溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
不懂關于Python中垃圾回收機制的案例分析?其實想解決這個問題也不難,下面讓小編帶著大家一起學習怎么去解決,希望大家閱讀完這篇文章后大所收獲。
垃圾回收
1.1 refchain
在Python的C源碼中有一個refchain的環狀雙向鏈表,Python程序當中一旦創建對象都會把這個對象添加到refchain這個鏈表當中,保存著所有的對象。
name = "皮卡丘" width = 5
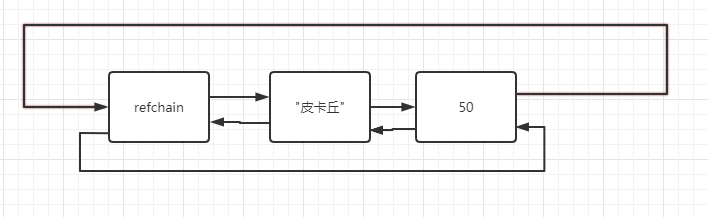
1.2引用計數器
在refchain中所有對象內部都有一個ob_refcnt用來保存當前對象的引用計數器
name = "皮卡丘" width = 5 nickname = name
上述代碼表示內存中有5和”皮卡丘“兩個值,他們的引用計數器分別為1、2
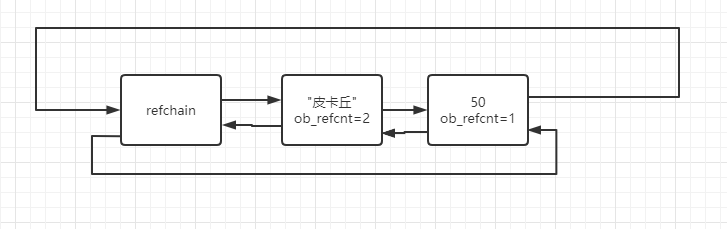
當值被多次引用時候,不會再內存中重復創建數據,而是引用計數器+1。當對象被銷毀時候同時會讓引用計數器-1,如果引用計數器為0,則將對象從refchain鏈表中刪除,同時在內存中進行銷毀(暫時不考慮緩存等特殊情況)。
name = "皮卡丘"nickname = name # 對象”皮卡丘“的引用計數器+1del name 對象"皮卡丘"的引用計數器-1def run(arg): print(arg) run(nickname) # 剛開始執行函數時,對象”皮卡丘“引用計數器+1,當函數執行完畢之后,對象引用計數器-1name_list = ["張三","法外狂徒",name] # 對象”皮卡丘“的引用計數器+1
但是這樣還是存在一個BUG,當出現循環引用的時候,就會無法正常的回收一些數據,例如
v1 = [11,22,33] # refchain中創建一個列表對象,由于v1=對象,所以列表引對象用計數器為1. v2 = [44,55,66] # refchain中再創建一個列表對象,因v2=對象,所以列表對象引用計數器為1. v1.append(v2) # 把v2追加到v1中,則v2對應的[44,55,66]對象的引用計數器加1,最終為2. v2.append(v1) # 把v1追加到v1中,則v1對應的[11,22,33]對象的引用計數器加1,最終為2. del v1 # 引用計數器-1del v2 # 引用計數器-1
對于上面的代碼,執行del操作之后,沒有變量再會去使用那兩個列表對象,但由于循環引用的問題,他們的引用計數器不為0,所以他們的狀態:永遠不會被使用、也不會被銷毀。項目中如果這種代碼太多,就會導致內存一直被消耗,直到內存被耗盡,程序崩潰。
1.3標記清除&分代回收
標記清除:創建特殊鏈表專門用于保存 列表、元組、字典、集合、自定義類等對象,之后再去檢查這個鏈表中的對象是否存在循環引用,如果存在則讓雙方的引用計數器均 - 1 。
分代回收:對標記清楚中的鏈表進行優化,將那些可能存在循環引用的對象拆分到3個鏈表,鏈表成為0/1/2三代,每代都可以存儲對象和閾值,當達到閾值時,就會對相應的鏈表中的每個對象做一次掃描,除循環引用各自減1并且銷毀引用計數器為0的對象。`
// 分代的C源碼#define NUM_GENERATIONS 3struct gc_generation generations[NUM_GENERATIONS] = {
/* PyGC_Head, threshold, count */
{{(uintptr_t)_GEN_HEAD(0), (uintptr_t)_GEN_HEAD(0)}, 700, 0}, // 0代
{{(uintptr_t)_GEN_HEAD(1), (uintptr_t)_GEN_HEAD(1)}, 10, 0}, // 1代
{{(uintptr_t)_GEN_HEAD(2), (uintptr_t)_GEN_HEAD(2)}, 10, 0}, // 2代};0代,count表示0代鏈表中對象的數量,threshold表示0代鏈表對象個數閾值,超過則執行一次0代掃描檢查。
1代,count表示0代鏈表掃描的次數,threshold表示0代鏈表掃描的次數閾值,超過則執行一次1代掃描檢查。
2代,count表示1代鏈表掃描的次數,threshold表示1代鏈表掃描的次數閾值,超過則執行一2代掃描檢查。
1.4緩存機制
實際上他不是這么的簡單粗暴,因為反復的創建和銷毀會使程序的執行效率變低。Python中引入了“緩存機制”機制。
例如:引用計數器為0時,不會真正銷毀對象,而是將他放到一個名為free_list的鏈表中,之后會再創建對象時不會在重新開辟內存,而是在free_list中將之前的對象來并重置內部的值來使用。
float類型,維護的free_list鏈表最多可緩存100個float對象。
1. `v1 = 3.14 # 開辟內存來存儲float對象,并將對象添加到refchain鏈表。` 2. `print( id(v1) ) # 內存地址:4436033488` 3. `del v1 # 引用計數器-1,如果為0則在rechain鏈表中移除,不銷毀對象,而是將對象添加到float的free_list.` 4. `v2 = 9.999 # 優先去free_list中獲取對象,并重置為9.999,如果free_list為空才重新開辟內存。` 5. `print( id(v2) ) # 內存地址:4436033488` 7. `# 注意:引用計數器為0時,會先判斷free_list中緩存個數是否滿了,未滿則將對象緩存,已滿則直接將對象銷毀。`
