溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關MySQL中數據源管理和關系型分庫分表以及列式庫分布式計算分別指的是什么,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
隨著業務發展,數據量的越來越大,業務系統越來越復雜,拆分的概念邏輯就應運而生。數據層面的拆分,主要解決部分表數據過大,導致處理時間過長,長期占用鏈接,甚至出現大量磁盤IO問題,嚴重影響性能;業務層面拆分,主要解決復雜的業務邏輯,業務間耦合度過高,容易引起雪崩效應,業務庫拆分,微服務化分布式,也是當前架構的主流方向。
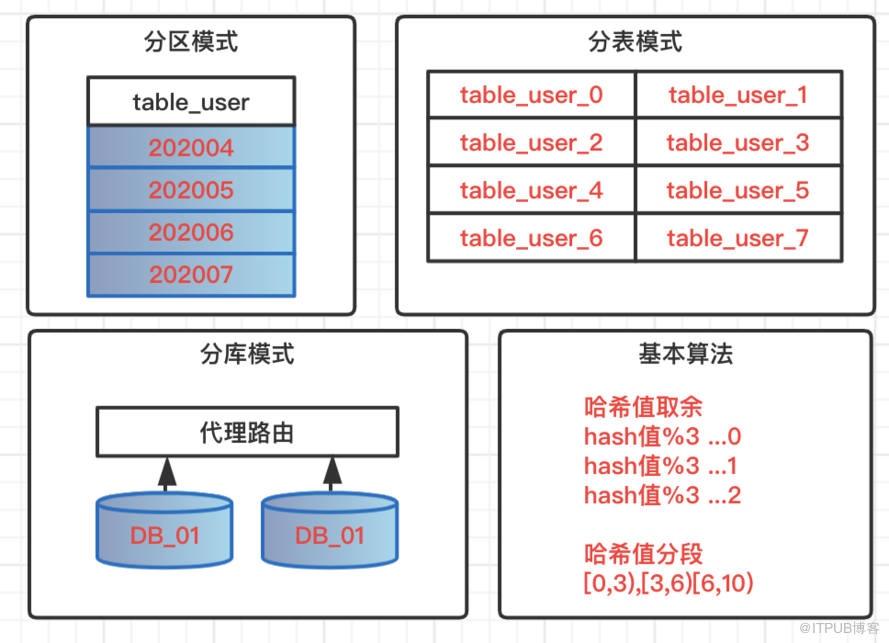
分區模式
針對數據表做分區模式,所有數據,邏輯上還存在一張表中,但是物理堆放不在一起,會根據一定的規則堆放在不同的文件中。查詢數據的時候必須按照指定規則觸發分區,才不會全表掃描。不可控因素過多,風險過大,一般開發規則中都是禁止使用表分區。
分表模式
單表數據量過大,一般情況下單表數據控制在300萬,這里的常規情況是指字段個數,類型都不是極端類型,查詢也不存在大量鎖表的操作。超過該量級,這時候就需要分表操作,基于特定策略,把數據路由到不同表中,表結構相同,表名遵循路由規則。
分庫模式
在系統不斷升級,復雜化場景下,業務不好管理,個別數據量大業務影響整體性能,這時候可以考慮業務分庫,大數據量場景分庫分表,減少業務間耦合度,高并發大數據的資源占用情況,實現數據庫層面的解耦。在架構層面也可以服務化管理,保證服務的高可用和高性能。
常用算法
哈希值取余:根據路由key的哈希值余數,把數據分布到不同庫,不同表;
哈希值分段:根據路由key的哈希值分段區間,實現數據動態分布;
這兩種方式在常規下都沒有問題,但是一旦分庫分表情況下數據庫再次飽和,需要遷移,這時候影響是較大的。
基于一個代理層(這里使用Sharding-Jdbc中間件),指定分庫策略,根據路由結果,找到不同的數據庫,執行數據相關操作。
把需要分庫的數據源統一管理起來。
@Configuration
public class DataSourceConfig {
// 省略數據源相關配置
/**
* 分庫配置
*/
@Bean
public DataSource dataSource (@Autowired DruidDataSource dataZeroSource,
@Autowired DruidDataSource dataOneSource,
@Autowired DruidDataSource dataTwoSource) throws Exception {
ShardingRuleConfiguration shardJdbcConfig = new ShardingRuleConfiguration();
shardJdbcConfig.getTableRuleConfigs().add(getUserTableRule());
shardJdbcConfig.setDefaultDataSourceName("ds_0");
Map<String,DataSource> dataMap = new LinkedHashMap<>() ;
dataMap.put("ds_0",dataZeroSource) ;
dataMap.put("ds_1",dataOneSource) ;
dataMap.put("ds_2",dataTwoSource) ;
Properties prop = new Properties();
return ShardingDataSourceFactory.createDataSource(dataMap, shardJdbcConfig, new HashMap<>(), prop);
}
/**
* 分表配置
*/
private static TableRuleConfiguration getUserTableRule () {
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("user_info");
result.setActualDataNodes("ds_${1..2}.user_info_${0..2}");
result.setDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_phone", new DataSourceAlg()));
result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_phone", new TableSignAlg()));
return result;
}
}路由到庫
根據分庫策略的值,基于hash算法,判斷路由到哪個庫。has算法不同,不但影響庫的操作,還會影響數據入表的規則,比如偶數和奇數,導致入表的奇偶性。
public class DataSourceAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(DataSourceAlg.class);
