溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
1.?課程介紹
??1.介紹什么是mysql優化
??2.mysql優化方法
??3.Mysql索引的使用
??4.分表技術
2.?mysql優化概述
概述: 前面我們學習了頁面靜態化和redis,它們是通過不操作mysql數據庫達到提速目的。但是某些功能是一定要操作數據庫的,這就要求我們必須對mysql本身進行優化。
mysql數據庫優化的常見方法:
1.?表的設計要合理(滿足3NF) 3范式
2.?創建適當索引[主鍵索引|唯一索引|普通索引|全文索引|空間索引]
3.?對SQL語句優化---->定位慢查詢(explain)
4.?使用分表技術(重點【水平分表,垂直分表】), 分區技術(了解)
5.?讀寫分離(配置)
6.?創建適當存儲過程,函數,觸發器
7.?對my.ini優化,優化配置
8.?軟件硬件升級
3.?表的設計滿足3NF
概述: 目前我們的表的設計,最高級別的范式是"6NF",對PHP程序員而言,我們的表滿足3NF即可。
3.1.?1NF
所謂1NF,就是
(1)?指表的屬性(列)具有原子性, 即表的列的不能再分了。
?
(2)?不能有重復的列
?
特殊
(1)?只要是關系型數據庫,就天然的滿足1NF
(2)?常見數據庫
關系型數據庫(mysql, oracle, sql server,informix, db2 , postgres)
非關系型數據(Nosql類型的數據庫由Redis, MongoDB)
3.2.?2NF
所謂2NF,就是指我們的表中不能有完全重復的一條記錄(行).一般情況下通過設置一個主鍵來搞定,而且該主鍵是自增的。
3.3.?3NF(外鍵)
所謂3NF就是指,如果列的內容可以被推導(顯式推導,隱式推導)出,那么我們就不要單獨的用一列存放。
舉例:下面是滿足3NF
?
3.4.?反3NF
在通常情況下,我們的表的設計要嚴格的遵守3NF,但也有例外。有時為了提高查詢的效率,我們需要違反3NF。舉例: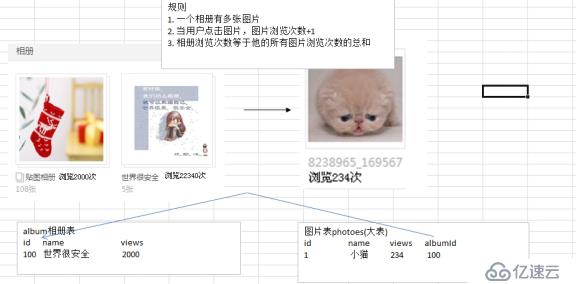
?
4.?構建海量表,定位慢查詢
為了講解這個優化,我們需要構建一個海量表(8000000),而且每條數據不一樣。
4.1.?構建海量表步驟
(1)?創建一個測試數據庫
?
(2)?創建表
CREATE TABLE dept( /部門表/
deptno ??MEDIUMINT ??UNSIGNED ?NOT NULL ?DEFAULT 0,
dname VARCHAR(20) ?NOT NULL ?DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
加入數據: dept.sql
?
#創建表EMP雇員
CREATE TABLE emp
(empno ?MEDIUMINT UNSIGNED ?NOT NULL ?DEFAULT 0, /編號/
ename VARCHAR(20) NOT NULL DEFAULT "", /名字/
job VARCHAR(9) NOT NULL DEFAULT "",/工作/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/上級編號/
hiredate DATE NOT NULL,/入職時間/
sal DECIMAL(7,2) ?NOT NULL,/薪水/
comm DECIMAL(7,2) NOT NULL,/紅利/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /部門編號/
)ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
加入數據:emp.sql
#工資級別表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) ?NOT NULL,
hisal DECIMAL(17,2) ?NOT NULL
)ENGINE=MyISAM DEFAULT CHARSET=utf8;
加入數據: salgrade.sql
4.2.?海量表帶來的問題
看一個案例
?
?
4.3.?先使用索引來搞定
l?給empno段添加主鍵索引
alter table emp add primary key (empno);
?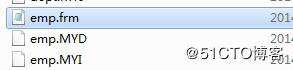
一個表(存儲引擎是MyISAM),對應三個文件 xx.frm 表結構 xx.MYD 數據文件 xx.MYI 索引文件
l?通過測試看效果
?
l?刪除emp表的主鍵索引
alter table emp drop primary key
4.4.?如何定位慢查詢(slow query)
介紹: 在默認情況下,mysql 是不會記錄慢查詢的,所以我們在測試時,可以指定mysql記錄慢查詢.
