這是有生之年系列的填坑_(:з」∠)_
Nginx的TCP反向代理的聯動帖:http://blog.itpub.net/29510932/viewspace-1842929/
-------------------------------------------------------------------------------------正文------------------------------------------------------------------------------------
背景:懶癌晚期,整理好發上來;
環境:MySQL-5.7.9 x 4,Nging-1.9.7 x 1,五臺虛擬機
總體思路:
四個MySQL實例組成雙主雙從的多源復制結構,Nginx放在前端,對應用層屏蔽DB層細節
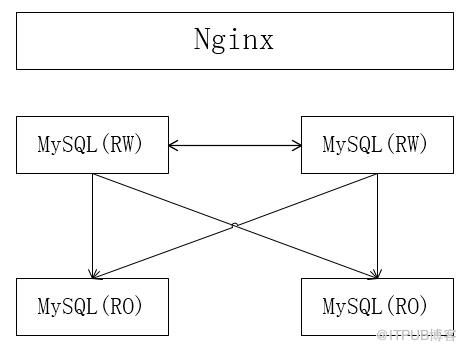
配置簡記:
MySQL的雙主配置和普通的雙主配置沒什么區別,并且在這次搭建中打開了GTID;
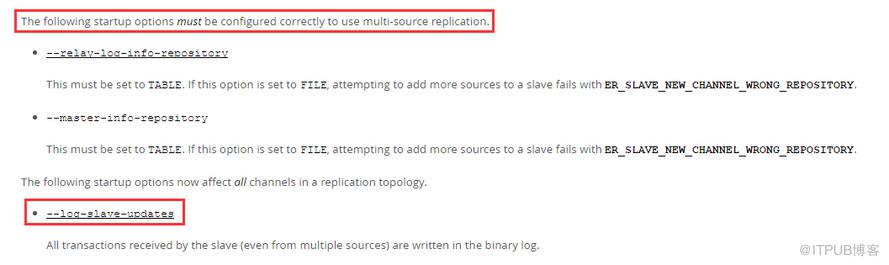
從庫開啟多源復制需要設置
--master-info-repository=TABLE --relay-log-info-repository=TABLE
從庫開啟多源復制用的channel,注意一下語法就好;
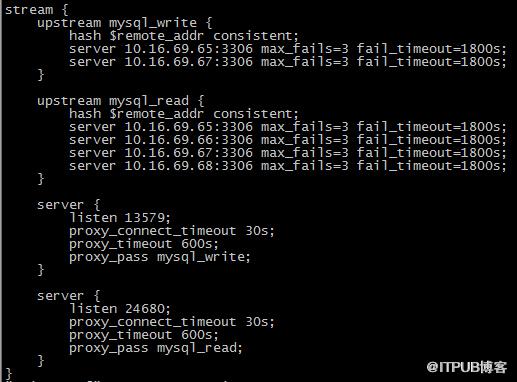
Nginx的TCP轉發功能參考另外一篇博客,這次試驗的簡單配置如截圖
驗證:
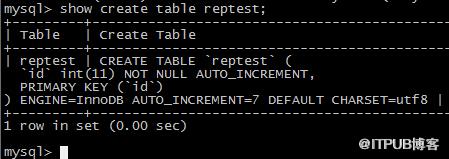
先是看看復制的情況,建立一個測試表
隨便插入幾條數據,看看從庫的status
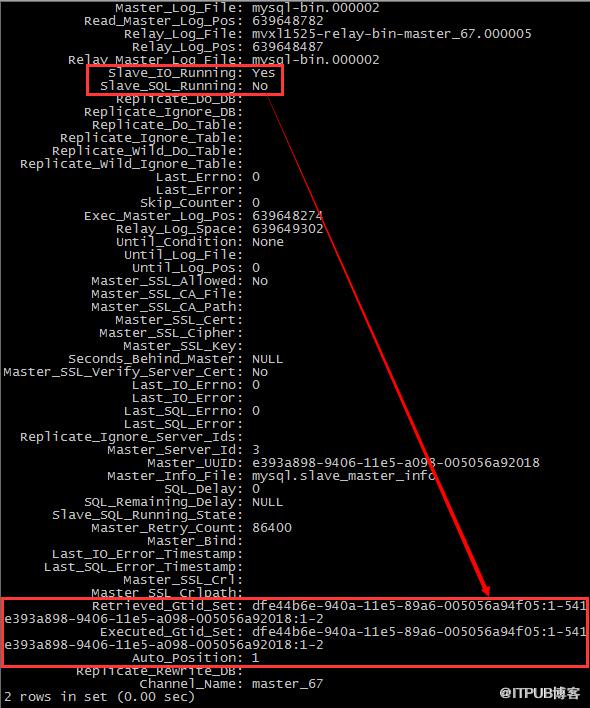
可以看到從庫的status里面有兩個主庫的GTID信息
提問:為什么指向67的channel會有兩個主庫的GTID信息?
