溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
編輯手記
:祝賀羅海雄老師加入Oracle ACE社區,他是數據庫SQL開發和性能優化專家,也是ITPUB論壇的資深版主,我們整理了羅老師一篇AWR裸數據分析的文檔,供大家學習參考(同款PPT和相關源碼下載請關注公眾號回復:
RollingPig
@?/rdbms/admin/awrrpt.sql -- 標準報告,特定時間段內總體性能報告
@?/rdbms/admin/awrddrpt.sql -- 對比報告,兩個時間段內性能對比
@?/rdbms/admin/ashrpt.sql -- ASH報告,特定時間段內歷史會話性能報告
@?/rdbms/admin/awrsqrpt.sql -- SQL報告,特定時間段內SQL性能報告
AWR/ASH報告很不錯,但也有一些缺陷。
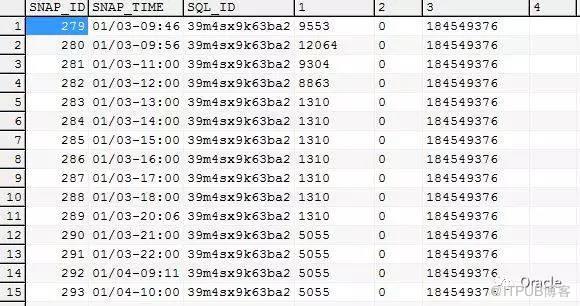
首先,AWR反應的是點對點的數據。
比如說,我生成一個今天9:00到12:00的AWR報告,那么,我看到的,就是12:00和9:00兩個時間點的變化。但是,9:00-10:00, 10:00-11:00,11:-12:00 分別是什么樣的,我們看不到。
另外一個問題,AWR把數據都羅列出來,但卻缺乏數據間的聯系.
AWR混入大量無用數據
, 導致生成AWR報告需要30秒到幾分鐘的時間,所以,如果我們有裸數據,其實可以更高效,更深入的挖掘Oracle數據庫的性能信息。
在裸數據里面,記錄的各種指標主要有4類
舉個例子 dba_hist_sysstat 里會記錄數據庫的邏輯讀。記錄的不是這一個小時產生的邏輯讀,而是從數據庫啟動到產生快照的時候的總的邏輯讀。這就叫累計值,大多數的指標的是累計值。
比如說,數據庫當前的PGA使用量,數據庫的會話數等,還有比較特殊的,會記錄兩次快照之間的變化值。我們可以認為,這是一種預計算,最常見的記錄變化值的兩類數據,分別是SQL相關統計信息,以及段(segment)相關統計信息,當然,SQL/Segment記錄變化值的同時,也記錄了累計值。
就是把一段時間內的數據,做了統計之后保存了起來,這些主要是METRIC類的數據。比如說,每秒CPU, 每秒最大等待時間等。
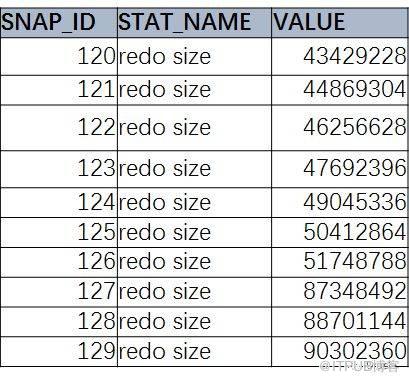
兩次快照之間的變化量。這是一個簡單的SQL, 獲取數據庫的歷史性能信息里的redo size 信息
select SNAP_ID,STAT_NAME,VALUE from DBA_HIST_SYSSTAT
where STAT_NAME=‘redo size’ order by snap_id;
我們現在看到的,就是累計值。那么,怎么方便的獲取變化值呢?
