溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
上個月某一天跟朋友聊天,聊到國慶電影,提到《攀登者》上映,預計票房會大好,因為吳京是這部片的主演。然后我就想,目前吳京在國內演員中位列幾何呢?正好之前爬了貓眼電影數據,基于python數據分析的方式,分析中國演員排名情況。
數據導入
導入之前爬取到的貓眼數據,由于爬取過程不是本文的主要內容,所以簡單描述下數據情況:20110101至20191019年在中國上映,并且有用戶評分和票房的影片,總共是2923部。
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
# 加載數據
def load_data():
# 加載電影票房
open_filepath = 'D:\pythondata\\3、貓眼電影\\box_result.csv'
movie_box = pd.read_csv(open_filepath)
movie_box = movie_box[['電影id', '電影名稱','首映日期','總票房']].drop_duplicates()
# 加載電影信息
open_filepath = 'D:\pythondata\\3、貓眼電影\\maoyan_movie.xlsx'
movie_message = pd.read_excel(open_filepath,sheet_name='maoyan_movie')
movie_message.columns = ['電影url','電影名稱','電影題材','國家','上映時間','用戶評分','電影簡介','導演/演員/編劇']
movie_message = movie_message[['電影url','電影題材','國家','用戶評分','導演/演員/編劇']].copy()
movie_message.drop_duplicates(inplace=True)
movie_message['電影id'] = movie_message.apply(lambda x:x['電影url'].replace('https://maoyan.com/films/',''),axis=1)
movie_message[['電影id']] = movie_message[['電影id']].apply(pd.to_numeric)
# 合并電影信息和票房
data = pd.merge(movie_box,movie_message,how='inner',on=['電影id'])
return data

數據處理
由于此次只分析中國演員,所以需要剔除國外影片,并將每部影片的演員列表從字段“導演/演員/編劇”中分割出來。
# 只篩選中國的電影
data = data[data['國家'].str.contains('中國')]
# 剔除空值
data = data.dropna(subset=["導演/演員/編劇"])