解惑:看一下67的relay-log的信息
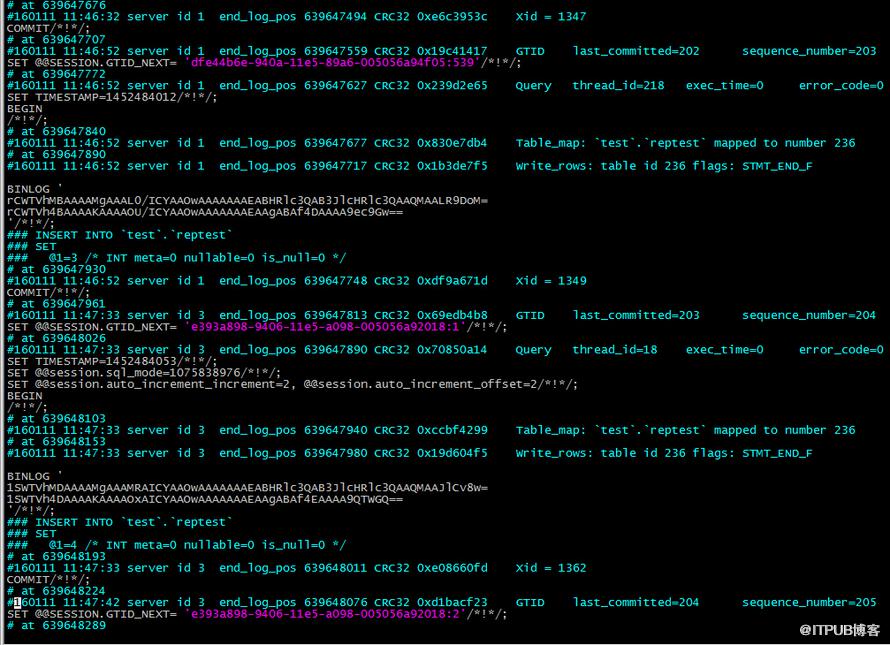
看到relay-log同時包含了兩個主庫的事務信息,原因在于兩個主庫同時開啟了log-slave-updates,所以在relay-log里面包含了兩個主庫的事務;
追問:那么channel_67的relay-log包含兩個主庫的事務,是不是這個67主庫的channel在復現事務時,過濾掉了65主庫的日志呢?
解惑:關掉channel_67的SQL_THREAD之后,在兩個主庫上分別執行一下語句,再看看從庫的status
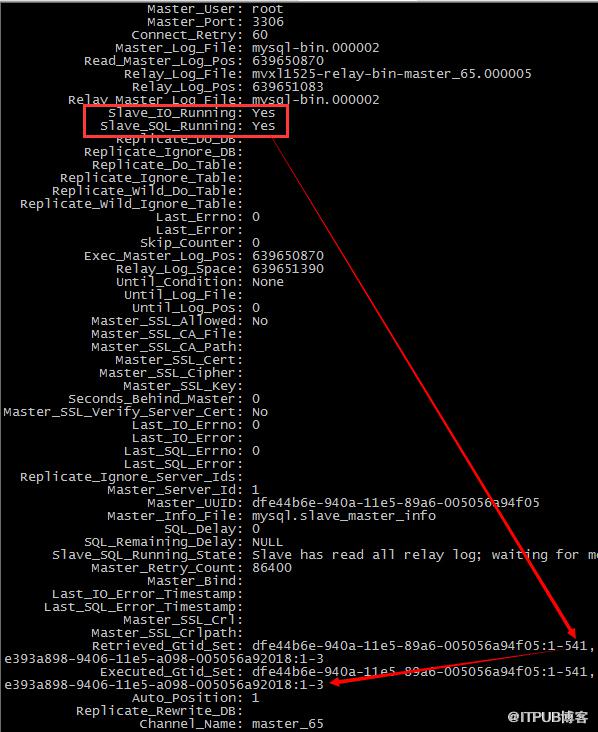
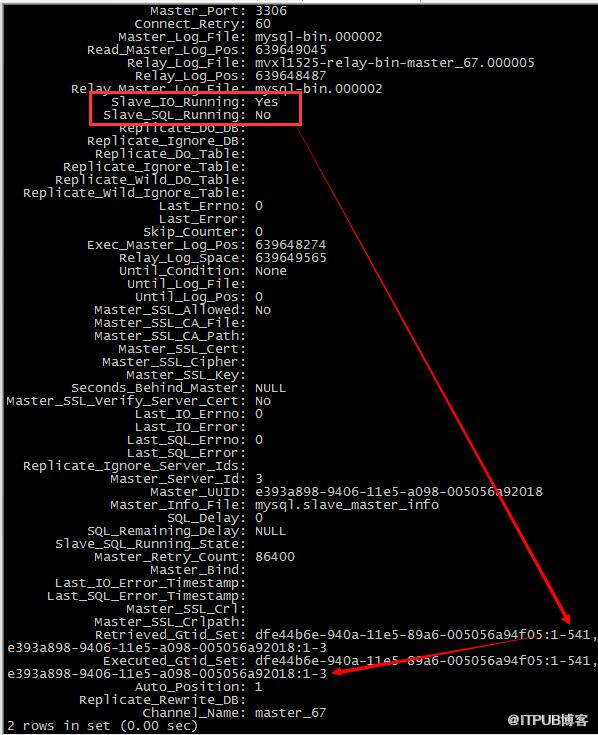
