溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
壓縮原因
1.文件太大,節省空間
2.提高數據在網絡上傳輸的效率
3.對數據起到保護作用---加密
文件壓縮類型
無損壓縮:源文件被壓縮之后,可以通過解壓縮還原成與源文件相同的格式
有損壓縮:源文件被壓縮之后,解壓縮無法還原成與源文件相同,但識別其內容沒有影響,多用于語音,圖片,視頻壓縮
基于Huffman樹的壓縮如何實現
通過Huffman編碼實現,字符一般都是以字節存儲的,通過編碼轉換為二進制編碼(1字節=8比特位)
首先,什么是Huffman樹
給定N個權值作為N個葉子結點,構造一棵二叉樹,若該樹的帶權路徑長度達到最小,稱這樣的二叉樹為最優二叉樹,也稱為哈夫曼樹。哈夫曼樹是帶權路徑長度最短的樹,權值較大的結點離根較近。
例如:給定權值為1(A),3(B),5(C),7(D)四個節點,構建Huffman樹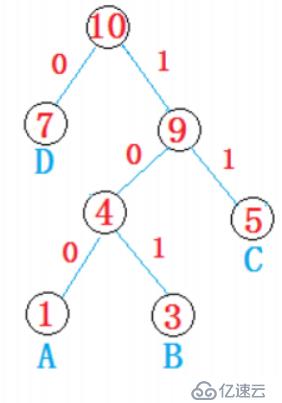
Huffman壓縮原理--基于Huffman編碼
以字符串中每個字符出現的次數為權值構建Huffman樹
從根節點開始,左分支為0,右分支為1,如上圖
所有權值節點都在葉子節點位置,遍歷每條到葉子節點的路徑獲取字符的編碼
舉個栗子:ABBBCCCCCDDDDDDD
Huffman編碼:
A:100
B:101
C:11
D:0
原理就是這么簡單,一個字符占一個字節,現在用二進制編碼代替之后,一個字符只占三位,也就是說一個字節可以表示兩三個字符,所以說一次壓縮,就會節省很多字節,也就起到了壓縮的作用。
項目中最重要的是三點
創建Huffman樹
1 先用權值創建n棵只有根節點的二叉樹森林【意思是先創建n個節點】
2 選取根節點權值最小的二叉樹構建新的二叉樹【建小堆,新二叉樹根節點權值為左右子樹的根節點權值之和】【用到了priority_queue優先級隊列】
3 刪除使用的兩棵根節點權值較小的二叉樹
4 將新創建的二叉樹添加到二叉樹森林中
接下來2-4循環繼續,直到二叉樹森林中只有一棵二叉樹則Huffman樹創建成
文件壓縮過程:
1讀取源文件,讀取源文件中每個字符出現的次數 2 以每個字符出現的次數作為權值,創建huffman樹:小堆--優先級隊列 3 通過huffman樹找每個字符對應的編碼 4 用每個字符的新編碼重新對源文件進行改寫【翻譯的過程】
文件解壓縮的過程:
- 從壓縮文件中獲取源文件的后綴
- 從壓縮文件中獲取字符次數的總行數
- 獲取每個字符出現的次數
- 重建huffman樹
- 解壓壓縮數據
? ? a. 從壓縮文件中讀取一個字節的獲取壓縮數據ch
? ? b. 從根節點開始,按照ch的8個比特位信息從高到低遍歷huffman樹:該比特位是0,取當前節點的左孩子,否則取右孩子,直到遍歷到葉子節點位置,該字符就被解析成功,將解壓出的字符寫入文件,如果在遍歷huffman過程中,8個比特位已經比較完畢還沒有到達葉子節點,從a開始執行
? ? ?c. 重復以上過程,直到所有的數據解析完畢。
寫代碼當中碰到的一些主要的問題,我將這些總結起來:
1.編譯的時候:
剛開始寫的時候測試發現如果壓縮文件中出現了中文,程序就會崩潰,最后發現是數組越界的錯誤,因為如果只是字符,它的范圍是-128~127,程序中使用char類型為數組下標(0~127),所以字符沒有問題.?但是漢字的編碼是兩個字節,所以可能會出現越界,
解決方法:就是將char類型強轉為unsigned char,下標可表示范圍為0~255.
2.解壓縮的時候
有些特殊字符在處理需要注意一下,比如'\n',我的程序中Getline()函數就是讀取一行字符,但是若是該字符本身就是一個'\n'呢??這就非常的棘手了. 因為解壓縮之后出現了亂碼
解決方法:讀取壓縮文件時若讀到了'\n',則說明該字符就是'\n',應該繼續讀取它的次數
3.運行的時候:
發現文件篇幅很長的時候,只能壓縮和解壓縮一部分,是因為字符長度的設定太小
解決方法:_count長度設為unsigned long long類型
4.還有許多大大小小的問題等等
壓縮率
| 文件類型 | 源文件大小 | 壓縮后大小 | 壓縮率 |
|---|---|---|---|
| word文檔 | 31.5KB | 32.1KB | 1.02 |
| 音頻文件 | 29.8 MB | 29.8MB | 0.99 |
| 視頻文件 | 20.7MB | 20.7MB | 0.99 |
全部代碼(GitHub):https://github.com/wake5up/My-c--code/tree/master/compress
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