# 將演員列表從字段“導演/演員/編劇”中分割出來
data['演員'] = data.apply(lambda x:x['導演/演員/編劇'] if '演員' in x['導演/演員/編劇'] else None,axis=1)
data['演員list'] = data.apply(lambda x: ','.join(x['演員'].split('yyyyy')[1].split('xxxxx')[2:]) if pd.notnull(x['演員']) else None,axis=1)
# 剔除無演員列表的行
data = data.dropna(subset=["演員list"])
# 剔除無用字段
data.drop(['導演/演員/編劇'],axis=1,inplace=True)
data.drop(['演員'],axis=1,inplace=True)
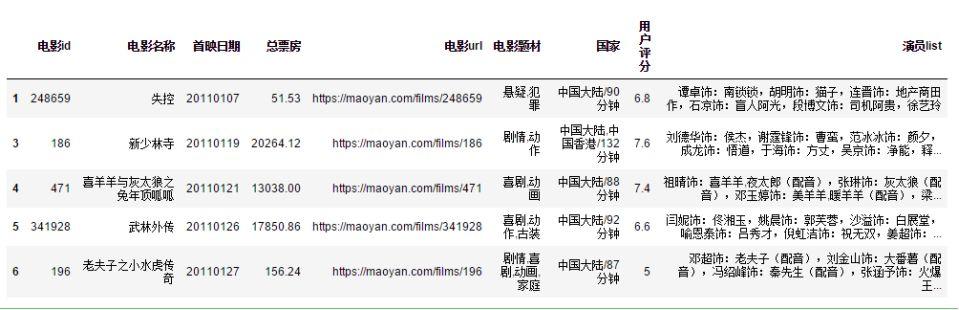
因為考慮到配音類型的影片是看不到演員本人的,所以需要剔除配音類型影片。再將演員列表從行轉置列,使得每行電影名稱和演員是一一對應的。由于貓眼電影已經按照演員的出場頻率進行排序,所以每部影片取前四名演員,作為影片主演,其中多明星合拍的影片,如《我和我的祖國》就改為取前十名。
# 拆分演員列表,并轉置成一列
data = data.drop("演員list", axis=1).join(data["演員list"].str.split(",", expand=True).stack().reset_index(level=1, drop=True).rename("演員"))
# 剔除配音演員
data = data[~data['演員'].str.contains('配音')]
data['演員'] = data.apply(lambda x: x['演員'].split('飾:')[0] if '飾:' in x['演員'] else x['演員'], axis=1)
# 剔除分割演員名稱錯誤的行
data = data[~data['演員'].str.contains('uncredited')]
data = data[~data['演員'].str.contains('voice')]
data = data[~data['演員'].str.contains('Protester')]
# 取每部電影的前四名演員,部分影片特殊
data_actor = data[['電影id','電影名稱','演員']].drop_duplicates()
data_actor_top4 = data_actor[data_actor['電影名稱']!='我和我的祖國'].groupby(['電影id','電影名稱']).head(4)
data_actor_top10 = data_actor[data_actor['電影名稱']=='我和我的祖國'].groupby(['電影id','電影名稱']).head(10)
data_actor_top4 = pd.concat([data_actor_top4,data_actor_top10])