發現停掉channel_67的SQL_THREAD之后,67的事務依然被更新了,從對比上來看,是channel_65的SQL_THREAD更新的,
那么同時停掉65和67的SQL_THREAD,看看效果;
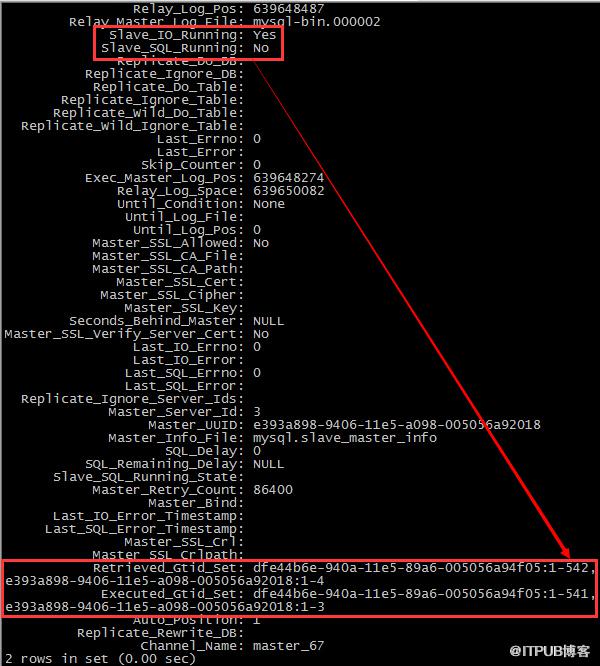
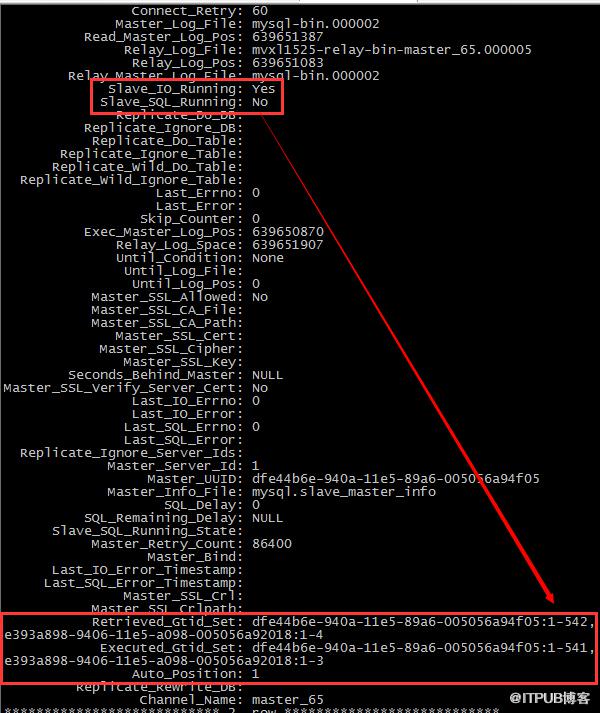
基本可以得出一個結論:channel的SQL_THREAD并沒有過濾掉非master的日志,而是忠實的復現了每一個記錄在relay-log里面的事務;
追問:既然兩個channel都會執行relay-log的所有事務,那么為什么沒有報錯?
解惑/推測:SQL_THREAD在復現relay-log的時候,會檢查一下已經執行過的事務,如果是重復的,則會跳過;
提問:在雙主的MySQL上關閉log-slave-updates,從庫的同步是否會有問題/不同?
