溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Java開發中容器概念、分類與用法的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
1、容器的概念
在Java當中,如果有一個類專門用來存放其它類的對象,這個類就叫做容器,或者就叫做集合,集合就是將若干性質相同或相近的類對象組合在一起而形成的一個整體
2、容器與數組的關系
之所以需要容器:
① 數組的長度難以擴充
② 數組中數據的類型必須相同
容器與數組的區別與聯系:
① 容器不是數組,不能通過下標的方式訪問容器中的元素
② 數組的所有功能通過Arraylist容器都可以實現,只是實現的方式不同
③ 如果非要將容器當做一個數組來使用,通過toArraylist方法返回的就是一個數組
示例程序:
package IT;
import java.util.ArrayList;
import java.util.Iterator;
//數組的所有功能通過ArrayList容器都可以實現,只是實現的方式不同
public class App
{
public static void main(String[] args)
{
ArrayList<Integer> arrayList = new ArrayList<Integer>();
arrayList.add(12);
arrayList.add(10);
arrayList.add(35);
arrayList.add(100);
Iterator<Integer> iterator = arrayList.iterator();//獲取容器的迭代器
while(iterator.hasNext())
{
Integer value = iterator.next();//獲取當前游標右邊的元素,同時游標右移-->
System.out.println(value);
}
System.out.println("通過ArrayList容器獲取一個數組arr:");
Object[] arr = arrayList.toArray();
for(int i=0;i<arr.length;i++)
{
System.out.println(arr[i]);
}
}
}輸出結果:
12 10 35 100
通過ArrayList容器獲取一個數組arr:
12 10 35 100
3、容器常用的幾個方法
boolean add(Object obj):向容器中添加指定的元素
Iterator iterator():返回能夠遍歷當前集合中所有元素的迭代器
Object[] toArray():返回包含此容器中所有元素的數組。
Object get(int index):獲取下標為index的那個元素
Object remove(int index):刪除下標為index的那個元素
Object set(int index,Object element):將下標為index的那個元素置為element
Object add(int index,Object element):在下標為index的位置添加一個對象element
Object put(Object key,Object value):向容器中添加指定的元素
Object get(Object key):獲取關鍵字為key的那個對象
int size():返回容器中的元素數
實例程序:
package IT;
import java.util.ArrayList;
public class App
{
public static void main(String[] args)
{
ArrayList<Integer> arrayList = new ArrayList<Integer>();
arrayList.add(12);
arrayList.add(10);
arrayList.add(35);
arrayList.add(100);
System.out.println("原容器中的元素為:");
System.out.println(arrayList);
System.out.println("\n");
/*******重置set(int index,Object element)*******/
System.out.println("將下標為1位置的元素置為20,將下標為2位置的元素置為70");
arrayList.set(1, 20);
arrayList.set(2, 70);
System.out.println("重置之后容器中的元素為:");
System.out.println(arrayList);
System.out.println("\n");
/*******中間插隊add(int index,Object element)*******/
System.out.println("在下標為1的位置插入一個元素,-----插入元素:此時容器后面的元素整體向后移動");
arrayList.add(1, 80);//在下標為1的位置插入一個元素,此時容量加1,-----位置后面的元素整體向后移動
System.out.println("插入之后容器中的元素為:");
System.out.println(arrayList);
System.out.println("插入之后容器中的容量為:");
System.out.println(arrayList.size());
System.out.println("\n");
/*******中間刪除元素remove(int index)*******/
System.out.println("將下標為3位置的元素70刪除,-----刪除元素:此時容器位置后面的元素整體向前移");
arrayList.remove(3);
System.out.println("刪除之后容器中的元素為:");
System.out.println(arrayList);
System.out.println("刪除之后容器中的容量為:");
System.out.println(arrayList.size());
}
}運行結果:
原容器中的元素為: [12, 10, 35, 100] 將下標為1位置的元素置為20,將下標為2位置的元素置為70 重置之后容器中的元素為: [12, 20, 70, 100] 在下標為1的位置插入一個元素,-----插入元素:此時容器后面的元素整體向后移動 插入之后容器中的元素為: [12, 80, 20, 70, 100] 插入之后容器中的容量為: 5 將下標為3位置的元素70刪除,-----刪除元素:此時容器位置后面的元素整體向前移 刪除之后容器中的元素為: [12, 80, 20, 100] 刪除之后容器中的容量為: 4