# 剔除外國演員
data_actor_top4['演員名字長度'] = data_actor_top4.apply(lambda x: len(x['演員']),axis=1)
data_actor_top4 = data_actor_top4[(data_actor_top4['演員名字長度']<=3)].copy()
data_actor_top4.drop("演員名字長度",axis = 1,inplace=True)
# 匹配
data = pd.merge(data,data_actor_top4,how='inner',on=['電影id','電影名稱','演員'])
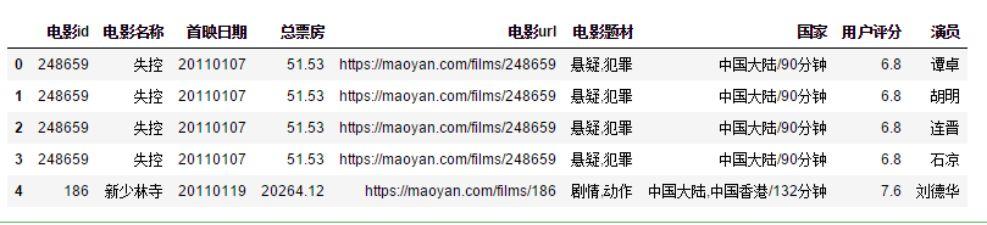
然后,拆分每部電影的電影題材類型并進行轉置,再匯總每個演員出演過的電影題材,排序后取前三個類型,作為演員的拿手題材。
# 拆分電影題材
data = data.join(data["電影題材"].str.split(",",expand = True).stack().reset_index(level = 1,drop = True).rename("題材"))
# 取每位演員最擅長的電影題材TOP3
data_type_actor = data[['電影id','電影名稱','演員','題材']].drop_duplicates().groupby(['演員', '題材']).agg({'電影id': 'count'}).reset_index().sort_values(['演員','電影id'],ascending=False)
data_type_actor = data_type_actor.groupby(['演員']).head(3)
data_type_actor = data_type_actor.groupby(['演員'])['題材'].apply(list).reset_index()
data_type_actor['題材'] = data_type_actor['題材'].apply(lambda x: ','.join(str(i) for i in list(set(x)) if str(i) != 'nan'))
data_type_actor.rename(columns={'題材': '演員_拿手題材'}, inplace=True)
data = pd.merge(data,data_type_actor,how='left',on=['演員'])
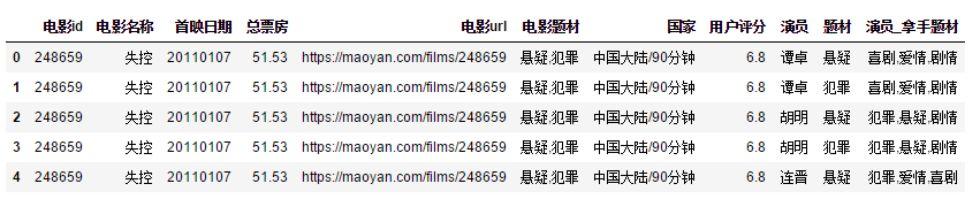
數據分析
目前只有“演員總票房”和“影片平均評分”兩個字段,可用作描述一個演員綜合能力,所以需要衍生一些字段:
電影數量:統計演員主演過的影片數量;
大于10億票房影片數量:匯總單部影片票房大于10億的數量;
大于10億票房影片計分:按照不同票房區間賦予分值,再匯總;
由于部分演員只出演過一部影片,屬于單樣本,若不剔除,會影響各項指標的數值分布。
actor = result[['演員','總票房','用戶評分']].drop_duplicates()
