溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何理解MySQL升級WRITE_SET后死鎖的產生,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
MySQL在推出MGR的時候使用了WRITE_SET, 借用這個思想, MySQL在5.7.22版本引入了基于WRITE_SET的并行復制方案[1]。在原先的主從復制技術中,同一批次的事物能進入事物的prepare階段說明那批事物沒有沖突,所以可以并發執行。我們都知道innodb是基于行鎖的數據庫,所以如果能夠按照行級別的粒度來并發的回放數據會對性能有很大的提高。采用這套方案的性能優點就有很多方面了,其中一個可以簡單看到的好處就是:我們在回放的時候就不用依賴于主上事物提交的情況了,正所謂less is more。減少了依賴,并行從宏觀上也能按照邏輯行這樣的來回放,所以性能肯定有很大的提升[2]. 故而,我們數據庫這邊在一些實例上啟用了這個并行回放特性。
導致我們死鎖的現象是: 我們發現開啟了write_set并行回放的實例從庫上死鎖的概率比以前高了不少, 并且發生死鎖的實例都是在進行xtrabackup備份。
我們知道MySQL事物會設計到很多的鎖,比如MDL鎖,innodb的行鎖,意向鎖,latch 鎖等等。不同的隔離級別鎖的行為也有很多的差異。從死鎖理論的角度:死鎖就是有向圖中存在環,從而造成相互等待。要解決死鎖只要簡單的破壞任何一條邊,來打破環行等待。當然實際的實現可能會因各個環節點的權重不同而有所優化,選擇代價最小的。但之前的重點肯定是找出這個“環”。而這些鎖有些是運維的時候可以看到有些是看不到的。比如latch鎖一般對用戶看不到。因為性能原因,我們的MDL鎖和INNODB鎖的詳細信息并未收集。如果開啟了,就可以通過performance_schema.metadata_lock這個表來查詢MDL鎖的相關信息,通過show engine innodb status來查看詳細innodb的加鎖信息。
通過簡單的分析,我們鎖定是MDL死鎖。所以在這樣的場景下,我們只能通過show full processlist來查看到當時的狀態,如下圖:
case1: 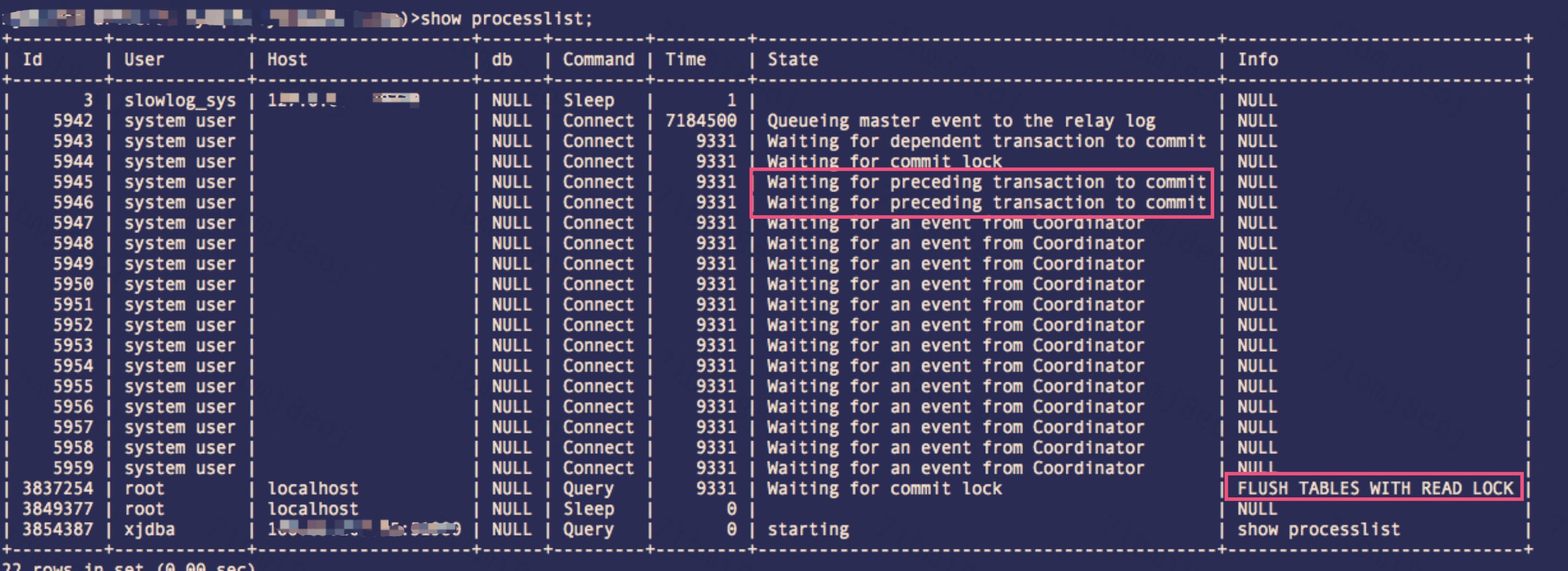 圖1
圖1
case2: 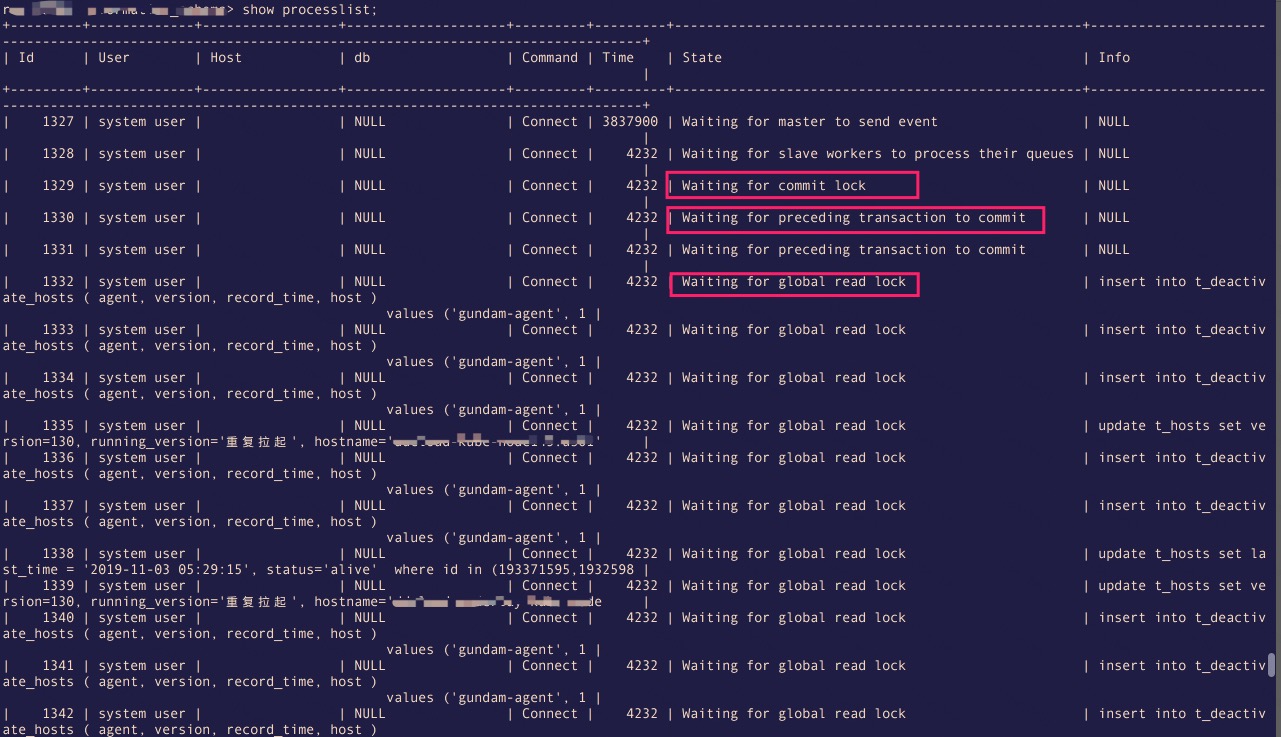 圖2-1
圖2-1
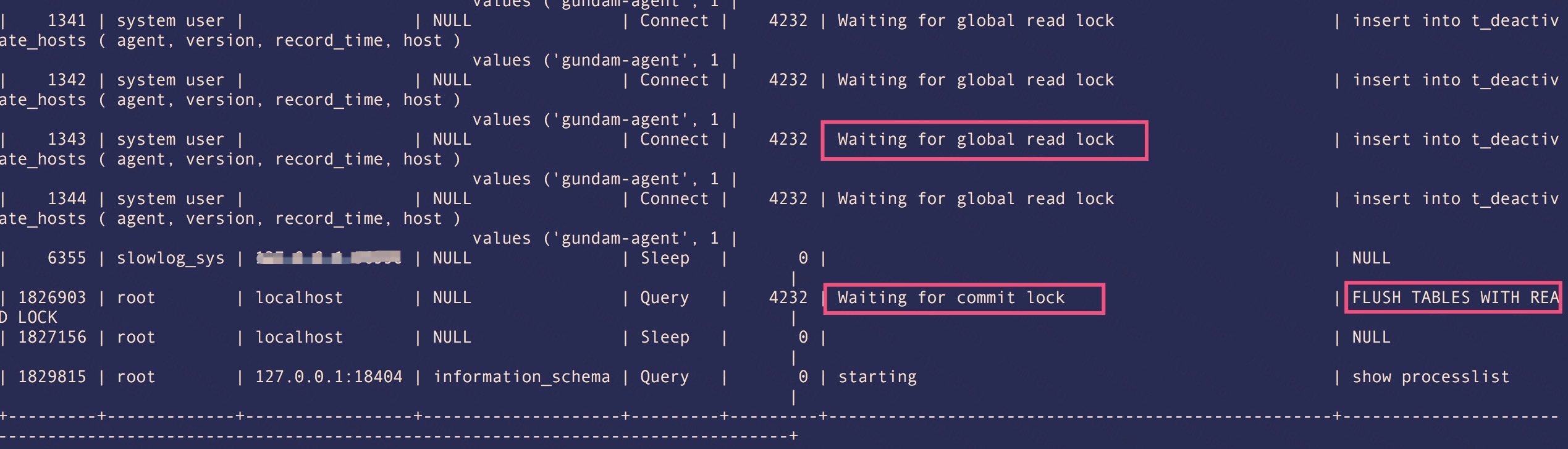 圖2-2
圖2-2
===
為了方便大家理解, 我畫了一個示意圖[圖3]來解釋這兩個case的死鎖情況:  圖3
圖3