開啟慢查詢的兩種方法:
l?啟動時,這樣啟動
cmd>bin/mysqld.exe --safe-mode --slow-query-log?
?
或者是
在my.ini的[mysqld]下添加一下代碼并且重啟
log-slow-queries = D:/server/mysql/mysqlslowquery.log(注意斜杠)
注:mysql5.6版本slow-query-log-file
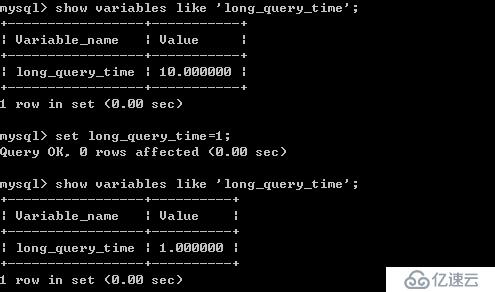
long_query_time = 1 指定超過1秒算慢查詢
l?為了測試,我們修改 long_query_time
?
?
l?記錄下慢查詢
?
use testdb;
SET timestamp=1416623985;
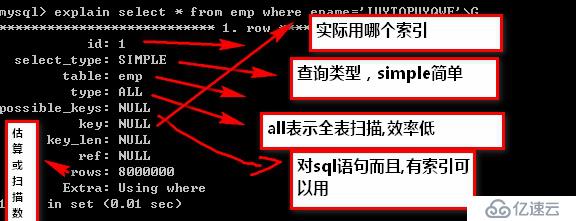
select * from emp where ename='IUYTOPUYQWE';
?
說明: Query_time是查詢的時間
Lock_time:等待時間
?
4.5.?開啟慢查詢犧牲sql的執行效率
如何使用慢查詢?
?
l?優化
添加索引。
?
4.7.?mysql的變量查詢
mysql>show variables;
mysql>show variables?like ‘%xxxx%’;
show ?tables ?like ?'數據表名';//查詢一個數據表是否存在
如果需要知道每個變量的具體含義,可以查詢手冊.
5.?索引的詳解(重點)
5.1.?索引創建
5.1.1.?主鍵索引的創建
主鍵索引的創建有兩種形式, 1.在創建表的時候,直接指定某列或者某幾列為主鍵,這時就有主鍵索引, 2. 添加表后,再指定主鍵索引
l?直接創建主鍵索引
注意:如果是自增, 該主鍵不能夠刪除
?
l?先創建表,再指定主鍵
?
增加主鍵
ALTER TABLE 表名 ADD PRIMARY KEY (列1, 列名2..)
l?主鍵索引的特點
1.?一個表最多只能有一個主鍵
2.?一個主鍵可以指向多列(復合主鍵)
3.?主鍵索引的效率是最高,因此我們應該給id,一般id是自增.
4.?主鍵索引列是不能重復,也不能為null
5.1.2.?唯一索引的創建
l?直接在創建表的時候,指定某列或某幾列為唯一索引
?
l?把表創建好后,再指定某列或者某幾列為唯一索引
?
說明: 使用 create unique index 指令,必須指定索引名。
?
說明: 使用alter table 指令,可以指定索引名,也可以不指定。
l?唯一索引的特點
1)?一張表可以有多個唯一索引
2)?唯一索引不能重復,但是如果你沒有指定not null ,唯一索引列可以為null,而且可以有多個.
3)?什么時候使用唯一索引,當某列數據不會重復,才能使用
4)?唯一索引效率也很高,可以考慮優先使用
5.1.3.?普通索引的創建
l?在創建表時指定索引,通過key或者index
?
l?把表創建好后,再指定某列或者某幾列為索引
?
l?添加普通索引(2種方式)
?

?
l?特點
1)?一張表中可以有多個普通索引,一個普通索引頁可以指向多列
2)?普通索引列的數據可以重復
3)?效率相對而言低.
5.2.?索引的查詢
l?desc 表名
l?show keys from 表名\G
l?show index from 表名\G
l?show indexes from 表名\G
5.3.?索引的修改
先刪除,再添加。
5.4.?索引的刪除
DROP ?INDEX ?索引名??ON ?表;
ALTER ?TABLE 表名 DROP INDEX 索引名;
?