# 衍生字段:平均票房、大于10億票房影片、大于10億票房影片計分
actor['用戶評分'] = actor.apply(lambda x:0 if x['用戶評分']=='暫無評分' else x['用戶評分'],axis=1)
actor['大于10億票房影片數量'] = actor.apply(lambda x:1 if x['總票房']>100000 else 0,axis=1)
# 按照票房賦予分值
def goal(x):
if x['總票房']<=100000:
division_goal = 0
elif x['總票房']<=200000:
division_goal = 1
elif x['總票房'] <= 300000:
division_goal = 2
elif x['總票房'] <= 400000:
division_goal = 3
elif x['總票房'] <= 500000:
division_goal = 4
else:
division_goal = 5
return division_goal
actor['大于10億票房影片計分'] = actor.apply(goal,axis=1)
actor['電影數量'] = 1
actor['用戶評分'] = pd.to_numeric(actor['用戶評分'])
actor['大于10億票房影片數量'] = pd.to_numeric(actor['大于10億票房影片數量'])
actor['大于10億票房影片計分'] = pd.to_numeric(actor['大于10億票房影片計分'])
# 匯總
actor2 = actor.groupby(['演員']).agg({'總票房': 'sum',
'大于10億票房影片數量': 'sum',
'大于10億票房影片計分': 'sum',
'電影數量': 'count',
'用戶評分':'mean',}).reset_index()
# 篩選影片數量大于1的行——只有一部影片的演員設為單樣本,會影響標準化的結果
actor2 = actor2[actor2['電影數量']>1].reset_index(drop=True)
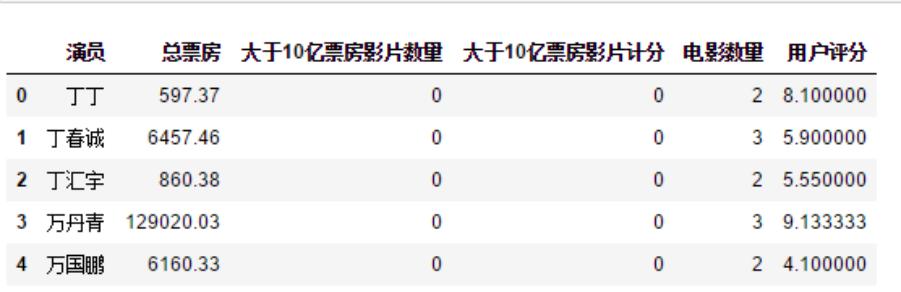
最后,由于數值字段之間的量綱不同,需要進行標準化處理后才可以進行比較。“演員總票房”的高低是衡量一個演員能力的重要因素,這里筆者將“大于10億票房影片數量”和“大于10億票房影片計分”也作為兩點重要因素,而“影片平均評分”和“電影數量”作為次要因素,最終標準化處理后的計算公式:
總分=演員總票房+大于10億票房影片數量+大于10億票房影片計分+0.5*影片平均評分+0.5*電影數量
這里筆者曾用K-means聚類算法將演員劃分為四個集群,通過查看集群的分布情況后發現,劃分結果與上述公式計算后的總分排名情況十分相似(比如,總分1-20名劃分成集群1,21-50名劃分成集群2),所以取消了用聚類算法的方式劃分演員檔次。
# 復制一份副本
actor_copy = actor2.copy()
