溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“web算法中樸素貝葉斯如何實現文檔分類”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“web算法中樸素貝葉斯如何實現文檔分類”吧!
作業要求:
實驗數據在bayes_datasets文件夾中。其中,
? train為訓練數據集,包含hotel和travel兩個中文文本集,文本為txt格式。hotel文本集中全部都是介紹酒店信息的文檔,travel文本集中全部都是介紹景點信息的文檔;
? Bayes_datasets/test為測試數據集,包含若干hotel類文檔和travel類文檔。
用樸素貝葉斯算法對上述兩類文檔進行分類。要求輸出測試數據集的文檔分類結果,即每類文檔的數量。
(例:hotel:XX,travel:XX)
貝葉斯公式:
樸素貝葉斯算法的核心,貝葉斯公式如下:
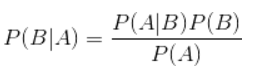
代碼實現:
第一部分:讀取數據
f_path = os.path.abspath('.')+'/bayes_datasets/train/hotel'
f1_path = os.path.abspath('.')+'/bayes_datasets/train/travel'
f2_path = os.path.abspath('.')+'/bayes_datasets/test'
ls = os.listdir(f_path)
ls1 = os.listdir(f1_path)
ls2 = os.listdir(f2_path)
#去掉網址的正則表達式
pattern = r"(http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*,]|(?:%[0-9a-fA-F][0-9a-fA-F]))+)|([a-zA-Z]+.\w+\.+[a-zA-Z0-9\/_]+)"
res = []
for i in ls:
with open(str(f_path+'\\'+i),encoding='UTF-8') as f:
lines = f.readlines()
tmp = ''.join(str(i.replace('\n','')) for i in lines)
tmp = re.sub(pattern,'',tmp)
remove_digits = str.maketrans('', '', digits)
tmp = tmp.translate(remove_digits)
# print(tmp)
res.append(tmp)
print("hotel總計:",len(res))
for i in ls1:
with open(str(f1_path + '\\' + i), encoding='UTF-8') as f:
lines = f.readlines()
tmp = ''.join(str(i.replace('\n', '')) for i in lines)
tmp = re.sub(pattern, '', tmp)
remove_digits = str.maketrans('', '', digits)
tmp = tmp.translate(remove_digits)
# print(tmp)
res.append(tmp)
print("travel總計:",len(res)-308)
#print(ls2)
for i in ls2:
with open(str(f2_path + '\\' + i), encoding='UTF-8') as f:
lines = f.readlines()
tmp = ''.join(str(i.replace('\n', '')) for i in lines)
tmp = re.sub(pattern, '', tmp)
remove_digits = str.maketrans('', '', digits)
tmp = tmp.translate(remove_digits)
# print(tmp)
res.append(tmp)
print("test總計:",len(res)-616)
print("數據總計:",len(res))
這一部分的任務是將放在各個文件夾下的txt文檔讀入程序,并將數據按照需要的形式存放。數據分為訓練集和測試集,而訓練集又包括景點和酒店兩類,故數據總共分為三類,分三次分別讀取。在訓練集的每一個txt文件中最前端都有一串網址信息,我用正則表達式將其過濾掉,后來發現此部分并不會影響最終的結果。之后將三類文檔依次讀取,將讀取的結果存放入一個結果list中。list的每一項為一個字符串,存放的是一個txt文件的去除掉要過濾的數據之后的全部信息。最終得到travel文件夾下共有308個文檔,hotel文件夾下也有308個文檔,測試集共有22個文檔。
第二部分:分詞,去除停用詞
stop_word = {}.fromkeys([',','。','!','這','我','非常','是','、',':',';'])
print("中文分詞后結果:")
corpus = []
for a in res:
seg_list = jieba.cut(a.strip(),cut_all=False)#精確模式
final = ''
for seg in seg_list:
if seg not in stop_word:#非停用詞,保留
final += seg
seg_list = jieba.cut(final,cut_all=False)
output = ' '.join(list(seg_list))
# print(output)
corpus.append(output)
# print('len:',len(corpus))
# print(corpus)#分詞結果
這一部分要做的是設置停用詞集,即分詞過程中過濾掉的無效詞匯,將每一個txt文件中的數據進行中文分詞。首先stop_word存放了停用詞集,使用第三方庫jieba進行中文分詞,將去除停用詞后的結果最后放入corpus中。
第三部分:計算詞頻
#將文本中的詞語轉換為詞頻矩陣
vectorizer = CountVectorizer()
#計算各詞語出現的次數
X = vectorizer.fit_transform(corpus)
#獲取詞袋中所有文本關鍵詞
word = vectorizer.get_feature_names()
#查看詞頻結果
#print(len(word))
for w in word:
print(w,end=" ")
print(" ")
#print("詞頻矩陣:")
X = X.toarray()
#print("矩陣len:",len(X))
#np.set_printoptions(threshold=np.inf)
#print(X)無錫人流多少錢 http://www.bhnnk120.com/
這一部分的任務是將文本中的詞語轉換為詞頻矩陣,并且計算各詞語出現的次數。詞頻矩陣是將文檔集合轉換為矩陣,每個文檔都是一行,每個單詞(標記)是列,相應的(行,列)值是該文檔中每個單詞或標記的出現頻率。
但我們需要注意的是,本次作業的詞頻矩陣的大小太大,我曾嘗試輸出整個詞頻矩陣,直接導致了程序卡頓,我也嘗試了輸出矩陣的第一項,也有近20000個元素,所以如果不是必需,可以不輸出詞頻矩陣。
第四部分:數據分析
# 使用616個txt文件夾內容進行預測
print ("數據分析:")
x_train = X[:616]
x_test = X[616:]
#print("x_train:",len(x_train))
#print("x_test:",len(x_test))
y_train = []
# 1表示好評0表示差評
for i in range(0,616):
if i < 308:
y_train.append(1)#1表示旅店
else:
y_train.append(0)#0表示景點
#print(y_train)
#print(len(y_train))
y_test= [0,0,0,1,1,1,0,0,1,0,1,0,0,1,0,0,1,1,1,0,1,1]
# 調用MultionmialNB分類器
clf = MultinomialNB().fit(x_train,y_train)
pre = clf.predict(x_test)
print("預測結果:",pre)
print("真實結果:",y_test)
print(classification_report(y_test,pre))
hotel = 0
travel = 0
for i in pre:
if i == 0:
travel += 1
else:
hotel += 1
print("Travel:",travel)
print("Hotel:",hotel)
這部分的任務是將所有的訓練數據根據其標簽內容進行訓練,然后根據訓練得到的結果對測試數據進行預測分類。x_train代表所有的訓練數據,共有616組;其對應的標簽為y_train,也有616組,值為1代表酒店,值為0代表景點。x_test代表所有的測試數據,共有22組;其對應標簽為y_test,亦22組,其值則由我自己事先根據其值手工寫在程序中。此時需要注意的是測試集文件在程序中的讀取順序可能與文件夾目錄中的順序不一致。最后將測試集數據使用訓練集數據調用MultionmialNB分類器得到的模型進行預測,并將預測結果與真實結果進行對比。
得出運行結果。
到此,相信大家對“web算法中樸素貝葉斯如何實現文檔分類”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





