溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

大數據文摘授權轉載自數據派THU
作者:Prateek Joshi
翻譯:王威力
校對:丁楠雅
TextRank 算法是一種用于文本的基于圖的排序算法,通過把文本分割成若干組成單元(句子),構建節點連接圖,用句子之間的相似度作為邊的權重,通過循環迭代計算句子的TextRank值,最后抽取排名高的句子組合成文本摘要。本文介紹了抽取型文本摘要算法TextRank,并使用Python實現TextRank算法在多篇單領域文本數據中抽取句子組成摘要的應用。
介紹
文本摘要是自然語言處理(NLP)的應用之一,一定會對我們的生活產生巨大影響。隨著數字媒體的發展和出版業的不斷增長,誰還會有時間完整地瀏覽整篇文章、文檔、書籍來決定它們是否有用呢?值得高興的是,這項技術已經在這里了。
你有沒有用過inshorts這個手機app?它是一個創新的新聞app,可以將新聞文章轉化成一篇60字的摘要,這正是我們將在本文中學習的內容——自動文本摘要。
自動文本摘要是自然語言處理(NLP)領域中最具挑戰性和最有趣的問題之一。它是一個從多種文本資源(如書籍、新聞文章、博客帖子、研究類論文、電子郵件和微博)生成簡潔而有意義的文本摘要的過程。
由于大量文本數據的可獲得性,目前對自動文本摘要系統的需求激增。
通過本文,我們將探索文本摘要領域,將了解TextRank算法原理,并將在Python中實現該算法。上車,這將是一段有趣的旅程!
目錄
一、文本摘要方法
二、TextRank算法介紹
三、問題背景介紹
四、TextRank算法實現
五、下一步是什么?
一、文本摘要方法
早在20世紀50年代,自動文本摘要已經吸引了人們的關注。在20世紀50年代后期,Hans Peter Luhn發表了一篇名為《The automatic creation of literature abstract》的研究論文,它利用詞頻和詞組頻率等特征從文本中提取重要句子,用于總結內容。
參考鏈接:
http://courses.ischool.berkeley.edu/i256/f06/papers/luhn58.pdf
另一個重要研究是由Harold P Edmundson在20世紀60年代后期完成,他使用線索詞的出現(文本中出現的文章題目中的詞語)和句子的位置等方法來提取重要句子用于文本摘要。此后,許多重要和令人興奮的研究已經發表,以解決自動文本摘要的挑戰。
參考鏈接:
http://courses.ischool.berkeley.edu/i256/f06/papers/luhn58.pdf
文本摘要可以大致分為兩類——抽取型摘要和抽象型摘要:
抽取型摘要:這種方法依賴于從文本中提取幾個部分,例如短語、句子,把它們堆疊起來創建摘要。因此,這種抽取型的方法最重要的是識別出適合總結文本的句子。
抽象型摘要:這種方法應用先進的NLP技術生成一篇全新的總結。可能總結中的文本甚至沒有在原文中出現。
本文,我們將關注于抽取式摘要方法。
二、TextRank算法介紹
在開始使用TextRank算法之前,我們還應該熟悉另一種算法——PageRank算法。事實上它啟發了TextRank!PageRank主要用于對在線搜索結果中的網頁進行排序。讓我們通過一個例子快速理解這個算法的基礎。
PageRank算法簡介:
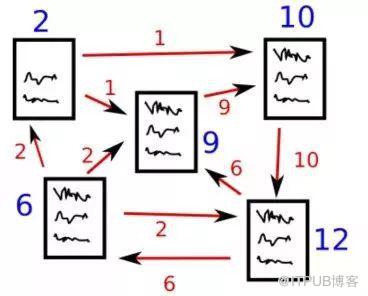
圖 1 PageRank算法
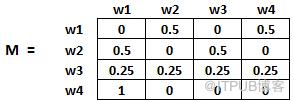
假設我們有4個網頁——w1,w2,w3,w4。這些頁面包含指向彼此的鏈接。有些頁面可能沒有鏈接,這些頁面被稱為懸空頁面。
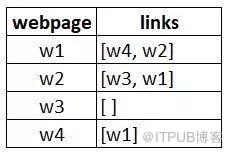
w1有指向w2、w4的鏈接
w2有指向w3和w1的鏈接
w4僅指向w1
w3沒有指向的鏈接,因此為懸空頁面
為了對這些頁面進行排名,我們必須計算一個稱為PageRank的分數。這個分數是用戶訪問該頁面的概率。
為了獲得用戶從一個頁面跳轉到另一個頁面的概率,我們將創建一個正方形矩陣M,它有n行和n列,其中n是網頁的數量。
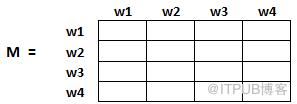
矩陣中得每個元素表示從一個頁面鏈接進另一個頁面的可能性。比如,如下高亮的方格包含的是從w1跳轉到w2的概率。
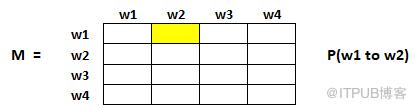
如下是概率初始化的步驟:
1. 從頁面i連接到頁面j的概率,也就是M[i][j],初始化為1/頁面i的出鏈接總數wi
2. 如果頁面i沒有到頁面j的鏈接,那么M[i][j]初始化為0
3. 如果一個頁面是懸空頁面,那么假設它鏈接到其他頁面的概率為等可能的,因此M[i][j]初始化為1/頁面總數
因此在本例中,矩陣M初始化后如下:
最后,這個矩陣中的值將以迭代的方式更新,以獲得網頁排名。
三、TextRank算法
現在我們已經掌握了PageRank,讓我們理解TextRank算法。我列舉了以下兩種算法的相似之處:
用句子代替網頁
任意兩個句子的相似性等價于網頁轉換概率
相似性得分存儲在一個方形矩陣中,類似于PageRank的矩陣M
TextRank算法是一種抽取式的無監督的文本摘要方法。讓我們看一下我們將遵循的TextRank算法的流程:
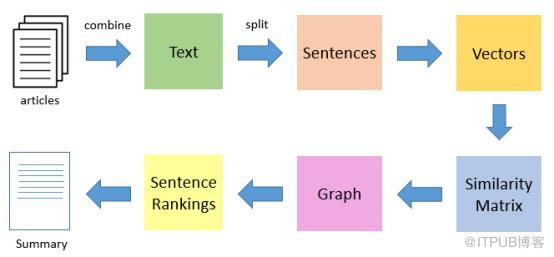
1. 第一步是把所有文章整合成文本數據
2. 接下來把文本分割成單個句子
3. 然后,我們將為每個句子找到向量表示(詞向量)。
4. 計算句子向量間的相似性并存放在矩陣中
5. 然后將相似矩陣轉換為以句子為節點、相似性得分為邊的圖結構,用于句子TextRank計算。
6. 最后,一定數量的排名最高的句子構成最后的摘要。
讓我們啟動Jupyter Notebook,開始coding!
備注:如果你想了解更多圖論知識,我推薦你參考這篇文章
https://www.analyticsvidhya.com/blog/2018/09/introduction-graph-theory-applications-python/
三、問題背景介紹
作為一個網球愛好者,我一直試圖通過對盡可能多的網球新聞的閱讀瀏覽來使自己隨時了解這項運動的最新情況。然而,事實證明這已經是一項相當困難的工作!花費太多的資源和時間是一種浪費。
因此,我決定設計一個系統,通過掃描多篇文章為我提供一個要點整合的摘要。如何著手做這件事?這就是我將在本教程中向大家展示的內容。我們將在一個爬取得到的文章集合的文本數據集上應用TextRank算法,以創建一個漂亮而簡潔的文章摘要。
請注意:這是一個單領域多文本的摘要任務,也就是說,我們以多篇文章輸入,生成的是一個單要點摘要。本文不討論多域文本摘要,但您可以自己嘗試一下。
數據集下載鏈接:
https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2018/10/tennis_articles_v4.csv
四、TextRank算法實現
所以,不用再費心了,打開你的Jupyter Notebook,讓我們實現我們迄今為止所學到的東西吧!
1. 導入所需的庫
首先導入解決本問題需要的庫

