溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關怎么用Python分析44萬條數據,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
有個段子講“十年文案老司機,不如網易評論區,網易文豪遍地走,評論全部單身狗”,網易云音樂的評論區也一直都是各類文案大神的聚集地。
那么我們普通用戶到底如何成為網易云音樂評論里的熱評段子手?
讓我來分析一下。
獲取數據
其實邏輯并不復雜:
爬取歌單列表里的所有歌單url。
進入每篇歌單爬取所有歌曲url,去重。
進入每首歌曲首頁爬取熱評,匯總。
歌單列表是這樣的:
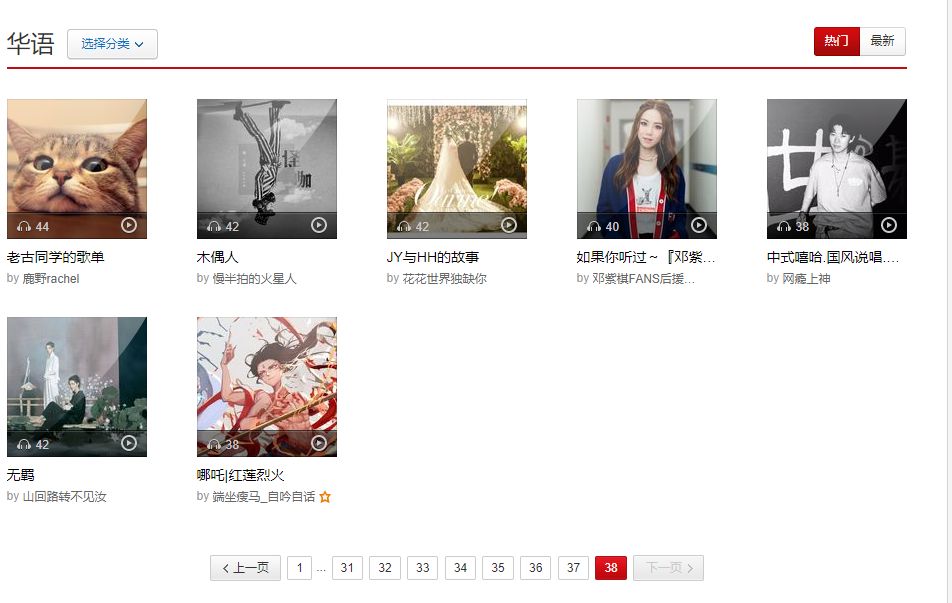
翻頁并觀察它的url變化,注意下方動圖,每次翻頁末尾變化35。

采用requests+pyquery來爬取。
在學習過程中有什么不懂得可以加我的
python學習交流扣扣qun,784758214
群里有不錯的學習視頻教程、開發工具與電子書籍。
與你分享python企業當下人才需求及怎么從零基礎學習好python,和學習什么內容
def get_list():
list1 = []
for i in range(0,1295,35):
url = 'https://music.163.com/discover/playlist/?order=hot&cat=%E5%8D%8E%E8%AF%AD&limit=35&offset='+str(i)
print('已成功采集%i頁歌單\n' %(i/35+1))
data = []
html = restaurant(url)
doc = pq(html)
for i in range(1,36): # 一頁35個歌單
a = doc('#m-pl-container > li:nth-child(' + str(i) +') > div > a').attr('href')
a1 = 'https://music.163.com/api' + a.replace('?','/detail?')
data.append(a1)
list1.extend(data)
time.sleep(5+random.random())
return list1這樣我們就可以獲得38頁每頁35篇歌單,共1300+篇歌單。
下面我們需要進入每篇歌單爬取所有歌曲url,并且要注意最后“去重”,不同歌單可能包含同一首歌曲。
點開一篇歌單,注意紅色圈出的id。
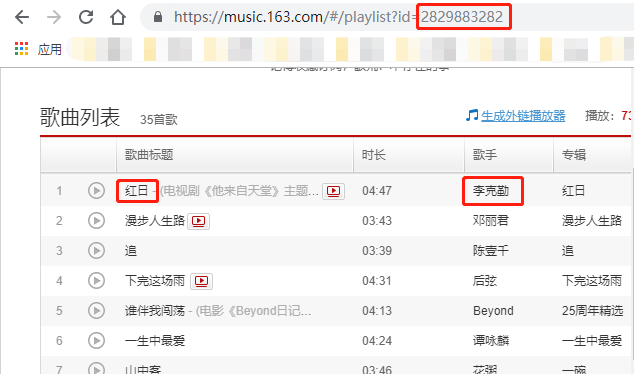
觀察一下,我們要在每篇歌單下方獲取的信息也就是紅框圈出的這些,利用剛剛爬取到的歌單id和網易云音樂的api(下一篇文章細講)可以構造出:
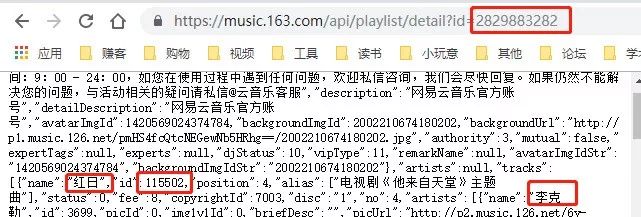
不方便看的話我們解析一下json。