int類型,不是基于free_list,而是維護一個small_ints鏈表保存常見數據(小數據池),小數據池范圍:-5 <= value < 257。即:重復使用這個范圍的整數時,不會重新開辟內存。
v1 = 38 # 去小數據池small_ints中獲取38整數對象,將對象添加到refchain并讓引用計數器+1。 print( id(v1)) #內存地址:4514343712 v2 = 38 # 去小數據池small_ints中獲取38整數對象,將refchain中的對象的引用計數器+1。 print( id(v2) ) #內存地址:4514343712 # 注意:在解釋器啟動時候-5~256就已經被加入到small_ints鏈表中且引用計數器初始化為1,代碼中使用的值時直接去small_ints中拿來用并將引用計數器+1即可。另外,small_ints中的數據引用計數器永遠不會為0(初始化時就設置為1了),所以也不會被銷毀。
str類型,維護unicode_latin1[256]鏈表,內部將所有的ascii字符緩存起來,以后使用時就不再反復創建。
v1 = "A" print( id(v1) ) # 輸出:4517720496 del v1 v2 = "A" print( id(v1) ) # 輸出:4517720496 # 除此之外,Python內部還對字符串做了駐留機制,針對那么只含有字母、數字、下劃線的字符串(見源碼Objects/codeobject.c),如果內存中已存在則不會重新在創建而是使用原來的地址里(不會像free_list那樣一直在內存存活,只有內存中有才能被重復利用)。 v1 = "wupeiqi" v2 = "wupeiqi" print(id(v1) == id(v2)) # 輸出:True
list類型,維護的free_list數組最多可緩存80個list對象。
v1 = [11,22,33] print( id(v1) ) # 輸出:4517628816 del v1 v2 = ["小豬","佩奇"] print( id(v2) ) # 輸出:4517628816
tuple類型,維護一個free_list數組且數組容量20,數組中元素可以是鏈表且每個鏈表最多可以容納2000個元組對象。元組的free_list數組在存儲數據時,是按照元組可以容納的個數為索引找到free_list數組中對應的鏈表,并添加到鏈表中。
v1 = (1,2)
print( id(v1) ) del v1 # 因元組的數量為2,所以會把這個對象緩存到free_list[2]的鏈表中。
v2 = ("小豬","佩奇") # 不會重新開辟內存,而是去free_list[2]對應的鏈表中拿到一個對象來使用。
print( id(v2) )dict類型,維護的free_list數組最多可緩存80個dict對象。
v1 = {"k1":123}
print( id(v1) ) # 輸出:4515998128
del v1
v2 = {"name":"武沛齊","age":18,"gender":"男"}
print( id(v1) ) # 輸出:45159981282 C語言源碼分析
2.1兩個重要的結構體
#define PyObject_HEAD PyObject ob_base;#define PyObject_VAR_HEAD PyVarObject ob_base;// 宏定義,包含 上一個、下一個,用于構造雙向鏈表用。(放到refchain鏈表中時,要用到)#define _PyObject_HEAD_EXTRA \
struct _object *_ob_next; \
struct _object *_ob_prev;typedef struct _object {
_PyObject_HEAD_EXTRA // 用于構造雙向鏈表
Py_ssize_t ob_refcnt; // 引用計數器
struct _typeobject *ob_type; // 數據類型} PyObject;typedef struct {
PyObject ob_base; // PyObject對象
Py_ssize_t ob_size; /* Number of items in variable part,即:元素個數 */} PyVarObject;這兩個結構體PyObject和PyVarObject是基石,他們保存這其他數據類型公共部分,例如:每個類型的對象在創建時都有PyObject中的那4部分數據;list/set/tuple等由多個元素組成對象創建時都有PyVarObject中的那5部分數據。
2.2常見類型結構體
平時我們在創建一個對象時,本質上就是實例化一個相關類型的結構體,在內部保存值和引用計數器等。
float類型
typedef struct {
PyObject_HEAD double ob_fval;
} PyFloatObject;int類型
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
}; /* Long (arbitrary precision) integer object interface */