case1 死鎖分析:
可以看到在work線程組中,有一個work處理的事物先到達了事物的提交狀態, 但是事物在提交前需要進行 order_commit判斷,因為我們設置了slave_preserve_commit_order ,要保證事物是按照主庫上的提交順序來提交的。所以這個時候必須等待之前的事物要提交才可以進行。所以看到這個線程的狀態是: "Waiting for preceding transaction to commit"。當那個"靠前"的事物準備提交的時候要去拿mdl::commit_lock這把鎖,發現要不到。形成如上的“環等待”。
通過分析可以知道,這個時候同時執行了 FTWRL (flush table with read lock), 而這個操作會獲取到MDL的一個共享鎖。但是同樣沒有版本獲取mdl::commit_lock 而等待。這個等待會造成新來的更新請求被阻塞,因為更新的語句是排他類型的鎖。由于篇幅的原因,不細說MDL鎖兼容細節。這里只給出結論,會阻塞部分更新的語句,進而會影響到業務。
=== 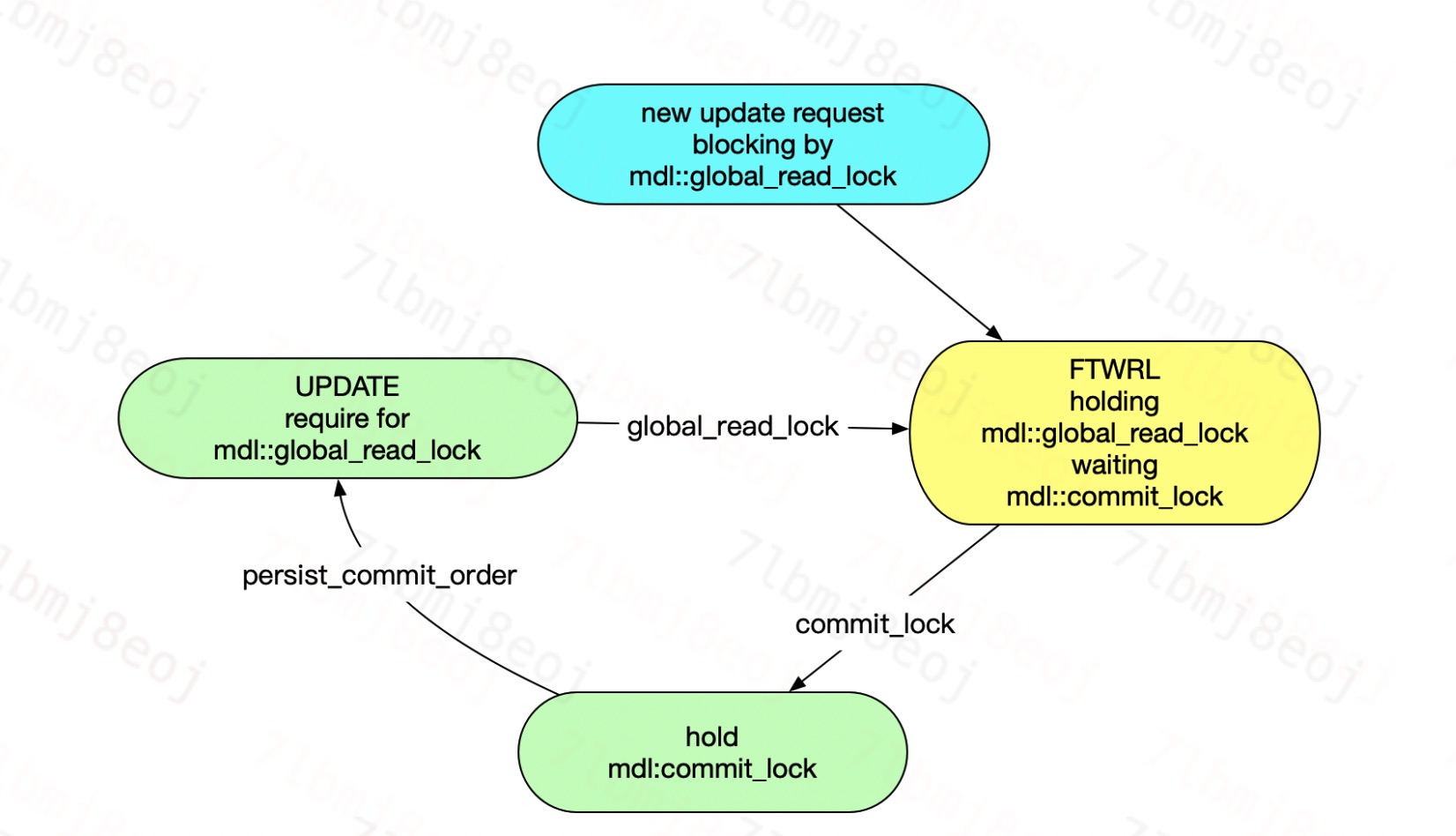 圖4
圖4
case2 死鎖分析:
順便提一句: 同樣可以看到,這種情況下新的請求被阻塞主。注意,這也正是備份的核心思想。阻塞新來的請求,阻塞同批次的提交。保證在備份的時候沒有新的數據插入
一開始一個比較"靠后"的事物獲取了mdl::commit_lock,在準備提交的時候,發現系統配置了slave_preserve_commit_order,同時該事物的前面還有事物未提交,需要等待前面的事物先執行完成后才能繼續。然后FTWRL先獲取了mdl::global_read_lock鎖,但是沒有辦法獲取mdl::commit_lock鎖。
這個時候如果這個“前面的事物”是更新操作,那么就跟mdl::global_read_lock鎖互斥,故而形成上面的死鎖。
由于這樣的死鎖,是概率出現的。為了高效的復現問題,我們打算使用mysql的測試框架來驗證. 第一個步驟是:通過上面的分析,修改內核源碼加大死鎖的概率。證明我們的猜想確實能夠出現死鎖。但是這個出現的死鎖并不一定就是線上真是環境的死鎖。故而需要我們把修改的源碼在實際場景下面驗證。當然我們沒有辦法在生產環境來驗證。我們可以通過第一步修改的源碼,然后使用備份的數據來模擬。如果使用備份的數據 + 我們修改的源碼數據庫實例復現了,才能客觀的判斷我們的死鎖研判。當然讀者可能說我們修改源碼破壞了之前的環境,這里當然是有前提的。這個前提就是:只修改并行回放線程組中的某一個線程,不改變原有邏輯,只是單純的讓它支持慢一點來提高死鎖的概率,作證我們的死鎖研判。
