溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文摘錄于 https://tech.meituan.com/2017/04/21/mt-leaf.html
2017年04月21日 作者: 照東 文章鏈接
業務系統對生成全局唯一ID的要求有哪些呢?
全局唯一性:不能出現重復的ID號,這是最基本的要求。
趨勢遞增:主鍵的選擇應該盡量使用有序的主鍵保證寫入性能。
單調遞增:保證下一個ID一定大于上一個ID,例如事務版本號、IM增量消息、排序等特殊需求。
信息安全:如果ID是連續的,容易被惡意用戶扒取,所以在一些應用場景下,會需要ID無規則、不規則。
ID生成系統應該做到如下幾點:
平均延遲和TP999延遲都要盡可能低;
可用性5個9;
高QPS。
幾種ID總結:
一.UUID
UUID(Universally Unique Identifier)的標準型式包含32個16進制數字,以連字號分為五段,形式為8-4-4-4-12的36個字符。
優點:
性能非常高:本地生成,沒有網絡消耗。
缺點:
不易于存儲:UUID太長,16字節128位,通常以36長度的字符串表示,很多場景不適用。
信息不安全:基于MAC地址生成UUID的算法可能會造成MAC地址泄露,這個漏洞曾被用于尋找梅麗莎病毒的制作者位置。
ID作為主鍵時在特定的環境會存在一些問題,比如做DB主鍵的場景下,UUID就非常不適用:
① MySQL官方有明確的建議主鍵要盡量越短越好[4],36個字符長度的UUID不符合要求。
② 對MySQL索引不利:如果作為數據庫主鍵,在InnoDB引擎下,UUID的無序性可能會引起數據位置頻繁變動,嚴重影響性能。
二.類snowflake方案
這種方案大致來說是一種以劃分命名空間(UUID也算,由于比較常見,所以單獨分析)來生成ID的一種算法,這種方案把64-bit分別劃分成多段,分開來標示機器、時間等
這種方式的優缺點是:
優點:
毫秒數在高位,自增序列在低位,整個ID都是趨勢遞增的。
不依賴數據庫等第三方系統,以服務的方式部署,穩定性更高,生成ID的性能也是非常高的。
可以根據自身業務特性分配bit位,非常靈活。
缺點:
強依賴機器時鐘,如果機器上時鐘回撥,會導致發號重復或者服務會處于不可用狀態。
三。數據庫生成
以MySQL舉例,利用給字段設置auto_increment_increment和auto_increment_offset來保證ID自增,每次業務使用下列SQL讀寫MySQL得到ID號。
begin;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
commit;
這種方案的優缺點如下:
優點:
非常簡單,利用現有數據庫系統的功能實現,成本小,有DBA專業維護。
ID號單調自增,可以實現一些對ID有特殊要求的業務。
缺點:
強依賴DB,當DB異常時整個系統不可用,屬于致命問題。配置主從復制可以盡可能的增加可用性,但是數據一致性在特殊情況下難以保證。主從切換時的不一致可能會導致重復發號。
ID發號性能瓶頸限制在單臺MySQL的讀寫性能。
對于MySQL性能問題,可用如下方案解決:在分布式系統中我們可以多部署幾臺機器,每臺機器設置不同的初始值,且步長和機器數相等。
比如有兩臺機器。設置步長step為2,TicketServer1的初始值為1(1,3,5,7,9,11…)、TicketServer2的初始值為2(2,4,6,8,10…)。
