溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Python中垃圾回收機制指的是什么,具有一定借鑒價值,需要的朋友可以參考下。希望大家閱讀完這篇文章后大有收獲。下面讓小編帶著大家一起了解一下。
一、寫在前面:
我們都知道Python一種面向對象的腳本語言,對象是Python中非常重要的一個概念。在Python中數字是對象,字符串是對象,任何事物都是對象,而它們的核心就是一個結構體--PyObject。
typedef struct_object{
int ob_refcnt;
struct_typeobject *ob_type;
}PyObject;PyObject是每個對象必有的內容,其中ob_refcnt就是做為引用計數。
二、垃圾回收機制
垃圾回收(Garbage Collection)大家應該多多少少都聽過,但是什么是垃圾回收呢?我們這里說的垃圾回收肯定不是把垃圾丟進垃圾桶。現在的高級語言Java,C#等,都采用了垃圾回收機制,而不再是C,C++里用戶自己管理維護內存的方式,自己管理內存是很自由,但是可能出現內存泄漏,懸空指針等問題。而垃圾回收機制作為現代編程語言的自動內存管理機制,專注于兩件事:1. 找到內存中無用的垃圾資源 2. 清除這些垃圾并把內存讓出來給其他對象使用。
三、Python中的垃圾回收
在Python中,垃圾回收機制主要是以引用計數為主要手段,以標記清除和分代回收機制作為輔助手段實現的。
1、引用計數
通過前面的介紹,我們已經知道PyObject是每個對象必有的內容,而當一個對象有新的引用時,它的ob_refcnt就會增加,當引用它的對象被刪除,它的ob_refcnt就會減少,當引用計數為0時,該對象生命就結束了。
我們來看看引用計數+1的情況有什么:
(1)對象被創建:

這里實際上123這個對象并沒有在內存中新建,因為在Python啟動解釋器的時候會創建一個小整數池,在-5~256之間的整數對象會被自動加載到內存中等待調用。因此a=123是對123這個整數對象增加了一次引用。而456是不在整數池里的,需要創建對象,那么最后的引用次數是2呢?因為sys.getrefcount(b)也是一次引用。
(2)對象被引用:

每一次賦值操作都會增加數據的引用次數,要記住引用的變量a、b、c指向的是數據456,而不是變量本身。
(3)對象作為參數傳遞到函數中:

這里可以很明顯看到在被傳遞到函數中后,引用計數增加了1。
(4)對象作為元素儲存到容器中:

這里我們在創建對象之后,把a分別添加到了一個列表和一個元組中,引用計數都增加了。
雖然引用計數必須在每次分配合釋放內存的時候加入管理引用計數的操作,然而與其他垃圾回收技術相比,引用計數有一個最大的優點,那就是“實時性”,如果這個對象沒有引用,內存就直接釋放了,而其他垃圾回收技術必須在某種特殊條件下才能進行無效內存的回收。但是引用計數帶來的維護引用計數的額外操作和Python中進行的內存分配和釋放,引用的賦值次數成正比的。除此之外,引用計數機制的還有一個最大的軟肋--無法解決循環引用帶來的問題。循環引用可以使一種引用對象的引用計數不為0,然而這些對象實際上并沒有被任何外部對象所引用,它們之間只是相互引用,這意味著這組對象所占用的內存空間是應該被回收的,但是由于循環引用導致的引用計數不為0,所以這組對象所占用的內存空間永遠不會被釋放。如下,list1與list2相互引用,如果不存在其他對象對它們的引用,list1與list2的引用計數也仍然為1,所占用的內存永遠無法被回收,這將是致命的。
list1 = [] list2 = [] list1.append(list2) list2.append(list1)
2、標記清除
標記清除(Mark—Sweep)算法是一種基于追蹤回收(tracing GC)技術實現的垃圾回收算法。它分為兩個階段:第一階段是標記階段,GC會把所有的活動對象打上標記,第二階段是把那些沒有標記的對象非活動對象進行回收。
對象之間通過引用(指針)連在一起,構成一個有向圖,對象構成這個有向圖的節點,而引用關系構成這個有向圖的邊。從根對象(root object)出發,沿著有向邊遍歷對象,可達的(reachable)對象標記為活動對象,不可達的對象就是要被清除的非活動對象。根對象就是全局變量、調用棧、寄存器。
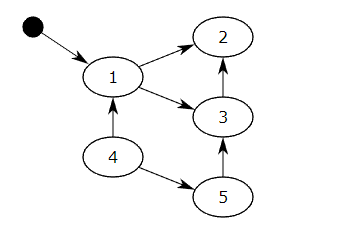
在上圖中,可以從程序變量直接訪問塊1,并且可以間接訪問塊2和3。程序無法訪問塊4和5。第一步將標記塊1,并記住塊2和3以供稍后處理。第二步將標記塊2,第三步將標記塊3,但不記得塊2,因為它已被標記。掃描階段將忽略塊1,2和3,因為它們已被標記,但會回收塊4和5。
標記清除算法作為Python的輔助垃圾收集技術,主要處理的是一些容器對象,比如list、dict、tuple等,因為對于字符串、數值對象是不可能造成循環引用問題。Python使用一個雙向鏈表將這些容器對象組織起來。不過,這種簡單粗暴的標記清除算法也有明顯的缺點:清除非活動的對象前它必須順序掃描整個堆內存,哪怕只剩下小部分活動對象也要掃描所有對象。
3、分代回收
分代回收是建立在標記清除技術基礎之上的,是一種以空間換時間的操作方式。
Python將內存根據對象的存活時間劃分為不同的集合,每個集合稱為一個代,Python將內存分為了3“代”,分別為年輕代(第0代)、中年代(第1代)、老年代(第2代),他們對應的是3個鏈表,它們的垃圾收集頻率與對象的存活時間的增大而減小。新創建的對象都會分配在年輕代,年輕代鏈表的總數達到上限時,Python垃圾收集機制就會被觸發,把那些可以被回收的對象回收掉,而那些不會回收的對象就會被移到中年代去,依此類推,老年代中的對象是存活時間最久的對象,甚至是存活于整個系統的生命周期內。
感謝你能夠認真閱讀完這篇文章,希望小編分享Python中垃圾回收機制指的是什么內容對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,遇到問題就找億速云,詳細的解決方法等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