1、
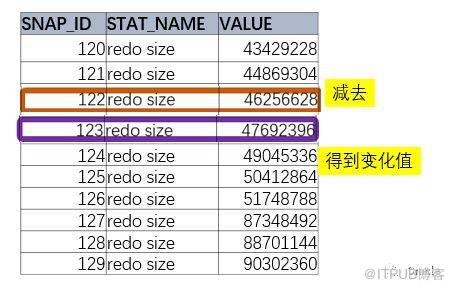
要取得變化值
,需要取出后面的記錄,減去前面的記錄。
如果僅僅是兩個時間點,最簡單的方法就是訪問這個表兩次,然后相減。
select a.value - b.value
from DBA_HIST_SYSSTAT A,DBA_HIST_SYSSTAT B
where A.STAT_NAME=‘redo size’ and
A.STAT_NAME = B.STAT_NAME and a.snap_id = 123 and b.snap_id = 122
這樣得到是兩個點之間的差值,但是對我們來說,玩玩是不夠的。
2、有時候,我們希望得到一個時間段內,每兩個連續快照之間的
變化值
。比如說,9:00-21:00, 我們希望獲得 9:00-10:00, 10:-11:00... 20:00-21:00, 每個時間段分別的變化值。
這里就涉及到Oracle的分析函數了
分析函數
Oracle的分析函數提供了在一個結果集內,跨行訪問數據的能力。
分析函數里面的LEAD/LAG正是跨行獲取數據的利器
LAG : 同一組內,排在當前行之前的數據
LEAD : 同一組內,排在當前行之后的數據
如圖所示,可以看到,我們要的是拿當前value 減去 lag value。
select snap_id,stat_name,
value-lag(value) over
(partition by stat_name order by snap_id)
from dba_hist_sysstat
where stat_name = 'redo size'
order by snap_id;
這就是分析函數LAG的完整語法。
3、
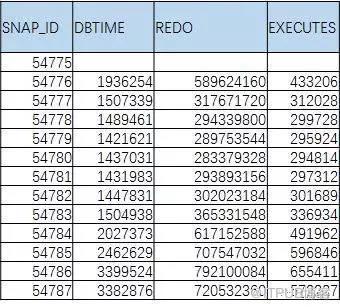
我們一般不會滿足獲取一個指標的變化值的,下面的表,才是我們希望獲得的。
這里又引入了進階SQL的另一個寫法
:行列轉換。
大家可以體會一下,如何使用sum(case when .. then .. end )或者max(case when .. then .. end )的形式的形式來進行行列轉換
,但用Case when來寫行列轉換,很容易使SQL冗長,而且容易出錯。
Oracle 11g中,提供了更方便的方式進行行列轉換
大家可以看到,標黃大寫的PIVOT, 正是Oracle 11g中引入的行列轉換利器。
使用PIVOT, 增減指標極其簡單:
很輕松就加了兩個指標,如果覺得列名不好看,也可以自己指定。
其實,我們可以很輕松的就把AWR報告中的"Load Profile"部分通過行列轉換給取出來,而且,是多個連續變化的值。
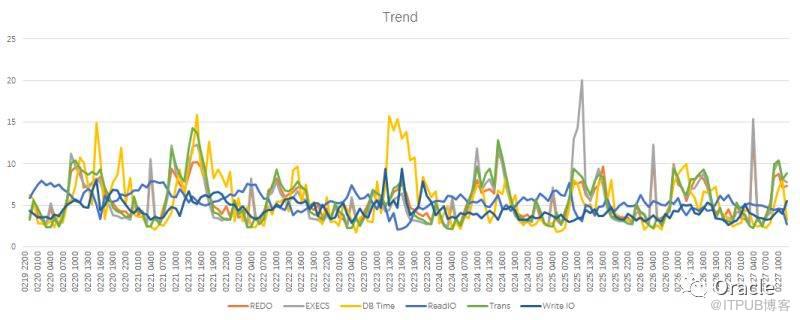
把跑的結果拷到Excel, 很容易就出來一個漂亮的趨勢圖。
但是,這個圖是有問題的:
圖里的REDO Size是以byte為單位的,值太大,把別的指標統統壓到和0差不多,多個指標要到同一個圖,還能看出各自的趨勢,對于多指標關聯的分析很有作用。
這時候,又有一個分析函數出來了。沒錯,因為我們是在對Oracle的性能數據進行分析,所以,需要大量的使用”分析函數“
分析函數: Ratio_To_Report 求當前行數據在所有同組數據內占的比例。
比如說,我的結果集里有3行,分別是1,3,6. 那么1對應的那一行,占總數據(1+3+6)的10%, 出來的結果就是0.1(10%).