# 標準化處理
scaler = StandardScaler()
numeric_features = actor2.dtypes[actor2.dtypes != 'object'].index
scaler.fit(actor2[numeric_features])
scaled = scaler.transform(actor2[numeric_features])
for i, col in enumerate(numeric_features):
actor2[col] = scaled[:, i]
# 劃分演員檔次:權重求和,根據分值排序
result = actor2.apply(lambda x: x['總票房']+x['大于10億票房影片數量']+x['大于10億票房影片計分']+0.5*x['電影數量']+0.5*x['用戶評分'],axis=1)
# # 劃分演員檔次——方法2:采用聚類算法,自動分成4個組
# actor_model = actor2[['總票房', '大于10億票房影片數量', '大于10億票房影片計分','電影數量','用戶評分']].values
# y_pred = KMeans(n_clusters=4, random_state=9).fit_predict(actor_model)
# result2 = pd.Series(y_pred)
# 合并兩種結果
model_actor_reuslt = pd.concat([actor_copy, result], axis=1)
model_actor_reuslt.rename(columns={0: '總分'},inplace=True)
model_actor_reuslt = model_actor_reuslt.sort_values('總分',ascending=False).reset_index(drop=True)
數據描述
由于工作上經常使用BI工具tableau進行圖表制作,因此下列的圖表均用tableau繪制。其實pyecharts生成的圖表也十分美觀,為了方便這里就不用這個庫畫圖了,有興趣的小伙伴也可以了解下這個庫。
先從整體上對電影的概況進行描述分析,才能更好地理解演員各項指標高低的優劣程度。首先,2011年至今,國內上映的影片總共是2129部,其中10億票房以上的影片只有39部,占了總體的0.02%。
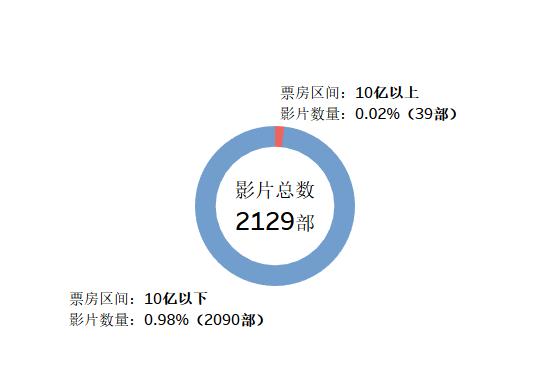
圖電影總數
目前國內影片最高票房已經到50-60億之間,只有一部。40-50億只有兩部,大部分10億以上的票房都集中在10-20億之間。
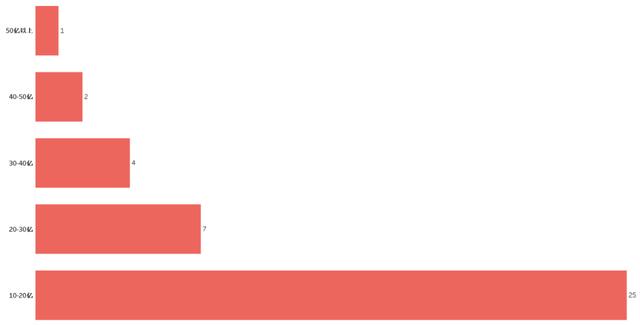
圖電影票房區間
整體上,劇情、喜劇和愛情類型的電影題材拍得最多,而災難類型的電影最少。從熱門和冷門的電影題材中,很好地詮釋了“報喜不報憂”這句成語,畢竟每個走進電影院的人都希望能輕松愉快地度過這兩個小時。所以10億以上票房的影片中,喜劇類型的電影題材反而排在了第一位。