這是Flickr團隊在2010年撰文介紹的一種主鍵生成策略(Ticket Servers: Distributed Unique Primary Keys on the Cheap )。
如下所示,為了實現上述方案分別設置兩臺機器對應的參數,TicketServer1從1開始發號,TicketServer2從2開始發號,兩臺機器每次發號之后都遞增2。
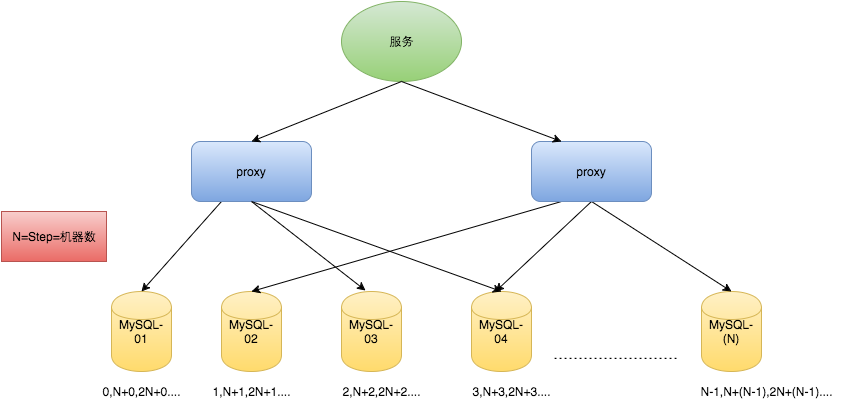
這種架構貌似能夠滿足性能的需求,但有以下幾個缺點:
Leaf這個名字是來自德國哲學家、數學家萊布尼茨的一句話: >There are no two identical leaves in the world > “世界上沒有兩片相同的樹葉”
綜合對比上述幾種方案,每種方案都不完全符合我們的要求。所以Leaf分別在上述第二種和第三種方案上做了相應的優化,實現了Leaf-segment和Leaf-snowflake方案。
第一種Leaf-segment方案,在使用數據庫的方案上,做了如下改變: - 原方案每次獲取ID都得讀寫一次數據庫,造成數據庫壓力大。改為利用proxy server批量獲取,每次獲取一個segment(step決定大小)號段的值。用完之后再去數據庫獲取新的號段,可以大大的減輕數據庫的壓力。 - 各個業務不同的發號需求用biz_tag字段來區分,每個biz-tag的ID獲取相互隔離,互不影響。如果以后有性能需求需要對數據庫擴容,不需要上述描述的復雜的擴容操作,只需要對biz_tag分庫分表就行。
數據庫表設計如下:
+-------------+--------------+------+-----+-------------------+-----------------------------+| Field | Type | Null | Key | Default | Extra | +-------------+--------------+------+-----+-------------------+-----------------------------+| biz_tag | varchar(128) | NO | PRI | | | | max_id | bigint(20) | NO | | 1 | | | step | int(11) | NO | | NULL | | | desc | varchar(256) | YES | | NULL | | | update_time | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP | +-------------+--------------+------+-----+-------------------+-----------------------------+
重要字段說明:biz_tag用來區分業務,max_id表示該biz_tag目前所被分配的ID號段的最大值,step表示每次分配的號段長度。原來獲取ID每次都需要寫數據庫,現在只需要把step設置得足夠大,比如1000。那么只有當1000個號被消耗完了之后才會去重新讀寫一次數據庫。讀寫數據庫的頻率從1減小到了1/step,大致架構如下圖所示:
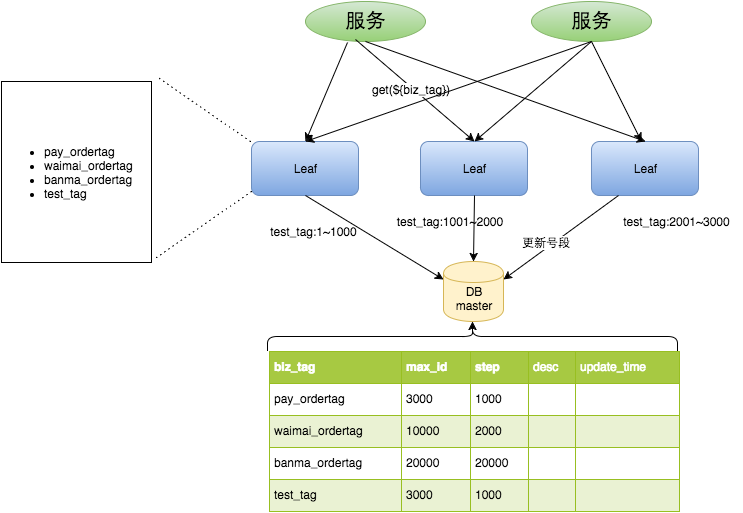
test_tag在第一臺Leaf機器上是1~1000的號段,當這個號段用完時,會去加載另一個長度為step=1000的號段,假設另外兩臺號段都沒有更新,這個時候第一臺機器新加載的號段就應該是3001~4000。同時數據庫對應的biz_tag這條數據的max_id會從3000被更新成4000,更新號段的SQL語句如下:
BeginUPDATE table SET max_id=max_id+step WHERE biz_tag=xxxSELECT tag, max_id, step FROM table WHERE biz_tag=xxxCommit
這種模式有以下優缺點:
優點:
缺點:
對于第二個缺點,Leaf-segment做了一些優化,簡單的說就是:
Leaf 取號段的時機是在號段消耗完的時候進行的,也就意味著號段臨界點的ID下發時間取決于下一次從DB取回號段的時間,并且在這期間進來的請求也會因為DB號段沒有取回來,導致線程阻塞。如果請求DB的網絡和DB的性能穩定,這種情況對系統的影響是不大的,但是假如取DB的時候網絡發生抖動,或者DB發生慢查詢就會導致整個系統的響應時間變慢。
為此,我們希望DB取號段的過程能夠做到無阻塞,不需要在DB取號段的時候阻塞請求線程,即當號段消費到某個點時就異步的把下一個號段加載到內存中。而不需要等到號段用盡的時候才去更新號段。這樣做就可以很大程度上的降低系統的TP999指標。詳細實現如下圖所示:
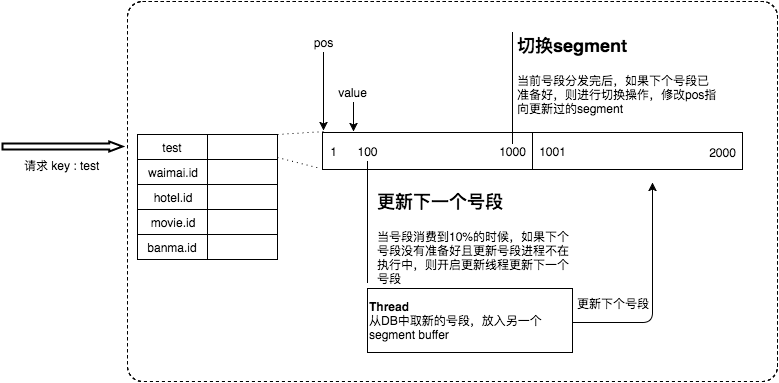
采用雙buffer的方式,Leaf服務內部有兩個號段緩存區segment。當前號段已下發10%時,如果下一個號段未更新,則另啟一個更新線程去更新下一個號段。當前號段全部下發完后,如果下個號段準備好了則切換到下個號段為當前segment接著下發,循環往復。
每個biz-tag都有消費速度監控,通常推薦segment長度設置為服務高峰期發號QPS的600倍(10分鐘),這樣即使DB宕機,Leaf仍能持續發號10-20分鐘不受影響。
每次請求來臨時都會判斷下個號段的狀態,從而更新此號段,所以偶爾的網絡抖動不會影響下個號段的更新。
對于第三點“DB可用性”問題,我們目前采用一主兩從的方式,同時分機房部署,Master和Slave之間采用 半同步方式[5] 同步數據。同時使用公司Atlas數據庫中間件(已開源,改名為 DBProxy )做主從切換。當然這種方案在一些情況會退化成異步模式,甚至在 非常極端 情況下仍然會造成數據不一致的情況,但是出現的概率非常小。如果你的系統要保證100%的數據強一致,可以選擇使用“類Paxos算法”實現的強一致MySQL方案,如MySQL 5.7前段時間剛剛GA的 MySQL Group Replication 。但是運維成本和精力都會相應的增加,根據實際情況選型即可。
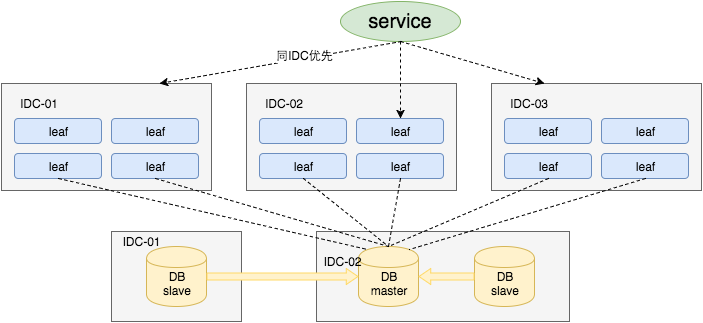
同時Leaf服務分IDC部署,內部的服務化框架是“MTthrift RPC”。服務調用的時候,根據負載均衡算法會優先調用同機房的Leaf服務。在該IDC內Leaf服務不可用的時候才會選擇其他機房的Leaf服務。同時服務治理平臺OCTO還提供了針對服務的過載保護、一鍵截流、動態流量分配等對服務的保護措施。