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
String dataName = "ds_" + ((hash % 2) + 1) ;
LOG.debug("分庫算法信息:{},{},{}",names,value,dataName);
return dataName ;
}
}路由到表
根據分表策略的配置,基于hash算法,判斷路由到哪張表。
public class TableSignAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(TableSignAlg.class);
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
String tableName = "user_info_" + (hash % 3) ;
LOG.debug("分表算法信息:{},{},{}",names,value,tableName);
return tableName ;
}
}上述就是基于ShardingJdbc分庫分表的核心操作流程。
在相對龐大的數據分析時,通常會選擇生成一張大寬表,并且存放到列式數據庫中,為了保證高效率執行,可能會把數據分到不同的庫和表中,結構一樣,基于多線程去統計不同的表,然后合并統計結果。
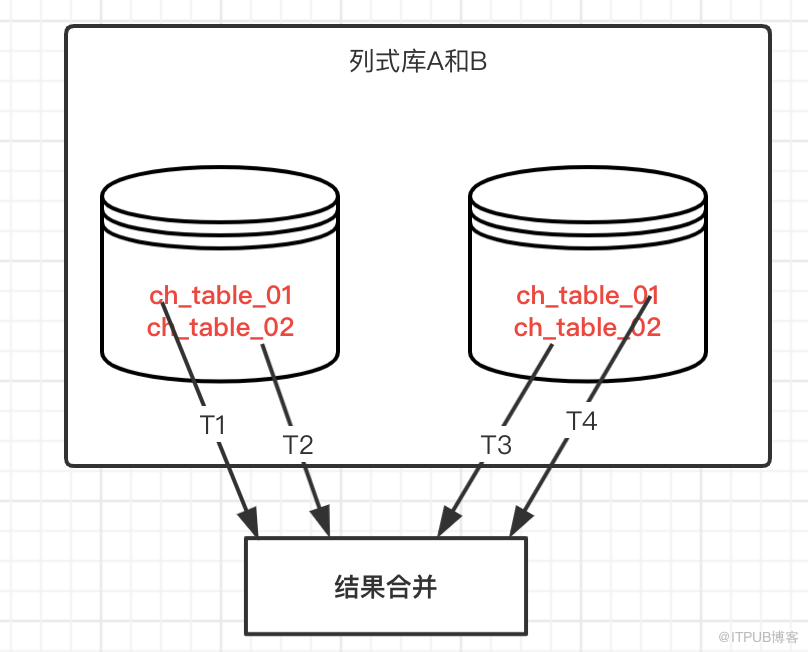
基本原理:多線程并發去執行不同的表的統計,然后匯總統計,相對而言統計操作不難,但是需要適配不同類型的統計,比如百分比,總數,分組等,編碼邏輯相對要求較高。
基于ClickHouse數據源,演示案例操作的基本邏輯。這里管理和配置庫表。
核心配置文件
spring: datasource: type: com.alibaba.druid.pool.DruidDataSource # ClickHouse數據01 ch-data01: driverClassName: ru.yandex.clickhouse.ClickHouseDriver url: jdbc:clickhouse://127.0.0.1:8123/query_data01 tables: ch_table_01,ch_table_02 # ClickHouse數據02 ch-data02: driverClassName: ru.yandex.clickhouse.ClickHouseDriver url: jdbc:clickhouse://127.0.0.1:8123/query_data02 tables: ch_table_01,ch_table_02
核心配置類
@Component
public class ChSourceConfig {
public volatile Map<String, String[]> chSourceMap = new HashMap<>();
public volatile Map<String, Connection> connectionMap = new HashMap<>();
@Value("${spring.datasource.ch-data01.url}")
private String dbUrl01;
@Value("${spring.datasource.ch-data01.tables}")
private String tables01 ;
@Value("${spring.datasource.ch-data02.url}")
private String dbUrl02;
@Value("${spring.datasource.ch-data02.tables}")
private String tables02 ;
@PostConstruct
public void init (){
try{
Connection connection01 = getConnection(dbUrl01);
if (connection01 != null){
chSourceMap.put(connection01.getCatalog(),tables01.split(","));
connectionMap.put(connection01.getCatalog(),connection01);
}
Connection connection02 = getConnection(dbUrl02);
if (connection02 != null){
chSourceMap.put(connection02.getCatalog(),tables02.split(","));
connectionMap.put(connection02.getCatalog(),connection02);
}
} catch (Exception e){e.printStackTrace();}
}
private synchronized Connection getConnection (String jdbcUrl) {
try {
DriverManager.setLoginTimeout(10);
return DriverManager.getConnection(jdbcUrl);
