溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下python中處理異常值的方法,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討吧!
打開pycharm開發工具,在運行窗口輸入命令:
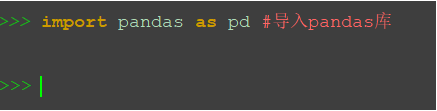
import pandas as pd #導入pandas庫
輸入數據集。
data=pd.DataFrame({'name':['A','B','C','D','E','F','G'],'cost':[2,127,4,6,3,13,14],'sales':[13,18,32,54,23,33,44]})
print(data)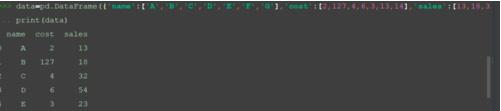
通過z-score方法判斷異常值,即對原始值X進行正態標準化:(X-mean(X))/std(X),根據計算的結果判斷樣本值與中心的偏離程度。
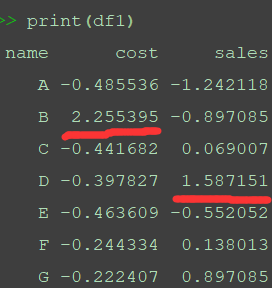
df1=data.copy()#為了不影響原始數據集,復制數據集data print(df1)
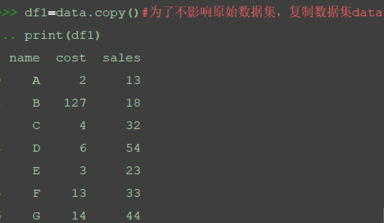
按列計算均值和標準差。
df1['cost']=(df1['cost']-df1['cost'].mean())/df1['cost'].std()#標準化cost_z列
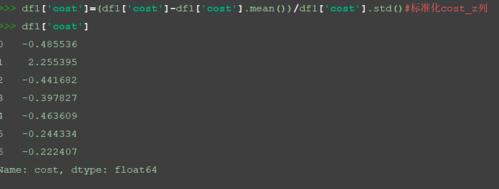
對sales列進行標準化。
df1['sales']=(df1['sales']-df1['sales'].mean())/df1['sales'].std()#標準化cost_z列 df1['sales']
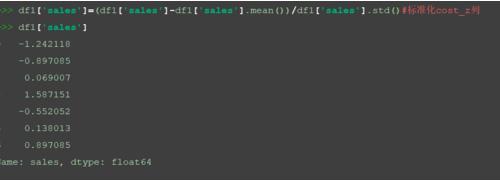
查看標準化后的數據集。
print(df1)
標準化后的絕對值越大,數據越有可能異常,是否異常根據設定的閾值判斷。
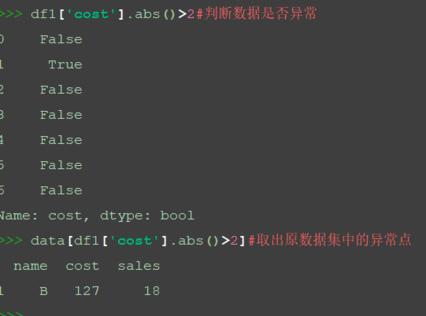
假設cost列閾值為2,通過下面的方法找到異常值。
df1['cost'].abs()>2#判斷數據是否異常 data[df1['cost'].abs()>2]#取出原數據集中的異常點
看完了這篇文章,相信你對python中處理異常值的方法有了一定的了解,想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