select * from (
select snaptime,RATIO_TO_REPORT(value) over(partition by stat_name) value,stat_name,snap_id
from (… )) PIVOT (sum(value) for stat_name in (
…))order by snap_id;
在這個圖里面,大家就都平等了,也更方便的去看各個指標之間是否存在關聯
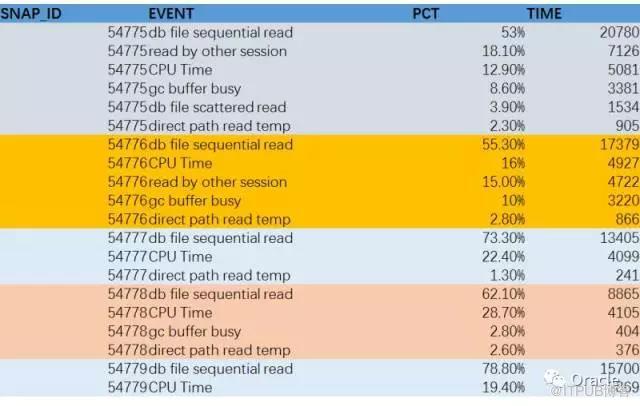
再給大家看另一個SQL, 還是ratio_to_report, 這次,我們拿到的結果,其實是AWR報告里另一個非常重要的數據:
Top Timed Events
我把每個時間段的CPU時間和非空閑事件給放在一起,然后計算每個事件(含CPU)在每個時間段占的百分比,就得到 Top Timed Events,而且是連續的多個時間的數據。
在看AWR時,有幾個區域是必看的。
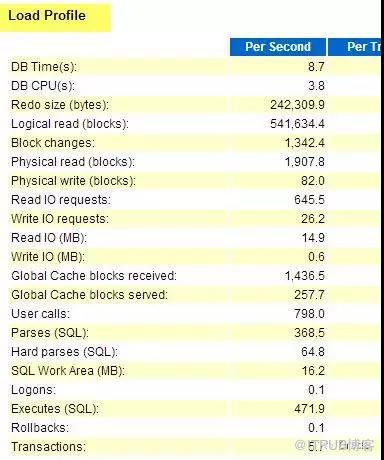
第一個是LOAD PROFILE.