首先我們的第一步就是要:在主庫上產生兩個事物(當然我們也可以使用蠻力,循環,不過可能效果差,甚至可能無法復現),使用MySQL的測試框架,祥見如下的代碼:
57 # =========================== 58 # 在master上創建兩個鏈接master和master1 59 --source include/rpl_connection_master.inc 60 send SET DEBUG_SYNC='waiting_in_the_middle_of_flush_stage SIGNAL w WAIT_FOR b'; 61 62 --source include/rpl_connection_master1.inc 63 send SET DEBUG_SYNC= 'now WAIT_FOR w'; 64 65 --source include/rpl_connection_master.inc 66 --reap 67 show master status; 68 send insert into test.t1 values(1); 69 70 --source include/rpl_connection_master1.inc 71 --reap 72 SET DEBUG_SYNC= 'bgc_after_enrolling_for_flush_stage SIGNAL b'; 73 insert into test.t1 values(1000);
如何驗證我們的主庫上這兩個事物屬于同一個批次呢?當然是binlog啦。結果如下:
show master status; File Position Binlog_Do_DB Binlog_Ignore_DB Executed_Gtid_Set master-bin.000001 849#200107 9:26:14 server id 1 end_log_pos 219 CRC32 0x059fa77a Anonymous_GTID last_committed=0 sequence_number=1 rbr_only=no#200107 9:26:24 server id 1 end_log_pos 408 CRC32 0xa1a6ea99 Anonymous_GTID last_committed=1 sequence_number=2 rbr_only=yes#200107 9:26:24 server id 1 end_log_pos 661 CRC32 0x2b0fc8a5 Anonymous_GTID last_committed=1 sequence_number=3 rbr_only=yes
可以看到last_commit這個字段我們一共產生了兩組binlog, 一個是0 這里是create table 語句。另外一個是1, 就是我們上面的兩條insert 語句。