typedef struct _longobject PyLongObject; /* Revealed in longintrepr.h */str類型
typedef struct {
PyObject_HEAD
Py_ssize_t length; /* Number of code points in the string */
Py_hash_t hash; /* Hash value; -1 if not set */
struct {
unsigned int interned:2; /* Character size:
- PyUnicode_WCHAR_KIND (0):
* character type = wchar_t (16 or 32 bits, depending on the
platform)
- PyUnicode_1BYTE_KIND (1):
* character type = Py_UCS1 (8 bits, unsigned)
* all characters are in the range U+0000-U+00FF (latin1)
* if ascii is set, all characters are in the range U+0000-U+007F
(ASCII), otherwise at least one character is in the range
U+0080-U+00FF
- PyUnicode_2BYTE_KIND (2):
* character type = Py_UCS2 (16 bits, unsigned)
* all characters are in the range U+0000-U+FFFF (BMP)
* at least one character is in the range U+0100-U+FFFF
- PyUnicode_4BYTE_KIND (4):
* character type = Py_UCS4 (32 bits, unsigned)
* all characters are in the range U+0000-U+10FFFF
* at least one character is in the range U+10000-U+10FFFF
*/
unsigned int kind:3; unsigned int compact:1; unsigned int ascii:1; unsigned int ready:1; unsigned int :24;
} state; wchar_t *wstr; /* wchar_t representation (null-terminated) */
} PyASCIIObject; typedef struct {
PyASCIIObject _base;
Py_ssize_t utf8_length; /* Number of bytes in utf8, excluding the
* terminating \0. */
char *utf8; /* UTF-8 representation (null-terminated) */
Py_ssize_t wstr_length; /* Number of code points in wstr, possible
* surrogates count as two code points. */
} PyCompactUnicodeObject; typedef struct {
PyCompactUnicodeObject _base; union { void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data; /* Canonical, smallest-form Unicode buffer */
} PyUnicodeObject;list類型
typedef struct {
PyObject_VAR_HEAD
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject;tuple類型
typedef struct {
PyObject_VAR_HEAD
PyObject *ob_item[1];
} PyTupleObject;dict類型
typedef struct {
PyObject_HEAD
Py_ssize_t ma_used;
PyDictKeysObject *ma_keys;
PyObject **ma_values;
} PyDictObject;通過常見結構體可以基本了解到本質上每個對象內部會存儲的數據。
擴展:在結構體部分你應該發現了str類型比較繁瑣,那是因為python字符串在處理時需要考慮到編碼的問題,在內部規定(見源碼結構體):
字符串只包含ascii,則每個字符用1個字節表示,即:latin1字符串包含中文等,則每個字符用2個字節表示,即:ucs2字符串包含emoji等,則每個字符用4個字節表示,即:ucs4
感謝你能夠認真閱讀完這篇文章,希望小編分享關于Python中垃圾回收機制的案例分析內容對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,遇到問題就找億速云,詳細的解決方法等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