參考前面用來演示lag() 函數的部分:
select * from (select snap_id,STAT_NAME,
value-lag(value) over(partition by STAT_NAME
order by snap_id) value
from dba_hist_sysstat where stat_name in (
‘redo size’,‘execute count’,‘DB time’,‘physical reads‘
) ) PIVOT (sum(value) for stat_name in (
'redo size','execute count','DB time','physical reads‘
))order by snap_id;
把stat_name里面的部分,加上LOAD PROFILE的其他指標,就是個完整的load profile了。
通過load profile, 大家可以對系統的總體負載有個準確的認識。
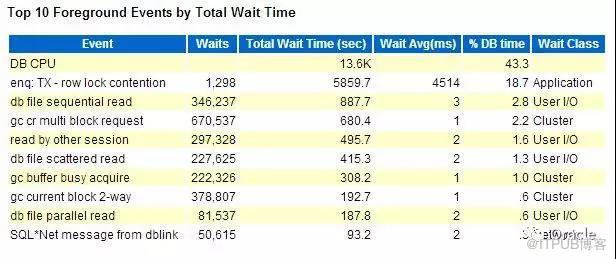
第二個部分,是Top timed events, 最耗時間的等待事件(包括CPU)的部分。
通過這個部分,大家可以了解整個系統的性能瓶頸:
select snap_id,event,pct||'%' PCT,time from (
select snap_id,event,round(time)time,
round(RATIO_TO_REPORT(TIME) over(partition by snap_id)*100,1) pct
from( select 'CPU Time' EVENT,snap_id,value/100 - LAG(value)over(partition by stat_name order by snap_id)/100 TIME
from DBA_HIST_SYSSTAT where stat_name = 'CPU used by this session'
union all select event_name,snap_id, time_waited_micro/1e6 -
LAG(time_waited_micro) over(partition by event_name order by snap_id)/1e6
from DBA_HIST_SYSTEM_EVENT where wait_class!='Idle'
)where time>0) where pct>1 order by snap_id,time desc
通常來說,知道了系統負載,系統瓶頸,我們還需要了解的是第三個部分: Top SQL
通過Top SQL, 我們可以了解系統運行過哪些主要的語句。
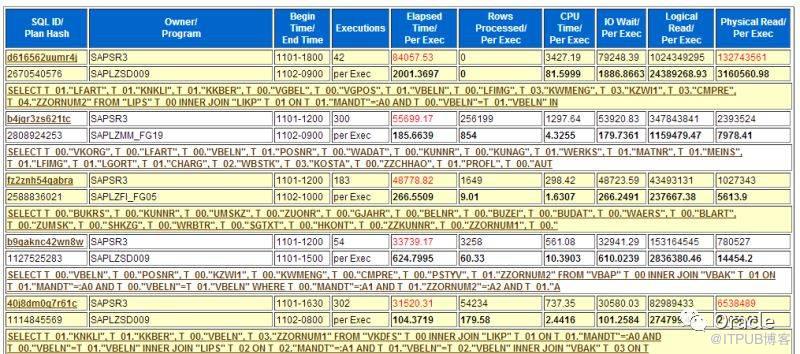
但是,傳統的AWR報告中的Top SQL是有缺陷的。最主要的問題,它的信息是分散的。
在對SQL進行判斷時,我會結合多個指標。執行時間(elapsed Time)、CPU時間(CPU Time)、邏輯讀(Buffer gets)、物理讀(disk reads)、執行次數(executions)、返回行數(rows_processed),但是,傳統的awr報告,這些指標分布在不同位置。看起來很不方便。
比如說這個,有執行時間,執行次數,CPU時間。但缺乏邏輯讀,物理讀,返回行數等,有時候,還得專門去找。
所以呢,我經常訪問裸數據,使用SQL, 直接從數據庫里取出包含完整信息的Top SQL.
另外,根據不同的情況,我們可能關心的點也不一樣。
比如說,系統CPU消耗嚴重,我們更關心SQL order by CPU, I/O嚴重時,關心的則是物理讀。所以我用的SQL, 可以支持同時取出按不同指標的排序的Top N SQL.
比如說, Top 10 by elapsed time, Top 10 by CPU, Top 10 by disk reads.