接下來就是就是要修改MySQL的源代碼了,這里主要是要考慮到MTS的并行復制邏輯。因為我們在主庫上通過DEBUG_SYNC讓大的事物先執行,所以比如是大的事物先分配到woker線程組中的第一個。所以我們在binlog回放的關鍵路徑上: Xid_apply_log_event::do_apply_event_worker 這個函數中讓第一個worker sleep足夠多的時間讓我們執行FTWRL。
直接修改源代碼編譯需要來回的編譯,我們這邊使用systemstap 這個工具,JIT在運行時注入一段代碼來改變某些worker的行為。在執行注入前先執行腳本驗證下能否注入:
41 --exec sudo stap -L 'process("$MYSQLD").function("pop_jobs_item")'
42 --exec sudo stap -L 'process("$MYSQLD").function("*Xid_apply_log_event::do_apply_event_worker")'需要注意的是,因為stap的架構原理的原因,詳細可參考下面的鏈接[3],需要root權限。下面是注入的代碼:
stap -v -g -d $MYSQLD --ldd -e 'probe process($server_pid).function("Xid_apply_log_event ::Xid_apply_log_event
") {printf("hit in do_apply_log_event\n") if ($w->id ==0) { mdelay(30000)} }'
stap -v -g -d $MYSQLD --ldd -e 'probe process($server_pid).function("pop_jobs_item") { printf("hit in
pop_jobs_item") if ($worker->id == 0) { mdelay(3000)} }'大致的意思就是: 讓復制線程組的第一個線程sleep 3s。這樣有足夠的時間來運行FTWRL。最終的執行結果:
show full processlist; Id User Host db Command Time State Info 3 root localhost:10868 test Sleep 83 NULL 4 root localhost:10870 test Sleep 84 NULL 7 root localhost:10922 test Query 61 Waiting for commit lock flush table with read