5.5.?索引的注意事項

索引的缺點:
增刪改速度慢..
優點:
查詢速度快…
?
建立索引一定要根據自己的需求來…
實例:
登錄用戶名是否適合建索引? 用戶名適合建立索引
?
操作日志:
用戶名 ???操作的哪個控制器的哪個方法 ???操作時間記錄
不合適建立索引..
6.?sql語句的優化和正確使用索引
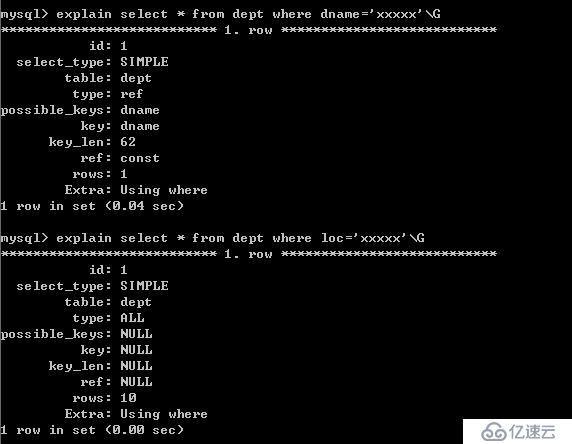
6.1.?對于創建的多列(復合)索引,只要查詢條件使用了最左邊的列,索引一般就會被使用
name ?email
?alter table xxx ?add index (name,email)
select from xx where name = ‘xxx’;
select from xx where email?= ‘xxx’;
?
?
?
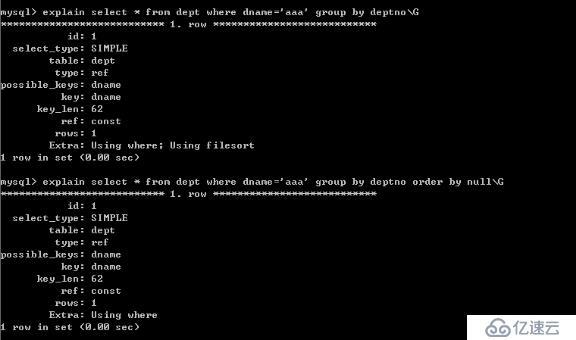
說明: dname是左邊的列,因此我們發現使用到dname,就使用到索引,而下面的sql語句,沒有使用到索引。
6.2.?對于使用like的查詢,查詢如果是‘%aaa’‘_aa' 不會使用到索引‘aaa%’會使用到索引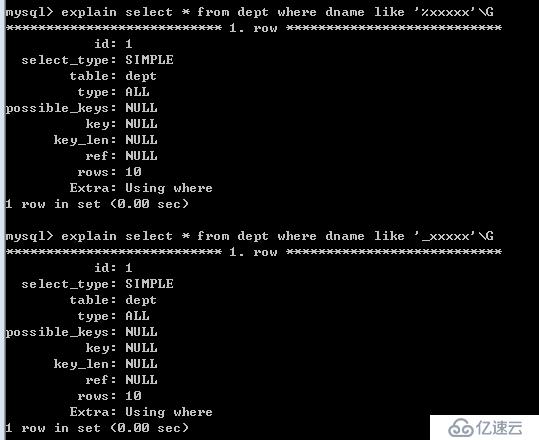
?
說明: 在like語句中,如果 '' 中最前有 或者 %就使用不到索引,如果在中間或者最后有 或者 %可以使用到索引。
6.3.?如果條件中有or,則要求or的所有字段都必須有索引,否則不會使用索引
?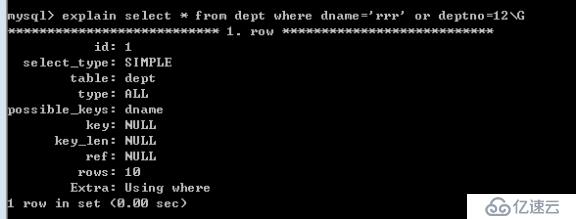
說明:因為 deptno 沒有索引,所以整個sql語句就沒有使用到索引。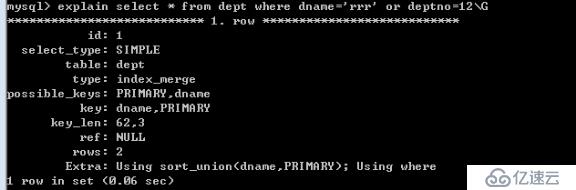
?