大家都知道,傳統的order by + rownum < N 的方式只支持對其中一個指標進行排名,顯然是不夠的。而分析函數,又再次發揮了作用。
select sql.*, (select SQL_TEXT from dba_hist_sqltext t
where t.sql_id = sql.sql_id and rownum=1 ) SQLTEXT
from (select a.* ,
RANK() over( order by els desc) as r_els,
RANK() over( order by phy desc) as r_phy,
RANK() over( order by get desc) as r_get,
RANK() over( order by exe desc) as r_exe,
RANK() over( order by CPU desc) as r_cpu
from (
select sql_id,sum(executions_delta) exe,round(sum(elapsed_time_delta
) / 1e6, 2) els
,round(sum(cpu_time_delta) / 1e6, 2) cpu,
round(sum(iowait_delta) / 1e6, 2) iow,sum(buffer_gets_delta) get,
sum(disk_reads_delta) phy,sum(rows_processed_delta) RWO,
round(sum(elapsed_time_delta) / greatest(sum(executions_delta), 1) / 1e6,4) elsp,
round(sum(cpu_time_delta) / greatest(sum(executions_delta), 1) / 1e6, 4) cpup,
round(sum(iowait_delta) / greatest(sum(executions_delta), 1) / 1e6, 4) iowp,
round(sum(buffer_gets_delta) / greatest(sum(executions_delta), 1), 2) getp,
round(sum(disk_reads_delta) / greatest(sum(executions_delta), 1), 2) phyp,
round(sum(rows_processed_delta) / greatest(sum(executions_delta), 1), 2) ROWP
from dba_hist_sqlstat s
--where snap_id between ... and ...
group by sql_id
) a
)SQL where r_els <= 10 or r_phy <=10 or r_cpu<=10 order by els desc
大家可以看到,這里面用到了 RANK() 函數。這個函數可以得出根據某個指標排序的排名。然后再通過最后的 r_els <= 10 or r_phy <=10 or r_cpu<=10 的過濾條件,就可以獲取按照多個指標排序的Top N了。
有時候,我會把這個結果想辦法做成HTML, 就變成這個效果了。
在分析SQL中,還有很重要的信息。
第一個是執行計劃。
select * from table(dbms_xplan.display_awr('&SQLID'))
除了執行計劃,還有一個信息不可或缺,就是綁定變量。
我碰到的SQL問題里面,有一個典型分類,就是SQL本來執行好好的,突然變差。這時候,在分析時,需要很關注的,就是歷史綁定變量。Oracle在AWR裸數據中也保留了綁定變量:
DBA_HIST_SQLSTAT.BIND_DATA 這個欄位里面,保存了綁定變量
通過以下SQL, 可以獲取歷史綁定變量:
select snap_id,sq.sql_id,bm.position, dbms_sqltune.extract_bind(sq.bind_data,bm.position).value_string value_string
from dba_hist_sqlstat sq ,dba_hist_sql_bind_metadata bm
where sq.sql_id = bm.sql_id --and sq.sql_id = '&sql'
出來的是行格式的,讀起來不方便。用PIVOT 做一個行列轉換就漂亮了。
select * from ( select snap_id, to_char(sn.begin_interval_time,'MM/DD-HH24:MI') snap_time, sq.sql_id,bm.position, dbms_sqltune.extract_bind(bind_data,bm.position).value_string value_string from dba_hist_snapshot sn natural join dba_hist_sqlstat sq ,dba_hist_sql_bind_metadata bm
where sq.sql_id = bm.sql_id and sq.sql_id = '&sql'
) PIVOT (max(value_string) for position in (1,2,3,4,5,6,7,8,9,10))
order by snap_id
完美的取出不同時間段的歷史綁定變量值.
對于“SQL本來執行好好的,突然變差”的問題,有一個比較簡潔的解決方式,就是嘗試讓SQL走回以前的執行計劃。
Select plan_hash_value ,Sum(Elapsed_time_Delta) /greatest(Sum(Executions_Delta),1),sum(Executions_Delta) From dba_hist_sqlstat where sql_id = '&SQLID' group by plan_hash_value ;
通過以上SQL, 可以快速獲取某個SQL多個執行計劃的執行效果。然后再想辦法應用其執行計劃,往往可以收到奇效。綁定執行計劃的方法有多種,SPM/SQL Profile/SQL Patch等,具體我就不展開了。
不知道大家有沒有碰到過這樣的情況, 有時候,明明性能瓶頸在SQL,但Top SQL中DB Time(%)指標卻很低,前10個加起來也不足20%.