2. 讀入數據
現在讀取數據,在上文我已經提供了數據集的下載鏈接。

3. 檢查數據
讓我們快速了解以下數據。
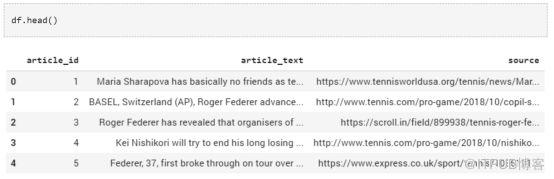
數據集有三列,分別是‘article_id’,‘article_text’,和‘source’。我們對‘article_text’列的內容最感興趣,因為它包含了文章的文本內容。讓我們打印一些這個列里的變量的值,具體看看它們是什么樣。

輸出:

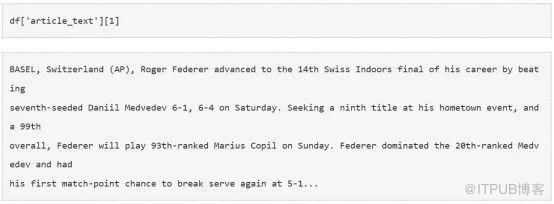
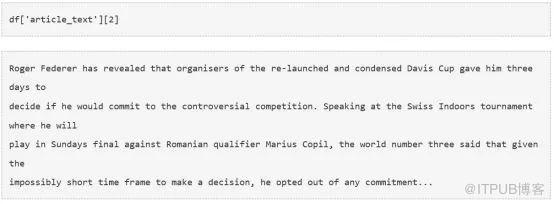
現在我們有兩種選擇,一個是總結單個文章,一個是對所有文章進行內容摘要。為了實現我們的目的,我們繼續后者。
4. 把文本分割成句子
下一步就是把文章的文本內容分割成單個的句子。我們將使用nltk庫中的sent_tokenize( )函數來實現。

