,樸素感知機模型預測錯誤后直接修改了模型,導致前面9999個實例預測錯誤,模型訓練前功盡棄。
有什么解決方案呢?一種方案是投票式的,即記錄每個模型分類正確的次數,作為它的得票。訓練結束時取得票最高的模型作為最終模型。但這種算法是不實際的,如果訓練5個迭代,10000個實例,那么就需要儲存50000個模型及其票數,太浪費了。
最好用的方法是平均感知機,將這50000個模型的權值向量累加起來,最后除以50000就行了,這樣任何時候我們只額外記錄了一個累加值,非常高效了。關于平均感知機的詳情請參考《200行Python代碼實現感知機詞性標注器》。雖然那篇文章是講解詞性標注的,但相信作為萬物靈長的讀者一定擁有舉一反三的泛化能力。
語言模型
HMM
我們不是在講解感知機分詞嗎?怎么跟HMM扯上關系了?
其實任何基于序列標注的分詞器都離不開隱馬爾科夫鏈,即BMES這四個標簽之間的Bigram(乃至更高階的n-gram)轉移概率。作為其中一員的AP分詞器,也不例外地將前一個字符的標簽作為了一個特征。該特征對預測當前的標簽毫無疑問是有用的,比如前一個標簽是B,當前標簽就絕不可能是S。
這種類似于y[i-1]的特征在線性圖模型中一般稱為轉移特征,而那些不涉及y[i-1]的特征通常稱為狀態特征。
viterbi
由于AP分詞器用到了轉移特征,所以肯定少不了維特比搜索。從序列全體的準確率考慮,搜索也是必不可少的。給定隱馬爾可夫模型的3要素,我用Java寫了一段“可運行的偽碼”:
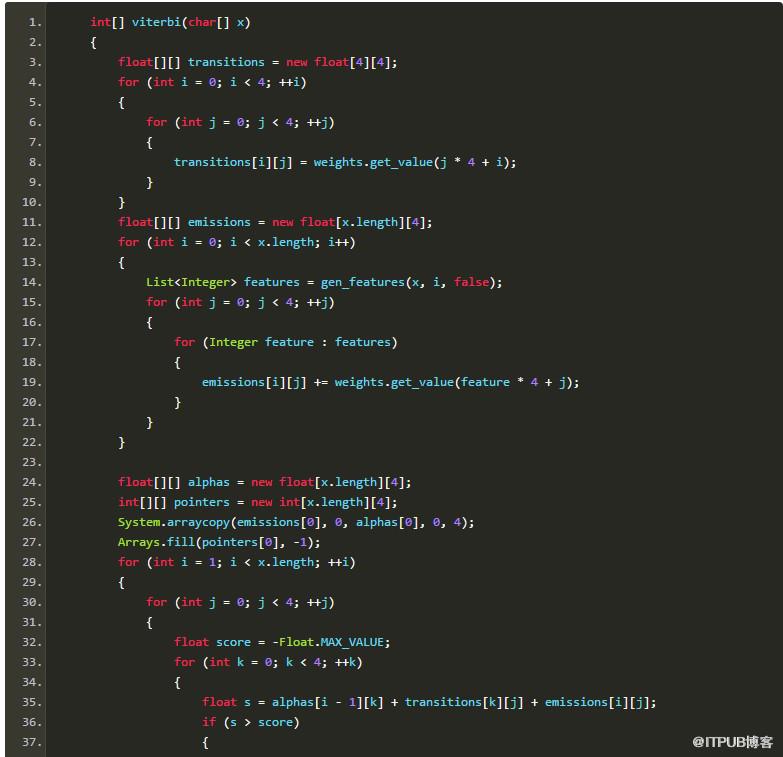
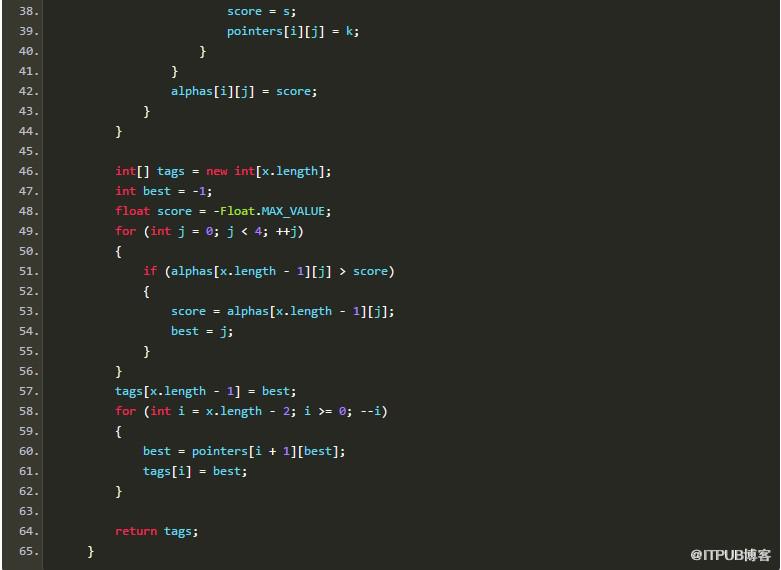
上述實現是個重視條理勝于效率的原型,古人云“過早優化是魔鬼”。相信聰明的讀者一定能看懂這里面在干什么。
特征提取
定義字符序列為x,標注序列為y。
轉移特征
轉移特征就是上面說的y[i-1]。
狀態特征
我一共使用了7種狀態特征:

在鄧知龍的《基于感知器算法的高效中文分詞與詞性標注系統設計與實現》中提到,要利用更復雜的字符n-gram、字符類別n-gram、疊字、詞典等特征。但在我的實踐中,除了上述7種特征外,我每減少一個特征,我的AP分詞器的準確率就提高一點,也許是語料不同吧,也許是特征提取的實現不同。總之,主打精簡、高效。
訓練
迭代數目其實不需要太多,在3個迭代內模型基本就收斂了:
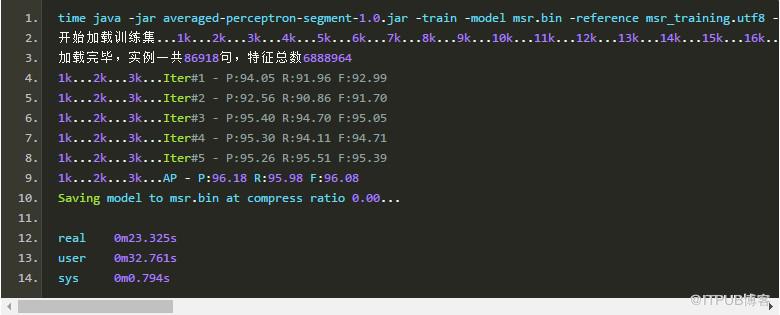
第4個迭代似乎幫了倒忙,但萬幸的是,我們使用的是平均感知機。權值平均之后,模型的性能反而有所提升。
此時模型大小:

模型裁剪
《基于感知器算法的高效中文分詞與詞性標注系統設計與實現》提到的模型裁剪策略是有效的,我將壓縮率設為0.2,即壓縮掉20%的特征,模型準確率沒有變化:
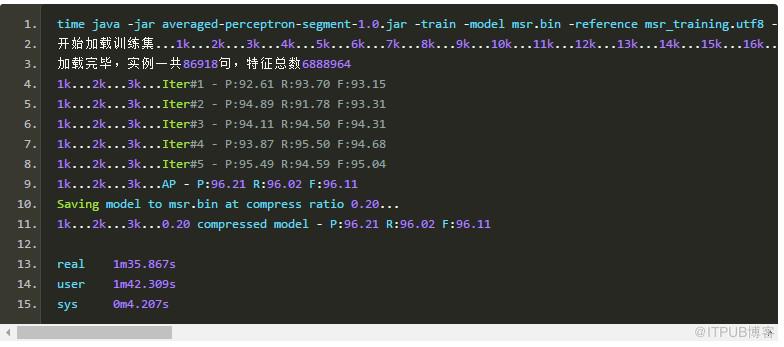
由于我使用了隨機shuffle算法,所以每次訓練準確率都略有微小的上下波動。此時可以看到模型裁剪過程花了額外的1分鐘,裁剪完畢后準確率維持96.11不變。
此時模型大小:

裁減掉50%如何呢?
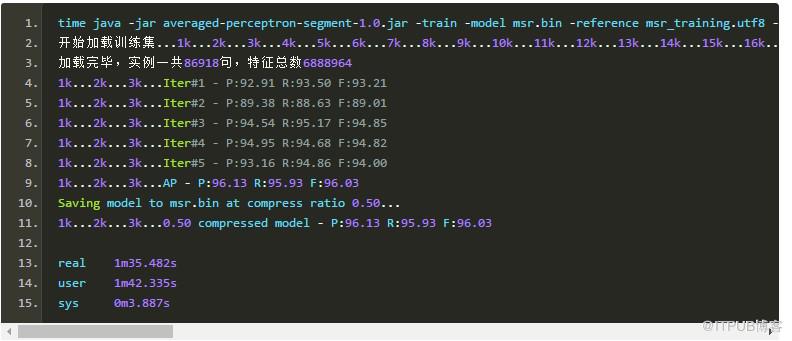
此時模型大小:
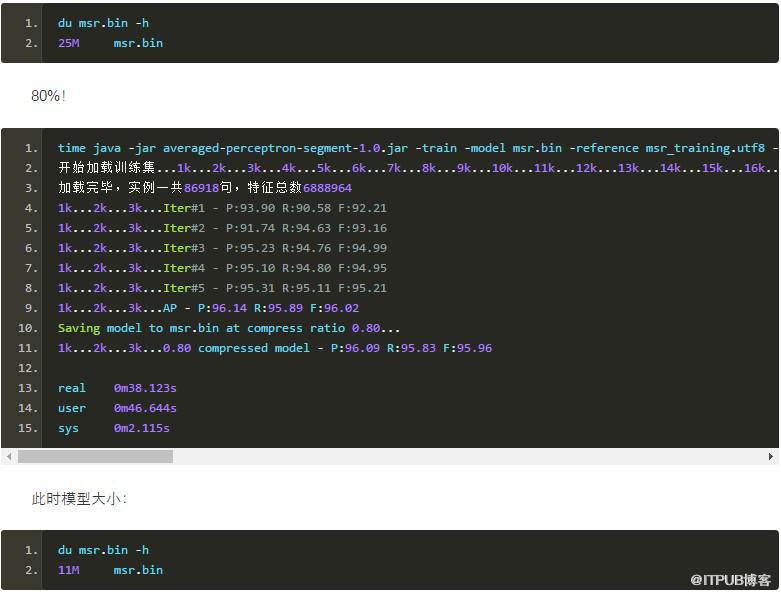
可見裁剪了80%的特征,體積從54M下降到11M,模型的準確率才跌了不到0.1個百分點!這說明大部分特征都是沒用的,特征裁剪非常有用、非常好用!
以上就是如何分析基于結構化平均感知機的分詞器Java實現,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