def get_playlist(url):
data = []
doc = get_json(url)
obj=json.loads(doc)
jobs=obj['result']['tracks']
for job in jobs:
dic = {}
dic['name']=jsonpath.jsonpath(job,'$..name')[0] #歌曲名稱
dic['id']=jsonpath.jsonpath(job,'$..id')[0] #歌曲ID
data.append(dic)
return data這樣我們就獲取了所有歌單下的歌曲,記得去重。
#去重 data = data.drop_duplicates(subset=None, keep='first', inplace=True)
剩下就是獲取每首歌曲的熱評了,與前面獲取歌曲類似,也是根據api構造,很容易就找到了。
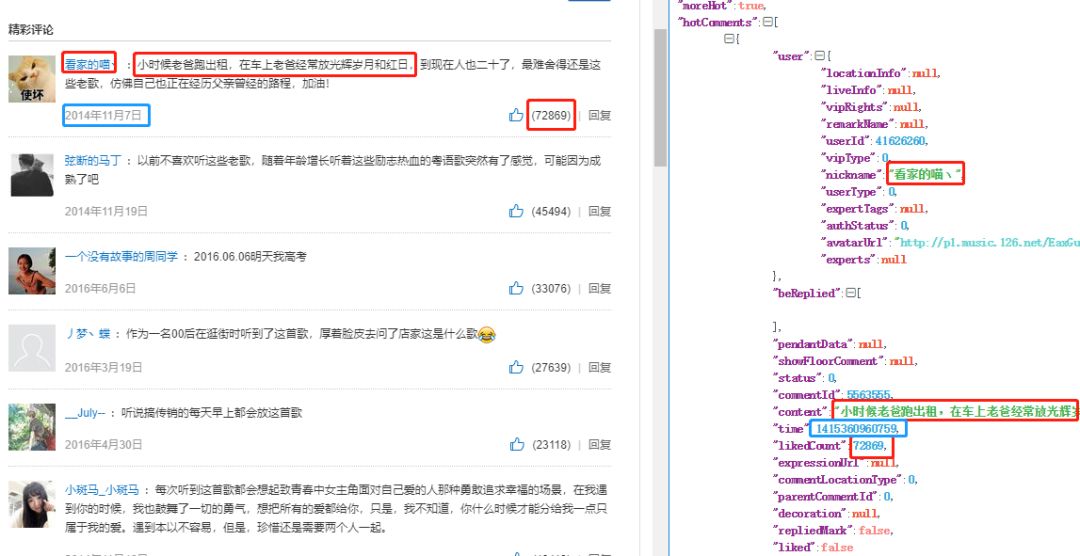
def get_comments(url,k):
data = []
doc = get_json(url)
obj=json.loads(doc)
jobs=obj['hotComments']
for job in jobs:
dic = {}
dic['content']=jsonpath.jsonpath(job,'$..content')[0]
dic['time']= stampToTime(jsonpath.jsonpath(job,'$..time')[0])
dic['userId']=jsonpath.jsonpath(job['user'],'$..userId')[0] #用戶ID
dic['nickname']=jsonpath.jsonpath(job['user'],'$..nickname')[0]#用戶名
dic['likedCount']=jsonpath.jsonpath(job,'$..likedCount')[0]
dic['name']= k
data.append(dic)
return data匯總后就獲得了44萬條音樂熱評數據。