像這個AWR, Top SQL by elapsed Time才記錄了2%. 也就是說,你只能看到2%的性能相關的SQL.
其中一個主要原因是由于Shared Pool大小限制以及非綁定變量問題,導致SQL可能會被漏記,
這種情況下,怎么辦呢?
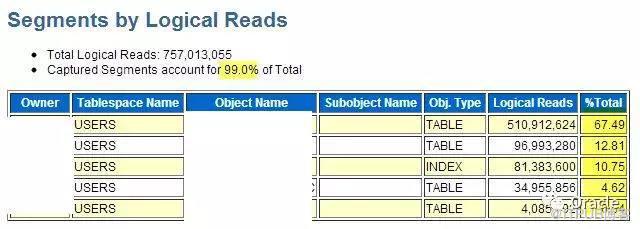
其實,有個地方不會被漏記。就是Top Segments.
通常,如果Top SQL中找不到太多信息,我們可以去看看Top Segments:
這是摘自同一個AWR的信息。 Top segments 告訴我們,對表的訪問集中在前面3個,我們可以專注于這幾個表的問題。
當然, 同樣可以通過SQL直接訪問裸數據獲取相關信息:
Select begin_interval_time,seg.snap_id,PHYSICAL_READS_DELTA, object_name,subobject_name
from DBA_HIST_SEG_STAT SEG ,DBA_HIST_SEG_STAT_OBJ O , dba_hist_snapshot snap
where o.obj# = seg.obj# and o.dataobj# = seg.dataobj# and PHYSICAL_READS_DELTA > 1e5 and seg.snap_id = snap.snap_id
and begin_interval_time > sysdate - 4/24
order by PHYSICAL_READS_DELTA desc
這是一個常用的AWR裸數據的列表:
AWR裸數據如此的重要,對于關心數據庫性能的DBA們,我們需要好好的保護好它們~
1. 系統保存時間,默認7天遠遠不足,建議改到30天以上,跨過一個月結周期
2. 需要的時候,我們可以對裸數據進行離線備份
@?/rdbms/admin/awrextr
3. 甚至,我們可以把裸數據專門找個數據庫存起來,作為一個資料庫使用。
@?/rdbms/admin/awrload
4. 有時候,也可以針對特定的表進行備份。比如說,我剛剛貼的這個列表
總結
以上分享主要內容是:
1.
AWR的分析辦法:
Load Profile, Top Timed Event, Top SQL, SQL Plan, SQL 綁定變量,Top Segments
2.
一些高級SQL用法:
分析函數 Lag/Rank/Ratio_to_report, 行列轉換 PIVOT




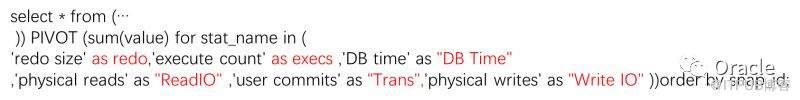




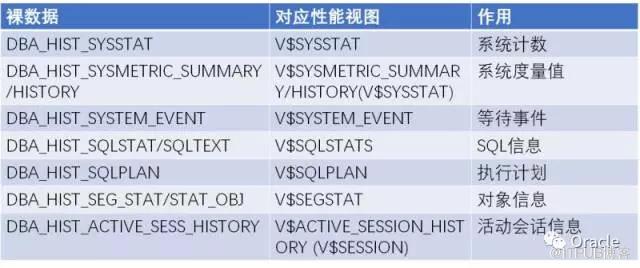 多數的AWR分析可以從這些裸數據開始。Load Profile, Top Timed Event, Top SQL, SQL Plan, SQL 綁定變量, Top Segments,相關的SQL 陸陸續續都貼出來了.
多數的AWR分析可以從這些裸數據開始。Load Profile, Top Timed Event, Top SQL, SQL Plan, SQL 綁定變量, Top Segments,相關的SQL 陸陸續續都貼出來了.
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





