溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關什么是編碼集,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
編碼集
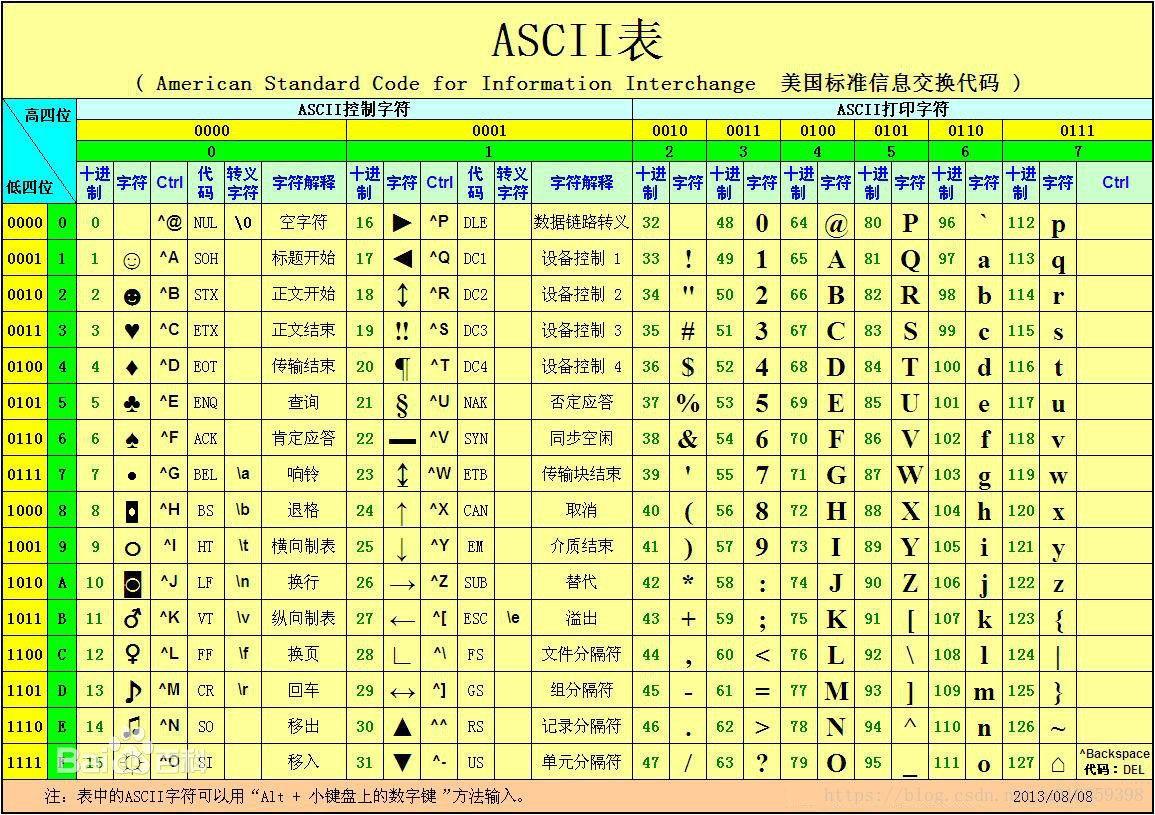
1. ASCII編碼:
127個字母 8個數據位足夠存儲字母、數字、符號,最大支持到0x7F。
2. GB2312編碼
每個漢字占據2個字節(高位和低位),16個數據。GB2312是對ASCII的中文擴展,共包含7000多個漢字。是計算機發展到中國后發展起來的編碼,檢測高位和低位,如果同時大于0x7F,則認為是GB2312,否則認為是ASCII編碼。
3. GBK(1995)和GB18030(2005/2000)
每個漢字占據2個字節,由于漢字的數量太大,GB2312不能滿足需求。GBK包括了GB2312的所有內容,
同時增加了近20000個新的漢字(包括繁體)和符號 。只要求高位大于0x7F,低位可以小于0x7F,認為是中文。
> 國家標準GB18030-2000《信息交換用漢字編碼字符集基本集的補充》是我國繼GB2312-1980和
GB13000-1993之后最重要的漢字編碼標準,包含多種我國少數民族文字,其中收入漢字70000余個。
4.Unicode編碼
> 定長存儲, 將所有語言都統一到一套編碼集,通常使用2個字節,有的是4個字節。收錄很全。
分為17個面,基本面采用2個字節,普通中文子也在基本面中,另外16個面是4個字節。
不兼容ASCII碼,即存儲的時候,對ASCII碼前面補0,導致存儲的數據變大。
5. utf-8---變長存儲
> 國際標準組織(ISO)制定英文字符使用1個字節,沿用原來的ASCII碼。
> 使用1~4個字節表示一個符號,中文存儲使用3個字節(ascii碼中的內容用1個字節保存\歐洲的字符用2個字節保存\東亞的字符用3個字節保存\特殊符號用4個字節)
> Unicode是內存編碼表示方案(規范),而utf-8是如何保存和傳輸Unicode的方案(實現)
> 優點:雖然內存匯總的數據都是Unicode,但當數據保存到磁盤或者用于網絡傳輸時,使用utf-8會節省更多的流量和硬盤空間。
如何判斷幾個字節表示一個字符:
每個字節添加識別位,其中高位識別位為4位,低位識別位為2位。判斷高位字節開頭有幾個1,可以確定共有幾個字節來表示一個字符。
6. utf-8和Unicode對應關系
utf-8去掉識別位,變成unicode。
關于什么是編碼集就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