解惑:動手測試,關閉slave-log-update之后再觀察從庫的relay-log;
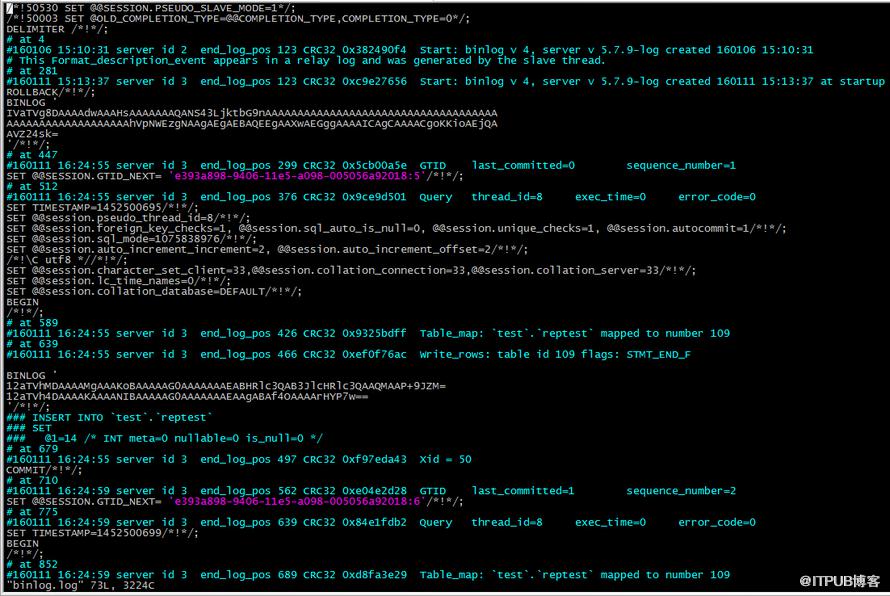
可以看到relay-log里面沒有主庫65的事務信息了,那么再看一下slave status


可以發現,各個channel不再收到另外的主庫的日志,不過已執行事務的GTID信息還是有同步的;
得出的結論:沒有出現問題,且各個channel都單獨處理各自主庫的事務信息,為了數據流向的清晰和明確,在雙主配置中關閉slave-log-update比較好;
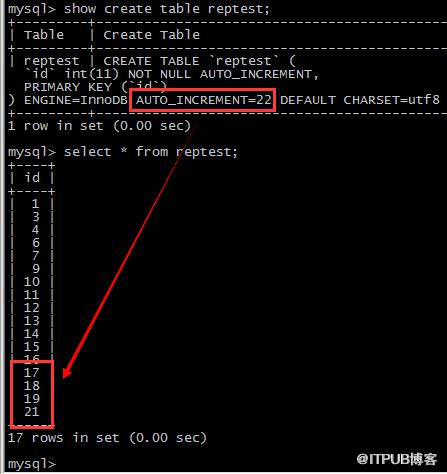
延伸提問:假設channel_67的SQL_THREAD停止一段時間,使得67的insert語句沒有復現(假設插入值為18),而65的insert全部復現了(插入值為19和21),
從庫上的AUTO_INCREMENT計數器是否會出錯?
準備完環境以后,處于缺少18的狀態,效果如下圖
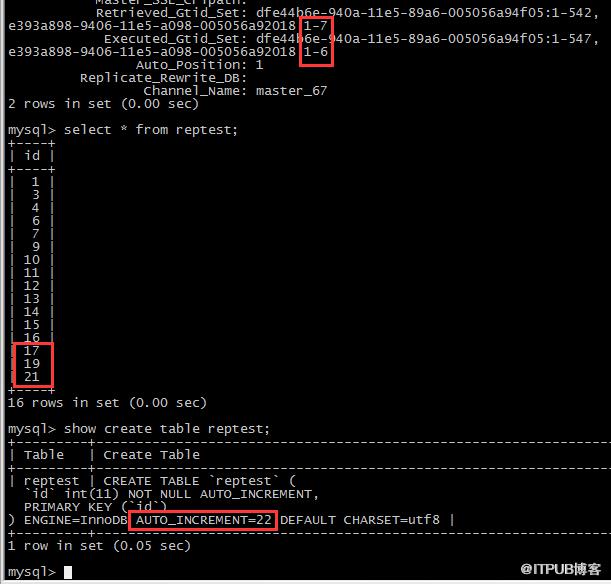
relay-log的信息中包含了缺少的事務;

從結果來看,一切ok
試驗還在進行中, Nginx的部分留給下半部分,先欠著..._(:з」∠)_...
-------------------------------------------------------------------------------------待續------------------------------------------------------------------------------------
PS:在5.6.x版本,開啟GTID必須要開啟log-slave-updates,通過查閱資料,推斷為auto_position所需要,所以需要開啟這個選項,不過在5.7.9已經不是必要條件了。