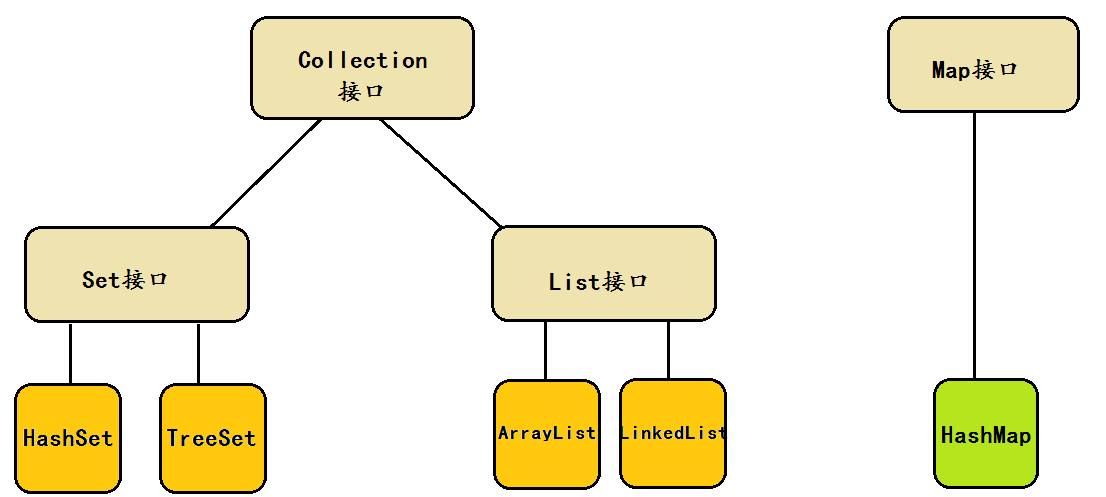
4、容器的分類
容器分為Set集、List列表、Map映射
Set集合:由于內部存儲結構的特點,Set集合中不區分元素的順序,不允許出現重復的元素,TreeSet容器特殊,元素放進去的時候自然而然就有順序了,Set容器可以與數學中的集合相對應:相同的元素不會被加入
List列表:由于內部存儲結構的特點,List集合中區分元素的順序,且允許包含重復的元素。List集合中的元素都對應一個整數型的序號記載其在容器中的位置,可以根據序號存取容器中的元素—有序,可以重復
Map映射:由于內部存儲結構的特點,映射中不能包含重復的鍵值,每個鍵最多只能映射一個值,否則會出現覆蓋的情況(后面的value值會將前面的value值覆蓋掉),Map是一種把鍵對象和值對象進行映射的集合,即Map容器中既要存放數據本身,也要存放關鍵字:相同的元素會被覆蓋
注意:對于Set和Map來說,元素放進去之后是沒有順序的,如果希望元素放進去之后是有順序的,可以用treeSet和treeMap存儲數據。
實例程序:
var set2 = mutable.Set.empty[Int]
set2 += 10
set2 ++= List(50,100,200)
set2 += 500
println("Set輸出的結果:")
println(set2)
var map3 = mutable.Map.empty[String,Double]
map3 += "Spark"->90.0
map3 += "Hadoop"->80.0
map3 ++= List("Scala"->100.0,"Java"->60.0)
println("Map輸出的結果:")
println(map3)運行結果:
Set輸出的結果: Set(100, 50, 500, 10, 200) Map輸出的結果: Map(Hadoop -> 80.0, Spark -> 90.0, Scala -> 100.0, Java -> 60.0)
實例程序:
var treeSet = TreeSet(10,20,30,90,100,200,50)
println(treeSet)
/*鍵值對排序是根據key的值進行排序的,沒有value的事情,讓我聯想到了MapReduce中排序的時候之所以根據k2
而不是v2的值進行排序,這是因為哈希映射內部決定的,而不是MapReduce決定的
呵呵!注意:排序區分大小寫的哦!!!*/
var treeSet2 = TreeSet[String]("Spark","Anang","Baby","Hello")
println(treeSet2)
var treeMap = TreeMap[String,Integer]("Java"->100,"Scala"->88,"Python"->60,"Anglebaby"->500)
println(treeMap)運行結果:
TreeSet(10, 20, 30, 50, 90, 100, 200) TreeSet(Anang, Baby, Hello, Spark) Map(Anglebaby -> 500, Java -> 100, Python -> 60, Scala -> 88)
5、toString()方法的使用:凡是把類對象放到容器中,相應的類都應該實現Object類中的toString()方法;凡是Java中自帶的數據類型,都已經重寫完了toString()方法
實例1:(未重寫toString()方法之前)
package IT;
public class App
{
public static void main(String[] args)
{
//Java中自帶的類
System.out.println("-----凡是Java中自帶的數據類型都已經重寫完了toString()方法!---");
System.out.println(new Integer(2).toString());
System.out.println(new String("zhang").toString());
//用戶自定義的類Student
System.out.println(new Student("zhangsan",99.8).toString());
}
}
class Student
{
public String name;
public double score;
public Student(String name,double score)
{
this.name = name;
this.score = score;
}
}輸出結果:
-----凡是Java中自帶的數據類型都已經重寫完了toString()方法!--- 2 zhang IT.Student@1af2f973
實例2:(重寫完toString()方法之后)
package IT;
import java.util.ArrayList;
public class App
{
public static void main(String[] args)
{
ArrayList<Student> arr = new ArrayList<Student>();
arr.add(new Student("zhangsan",89.8));
arr.add(new Student("lisi",90));
arr.add(new Student("wangwu",60.6));
System.out.println(arr);
}
}
class Student
{
public String name;
public double score;
public Student(String name,double score)
{
this.name = name;
this.score = score;
}
public String toString()
{
return this.name+"\t"+this.score;
}
}輸出結果:
[zhangsan 89.8, lisi 90.0, wangwu 60.6]
6、Comparable接口中的compareTo()方法:凡是需要進行比較排序的類都應該實現Comparable接口中的compareTo()方法;凡是把類對象放到以樹為內部結構的容器中都應該實現Comparable接口中的compareTo()方法
實例1:
package IT;
import java.util.ArrayList;
import java.util.Collections;
public class App
{
public static void main(String[] args)
{