數據分析
清洗填充一下。
def data_cleaning(data):
cols = data.columns
for col in cols:
if data[col].dtype == 'object':
data[col].fillna('缺失數據', inplace = True)
else:
data[col].fillna(0, inplace = True)
return(data)按照點贊數排個序。
#排序
df1['likedCount'] = df1['likedCount'].astype('int')
df_2 = df1.sort_values(by="likedCount",ascending=False)
df_2.head()
再看看哪些熱評是被復制粘貼搬來搬去的。
#排序 df_line = df.groupby(['content']).count().reset_index().sort_values(by="name",ascending=False) df_line.head()

第一個和第三個只是末尾有沒有句號的區別,可以歸為一類。這樣的話,重復次數最多個這句話竟然重復了412次,額~~
看看上熱評次數次數最多的是哪位大神?從他的身上我們能學到什么經驗?
df_user = df.groupby(['userId']).count().reset_index().sort_values(by="name",ascending=False) df_user.head()
按照 user_id 匯總一下,排序。
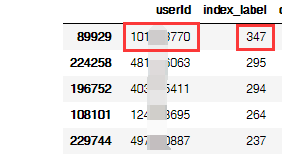
成功“捕獲”一枚“段子手”,上熱評次數高達347,我們再看看這位大神究竟都評論些什么?
df_user_max = df.loc[(df['userId'] == 101***770)] df_user_max.head()

這位“失眠的陳先生”看來各種情話嫻熟于手啊,下面就以他舉例來看看如何成為網易云音樂評論里的熱評段子手吧。
數據可視化
先看看這347條評論的贊數分布。
#贊數分布圖
import matplotlib.pyplot as plt
data = df_user_max['likedCount']
#data.to_csv("df_user_max.csv", index_label="index_label",encoding='utf-8-sig')
plt.hist(data,100,normed=True,facecolor='g',alpha=0.9)
plt.show()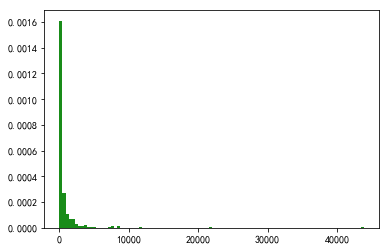
很明顯,贊數并不多,大部分都在500贊之內,幾百贊卻能躋身熱評,這也側面說明了這些歌曲是比較小眾的,看來是經常在新歌區廣撒網。
我們使用len() 求出每條評論的字符串長度,再畫個分布圖
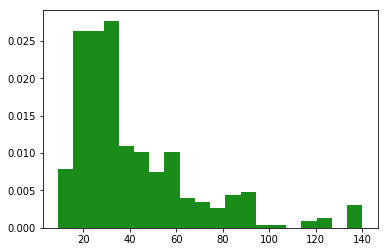
評論的字數集中在18—30字之間,這說明在留言時要注意字數,保險的做法是不要太長讓人讀不下去,也不要太短以免不夠經典。
做個詞云。

可以看出他的評論風格是以一首歌使他“想起”“感覺”為開頭,賓語通常是“喜歡的女孩子”,也經常用”她”來指代。寄托的情感是“后悔”“悲傷”,感慨的終點是“放下”。
以上就是怎么用Python分析44萬條數據,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