} catch (Exception e) {
e.printStackTrace();
}
return null ;
}
}既然基于多線程統計,自然需要一個線程任務類,這里演示count統計模式。輸出單個線程統計結果。
public class CountTask implements Callable<Integer> {
private Connection connection ;
private String[] tableArray ;
public CountTask(Connection connection, String[] tableArray) {
this.connection = connection;
this.tableArray = tableArray;
}
@Override
public Integer call() throws Exception {
Integer taskRes = 0 ;
if (connection != null){
Statement stmt = connection.createStatement();
if (tableArray.length>0){
for (String table:tableArray){
String sql = "SELECT COUNT(*) AS countRes FROM "+table ;
ResultSet resultSet = stmt.executeQuery(sql) ;
if (resultSet.next()){
Integer countRes = resultSet.getInt("countRes") ;
taskRes = taskRes + countRes ;
}
}
}
}
return taskRes ;
}
}這里主要啟動線程的執行,和最后把每個線程的處理結果進行匯總。
@RestController
public class ChSourceController {
@Resource
private ChSourceConfig chSourceConfig ;
@GetMapping("/countTable")
public String countTable (){
Set<String> keys = chSourceConfig.chSourceMap.keySet() ;
if (keys.size() > 0){
ExecutorService executor = Executors.newFixedThreadPool(keys.size());
List<CountTask> countTasks = new ArrayList<>() ;
for (String key:keys){
Connection connection = chSourceConfig.connectionMap.get(key) ;
String[] tables = chSourceConfig.chSourceMap.get(key) ;
CountTask countTask = new CountTask(connection,tables) ;
countTasks.add(countTask) ;
}
List<Future<Integer>> countList = Lists.newArrayList();
try {
if (countTasks.size() > 0){
countList = executor.invokeAll(countTasks) ;
}
} catch (InterruptedException e) {
e.printStackTrace();
}
Integer sumCount = 0 ;
for (Future<Integer> count : countList){
try {
Integer countRes = count.get();
sumCount = sumCount + countRes ;
} catch (Exception e) {e.printStackTrace();}
}
return "sumCount="+sumCount ;
}
return "No Result" ;
}
}關系型分庫,還是列式統計,都是基于特定策略把數據分開,然后路由找到數據,執行操作,或者合并數據,或者直接返回數據。
GitHub·地址 https://github.com/cicadasmile/data-manage-parent GitEE·地址 https://gitee.com/cicadasmile/data-manage-parent
推薦閱讀:數據管理
| 序號 | 標題 |
|---|---|
| 01 | 數據源管理:主從庫動態路由,AOP模式讀寫分離 |
| 02 | 數據源管理:基于JDBC模式,適配和管理動態數據源 |
| 03 | 數據源管理:動態權限校驗,表結構和數據遷移流程 |
關于MySQL中數據源管理和關系型分庫分表以及列式庫分布式計算分別指的是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