打印出句子列表中的幾個元素。

輸出:

5. 下載GloVe詞向量
GloVe詞向量是單詞的向量表示。這些詞向量將用于生成表示句子的特征向量。我們也可以使用Bag-of-Words或TF-IDF方法來為句子生成特征,但這些方法忽略了單詞的順序,并且通常這些特征的數量非常大。
我們將使用預訓練好的Wikipedia 2014 + Gigaword 5 (補充鏈接)GloVe向量,文件大小是822 MB。
GloVe詞向量下載鏈接:
https://nlp.stanford.edu/data/glove.6B.zip

讓我們提取詞向量:
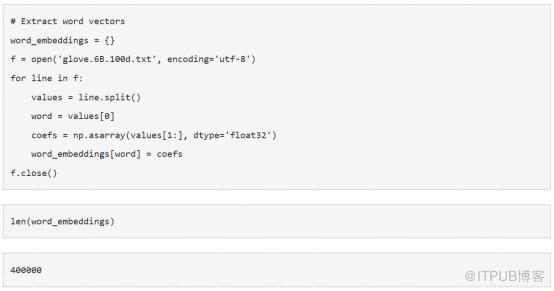
現在我們在字典中存儲了400000個不同術語的詞向量。
6. 文本預處理
盡可能減少文本數據的噪聲是一個好習慣,所以我們做一些基本的文本清洗(包括移除標點符號、數字、特殊字符,統一成小寫字母)。

去掉句子中出現的停用詞(一種語言的常用詞——is,am,of,in等)。如果尚未下載nltk-stop,則執行以下代碼行:

現在我們可以導入停用詞。

接下來定義移除我們的數據集中停用詞的函數。
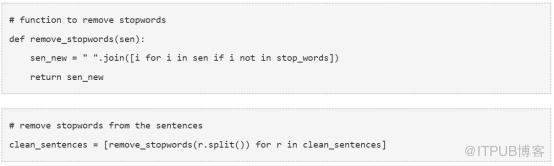
我們將在GloVe詞向量的幫助下用clean_sentences(程序中用來保存句子的列表變量)來為我們的數據集生成特征向量。
7. 句子的特征向量
現在,來為我們的句子生成特征向量。我們首先獲取每個句子的所有組成詞的向量(從GloVe詞向量文件中獲取,每個向量大小為100個元素),然后取這些向量的平均值,得出這個句子的合并向量為這個句子的特征向量。

8. 相似矩陣準備
下一步是找出句子之間的相似性,我們將使用余弦相似性來解決這個問題。讓我們為這個任務創建一個空的相似度矩陣,并用句子的余弦相似度填充它。
首先定義一個n乘n的零矩陣,然后用句子間的余弦相似度填充矩陣,這里n是句子的總數。

將用余弦相似度計算兩個句子之間的相似度。

用余弦相似度初始化這個相似度矩陣。

9. 應用PageRank算法
在進行下一步之前,我們先將相似性矩陣sim_mat轉換為圖結構。這個圖的節點為句子,邊用句子之間的相似性分數表示。在這個圖上,我們將應用PageRank算法來得到句子排名。

10. 摘要提取
最后,根據排名提取前N個句子,就可以用于生成摘要了。
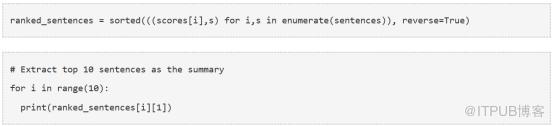

現在我們實現了一個棒極了、整齊的、簡潔、有用的文章總結!
五、下一步是什么?
自動文本摘要是一個熱門的研究課題,在本文中我們僅僅討論了冰山一角。展望未來,我們將探索抽象文本摘要技術,其中深度學習扮演著重要的角色。此外,我們還可以研究下面的文本摘要任務:
1. 問題導向:
多領域文本摘要
單個文檔的摘要
跨語言文本摘要
(文本來源是一種語言,文本總結用另一種語言)
2. 算法導向:
應用RNN和LSTM的文本摘要
應用加強學習的文本摘要
應用生成對抗神經網絡(GAN)的文本摘要
后記
我希望這篇文章能幫助你理解自動文本摘要的概念。它有各種各樣的應用案例,并且已經產生了非常成功的應用程序。無論是在您的業務中利用,還是僅僅為了您自己的知識,文本摘要是所有NLP愛好者都應該熟悉的方法。
我將在以后的文章中嘗試使用高級技術介紹抽象文本摘要技術。同時,請隨時使用下面的評論部分讓我知道你對這篇文章的想法或任何問題。
數據集下載鏈接:
https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2018/10/tennis_articles_v4.csv
算法代碼鏈接:
https://github.com/prateekjoshi565/textrank_text_summarization
相關報道:
https://www.analyticsvidhya.com/blog/2018/11/introduction-text-summarization-textrank-python/
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