lock 8 root localhost:10926 test Query 0 starting show full processlist 9 system user NULL Connect 82 Waiting for master to send event NULL 10 system user NULL Connect 61 Slave has read all relay log; waiting for more updates NULL 11 system user NULL Connect 71 Waiting for global read lock NULL 12 system user NULL Connect 71 Waiting for preceding transaction to commit NULL 13 system user NULL Connect 82 Waiting for an event from Coordinator NULL 14 system user NULL Connect 81 Waiting for an event from Coordinator NULL
可以看到,我們的猜想完整的復現了死鎖。大致解釋下:
我們在構造這個死鎖的時候,因為我們控制 的worker會sleep 3s。故而我們可以查詢worker的狀態,當worker處于 Waiting for preceding transaction to commit 這個狀態的時候,立馬執行FTWRL。然后可以看到FTWRL會block在commit_lock。然后另外一個更新自然是要等待: global read lock, 而形成死鎖。
首先對于不太理解備份原理的同學,應該可以從這兩個死鎖等待圖中清楚的看到FTWRL的作用。它是通過兩把GLOBAL READ LOCK 和COMMIT_LOCK鎖來控制備份的一致性。這里不詳細討論。 解決死鎖問題,通過死鎖理論,肯定是要打破有向圖中的環。
在我們的這個死鎖case中通過分析可以知道可以操作的兩條邊只有:
1. slave_preserve_commit_order
2. FTWRL 顯然:對于那些可以接受在從庫上事物的提交可以“亂序”的,我們只要關閉這個配置選項就可以解除死鎖
而如果是要強制要求有序的,那么我們只能關閉備份的線程(圖中的節點,及相關的邊) 同樣可以破解死鎖。在死鎖出現的時候,個人覺得關閉備份線程代碼是更小的。如果關閉worker線程的話,從庫復制會出錯誤。
關于如何理解MySQL升級WRITE_SET后死鎖的產生就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