如果在 deptno上也創建索引,就可以使用到索引了.
如果mysql認為全表掃描效率更高,就不會使用索引,而會全表掃描
6.4.?如果列類型是字符串,那一定要在條件中將數據使用引號引用起來。否則不使用索引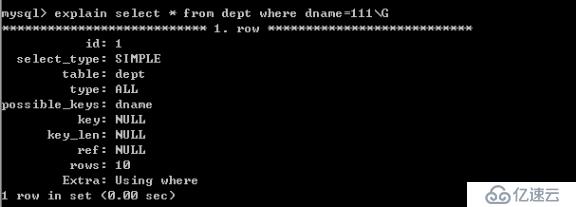
?
?
6.5.?有些情況下,可以使用連接來替代子查詢。因為使用join,MySQL不需要在內存中創建臨時表
子查詢:select? from emp where deptno in (select deptno?from dept)
連接:select from emp left join dept on emp.deptno=dept.deptno where emp.deptno=dept.deptno
6.6.?管理員在導入大量數據,可以這樣提高速度
大批量插入數據(MySql管理員) 了解
對于MyISAM:
?alter table table_name disable keys;
執行insert語句導入
alter table table_name enable keys;
對于Innodb:
1,?將要導入的數據按照主鍵排序
2,?set unique_checks=0,關閉唯一性校驗。
3,?set autocommit=0,關閉自動提交。
6.7.?如何選擇存儲引擎
?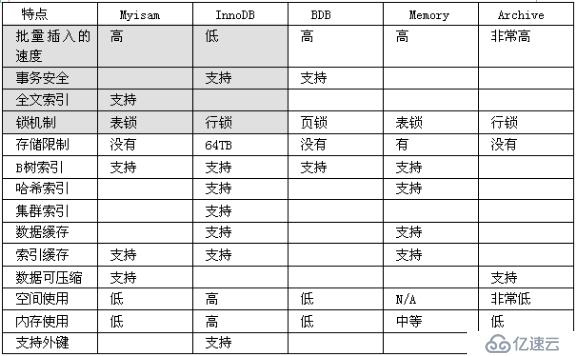
l?如何選擇的原則
(1)?MyISAM:默認的MySQL存儲引擎。如果應用是以讀操作和插入操作為主,只有很少的更新和刪除操作,并且對事務的完整性要求不是很高。其優勢是訪問的速度快。(尤其適合論壇的帖子/信息表/新聞/商品表表)
(2)?InnoDB:提供了具有提交、回滾和崩潰恢復能力的事務安全。但是對比MyISAM,寫的處理效率差一些并且會占用更多的磁盤空間(如果對安全要求高,則使用innodb)。[賬戶,積分,余額]
6.8.?如何選擇正確的數據類型
6.8.1.?在滿足需求的情況下盡量選擇小的類型.
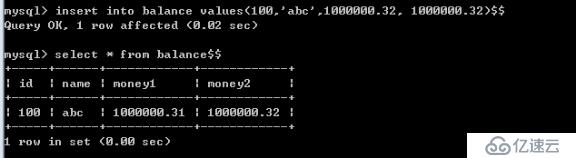
6.8.2.?在精度要求高的應用中,建議使用定點數來存儲數值,以保證結果的準確性。decimal 不要用float.
舉例:
?
?
說明: 這里我們看的?float(10,2) , 和?decimal(10,2) decimal 更精準。所以我們對精度高的列,要使用decimal 類型。
6.8.3.?對存儲引擎是MyISAM的表,要定時碎片整理
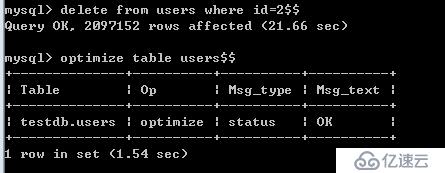
舉例說明:當我們在users表中有大量數據時,我們delete 數據后,我們發現磁盤空間沒有回收,因此我們需要定時的進行碎片整理.如下:
創建表:
?
復制大量數據到同一個表中: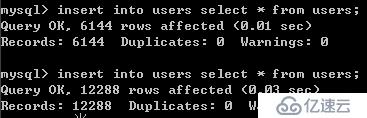
?
 ?
?
optimize: 該命令可以使表中的數據徹底從數據文件中刪除.
(本文由源碼時代技術老師原創發布,轉載請注明來源。)
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