Leaf-segment方案可以生成趨勢遞增的ID,同時ID號是可計算的,不適用于訂單ID生成場景,比如競對在兩天中午12點分別下單,通過訂單id號相減就能大致計算出公司一天的訂單量,這個是不能忍受的。面對這一問題,我們提供了 Leaf-snowflake方案。
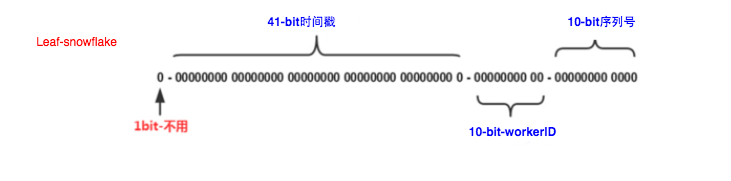
Leaf-snowflake方案完全沿用snowflake方案的bit位設計,即是“1+41+10+12”的方式組裝ID號。對于workerID的分配,當服務集群數量較小的情況下,完全可以手動配置。Leaf服務規模較大,動手配置成本太高。所以使用Zookeeper持久順序節點的特性自動對snowflake節點配置wokerID。Leaf-snowflake是按照下面幾個步驟啟動的:
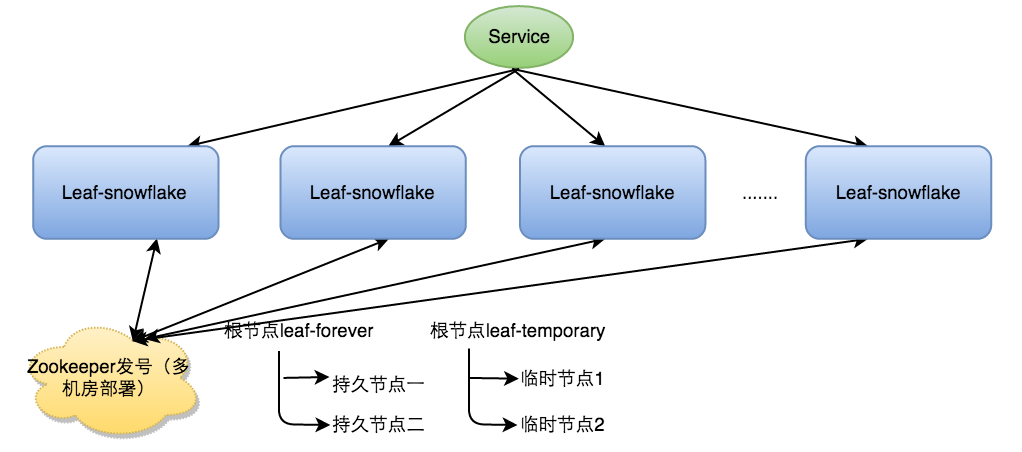
除了每次會去ZK拿數據以外,也會在本機文件系統上緩存一個workerID文件。當ZooKeeper出現問題,恰好機器出現問題需要重啟時,能保證服務能夠正常啟動。這樣做到了對三方組件的弱依賴。一定程度上提高了SLA
因為這種方案依賴時間,如果機器的時鐘發生了回撥,那么就會有可能生成重復的ID號,需要解決時鐘回退的問題。
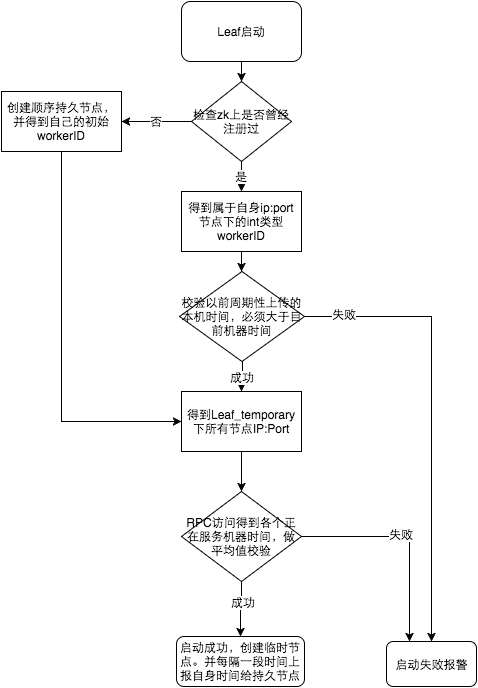
參見上圖整個啟動流程圖,服務啟動時首先檢查自己是否寫過ZooKeeper leaf_forever節點:
由于強依賴時鐘,對時間的要求比較敏感,在機器工作時NTP同步也會造成秒級別的回退,建議可以直接關閉NTP同步。要么在時鐘回撥的時候直接不提供服務直接返回ERROR_CODE,等時鐘追上即可。 或者做一層重試,然后上報報警系統,更或者是發現有時鐘回撥之后自動摘除本身節點并報警 ,如下:
//發生了回撥,此刻時間小于上次發號時間
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp; if (offset <= 5) { try { //時間偏差大小小于5ms,則等待兩倍時間
wait(offset << 1);//wait
timestamp = timeGen(); if (timestamp < lastTimestamp) { //還是小于,拋異常并上報
throwClockBackwardsEx(timestamp);
}
} catch (InterruptedException e) {
throw e;
}
} else { //throw
throwClockBackwardsEx(timestamp);
}
} //分配ID
從上線情況來看,在2017年閏秒出現那一次出現過部分機器回撥,由于Leaf-snowflake的策略保證,成功避免了對業務造成的影響。
Leaf在美團點評公司內部服務包含金融、支付交易、餐飲、外賣、酒店旅游、貓眼電影等眾多業務線。目前Leaf的性能在4C8G的機器上QPS能壓測到近5w/s,TP999 1ms,已經能夠滿足大部分的業務的需求。每天提供億數量級的調用量,作為公司內部公共的基礎技術設施,必須保證高SLA和高性能的服務,我們目前還僅僅達到了及格線,還有很多提高的空間。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