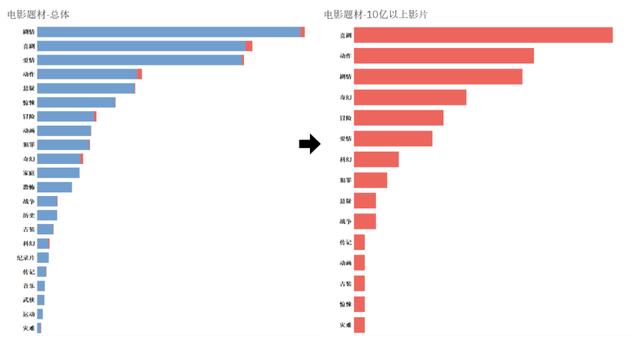
圖電影題材
從電影上映時間軸中可以看出,整體上,17年之前上映的影片逐年增加,但在17年之后有所下降。而10億以上票房的影片每年都在增加,側面說明近幾年國內電影影片質量有所上升。
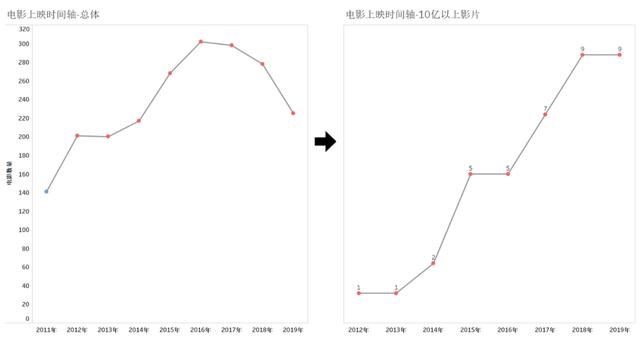
圖電影上映時間軸
最后,將全部圖表放到同一個儀表板中,可以很方便地看到10億以上票房的影片分布情況,以及具體的影片名稱。其中,2012年的《人在囧途之泰囧》是國內第一部10億+票房影片,2015年的《捉妖記》是首部20億+票房影片,2016年的《美人魚》是首部30億+票影片,2017年的《戰狼2》是首部50億+票房影片,而2019年的《流浪地球》和《哪吒之魔童降世》是唯一兩部40億+票房影片。從這個時間軸可以看出,自2015年起,每年最高票房都比前年多出10億以上。
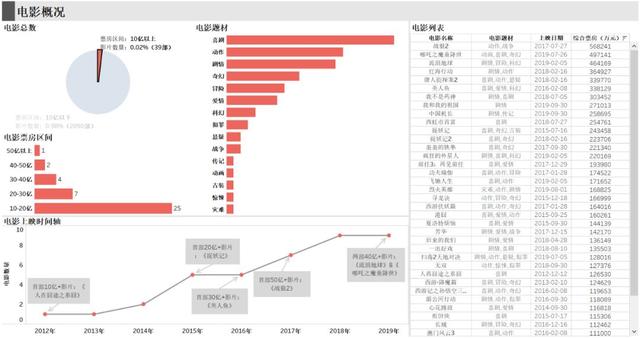
圖電影概況
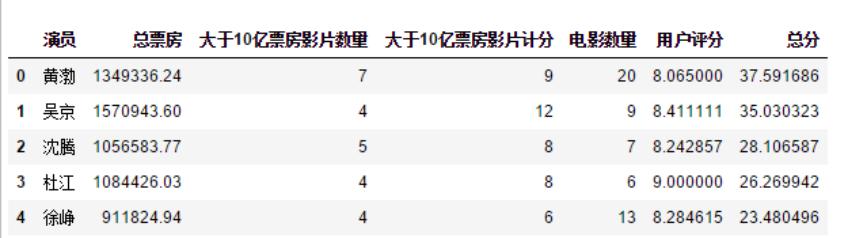
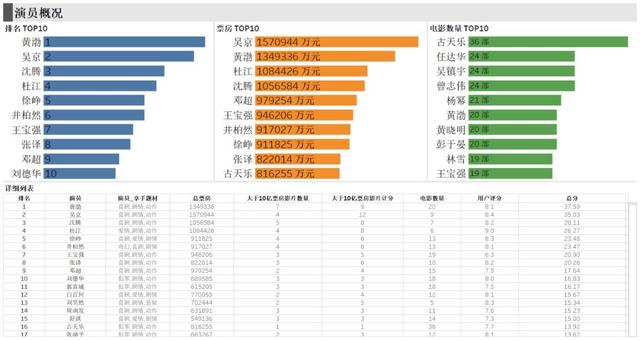
根據上述的計算公式得到總分TOP10的名單,前三名分別是黃渤、吳京和沈騰。這也難怪筆者的同學會對吳京出演的影片信心那么高。
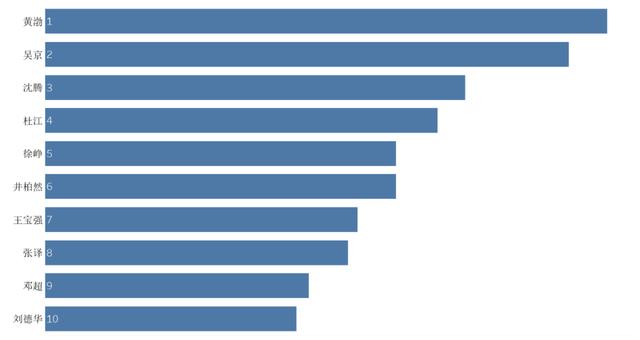
圖演員總分排名
匯總每個演員主演的電影票房后,得到總票房TOP10的名單,目前國內百億票房均是男演員,分別是吳京、黃渤、杜江和沈騰。其中吳京已經是150億票房冠軍,而讓筆者比較意想不到的是杜江也上了百億榜,雖然他參演的幾部熱門影片,如《紅海行動》、《我和我的祖國》和《中國機長》都不是第一主演,但這幾部都是10億+票房影片,是不是能說明他存在某些旺票房特質呢?
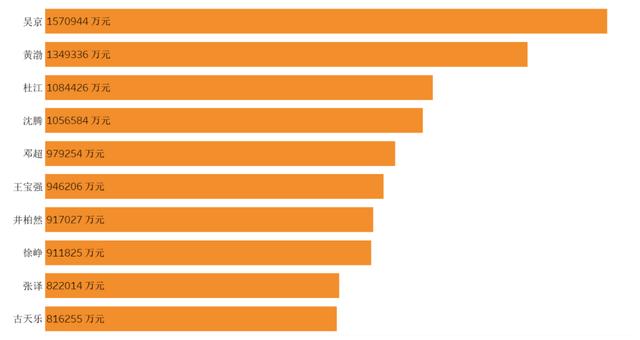
圖演員總票房
再來看看演員電影數量TOP10的分布情況,可以看到前幾名都是香港演員,其中古天樂在7年內主演了36部影片,位列榜首。除了影片數量位列榜首外,其實平平無奇的古仔已經默默地捐贈了100多所學校,這也許就是他當上電影“勞模”的原因吧。
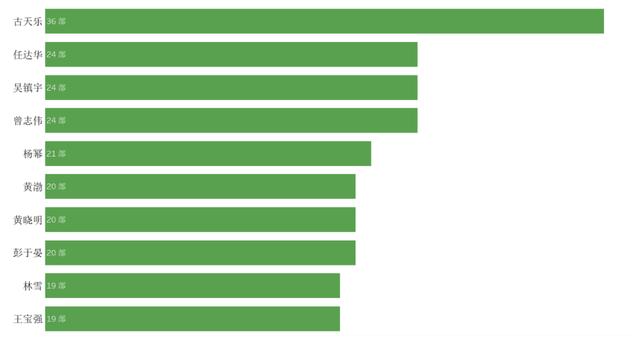
圖演員電影數量
最后,將上述三張圖表和詳細列表放到同個儀表板中,就可以清楚地知道,能夠位列前茅的演員都是主演過多部影片,并且擁有多部10億+票房影片。其中有一個比較有趣的地方是王寶強的影片平均評分是6.3,但他仍然能夠排到第七名,原因是他主演過幾部評分在5分以下的影片,才導致他平均評分會這么低。
結語
本文旨在讓大家了解一下國內電影的整體概況和演員概況,所以只是簡單地對數據進行描述性分析,并沒有運用到機器學習這方面的知識。一般地,描述性分析是做數據分析必不可少的一步,通過簡單的幾個圖表就能直觀地對數據有整體上的認知。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