ArrayList<Student> arr = new ArrayList<Student>();
arr.add(new Student("zhangsan",89.8));
arr.add(new Student("lisi",90));
arr.add(new Student("wangwu",60.6));
arr.add(new Student("wangting",85.6));
Collections.sort(arr);
for (Student student : arr)
{
System.out.println(student);
}
}
}
class Student implements Comparable<Student>
{
public String name;
public double score;
public Student(String name,double score)
{
this.name = name;
this.score = score;
}
public String toString()
{
return this.name+"\t"+this.score;
}
public int compareTo(Student obj)
{
return (int) (this.score - obj.score);//比較的標準為score進行升序
}
}輸出結果:
wangwu 60.6 wangting 85.6 zhangsan 89.8 lisi 90.0
實例2:
package IT;
import java.util.TreeSet;
public class App
{
public static void main(String[] args)
{
TreeSet<Student> treeSet = new TreeSet<Student>();
treeSet.add(new Student("wangwu",60.6));
treeSet.add(new Student("lisi",90.0));
treeSet.add(new Student("wangting",85.6));
treeSet.add(new Student("zhangsan",60.6));
for (Student student : treeSet)
{
System.out.println(student);
}
}
}
class Student implements Comparable<Student>
{
public String name;
public double score;
public Student(String name,double score)
{
this.name = name;
this.score = score;
}
public String toString()
{
return this.name+"\t"+this.score;
}
public int compareTo(Student obj)
{
if(this.score > obj.score)
return 1;
else
return -1;
}
}輸出結果:
zhangsan 60.6 wangwu 60.6 wangting 85.6 lisi 90.0
7、凡是把類對象放到以哈希表為內部存儲結構的容器中,相應的類必須要實現equals方法和hashCode方法,這樣才符合哈希表真實的邏輯功能.
實例程序1:(為重寫之前)
package IT;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
public class App
{
public static void main(String[] args)
{
//Java中自帶的數據類型
System.out.println("先測試Java中自帶的數據類型:");
HashMap<String, Double> hashMap1 = new HashMap<String,Double>();
hashMap1.put("zhangsan", 96.0);
hashMap1.put("lisi", 88.6);
hashMap1.put("wangwu", 98.6);
hashMap1.put("wangting", 87.5);
hashMap1.put("zhangsan", 96.0);
hashMap1.put("lisi", 88.6);
hashMap1.put("wangwu", 98.6);
hashMap1.put("wangting", 87.5);
Set<String> keySet = hashMap1.keySet();
Iterator<String> iterator = keySet.iterator();
while(iterator.hasNext())
{
String key = iterator.next();
System.out.println(key+"\t"+hashMap1.get(key));
}
System.out.println("Java中自帶的數據類型:相同的對象會覆蓋!");
System.out.println("\n");
//用戶自定義的數據類型:為重寫之前
System.out.println("測試用戶自定義的數據類型--未重寫兩個方法之前:");
HashMap<Student, String> hashMap2 = new HashMap<Student,String>();
hashMap2.put(new Student("zhangsan",88.8), "beijing");
hashMap2.put(new Student("lisi",88.8), "beijing");
hashMap2.put(new Student("wangwu",66.9), "beijing");
hashMap2.put(new Student("zhangsan",88.8), "beijing");
hashMap2.put(new Student("lisi",88.8), "beijing");
hashMap2.put(new Student("wangwu",66.9), "beijing");
Set<Student> keySet2 = hashMap2.keySet();
Iterator<Student> iterator2 = keySet2.iterator();
while(iterator2.hasNext())
{
Student key = iterator2.next();
System.out.println(key+"\t"+hashMap2.get(key));
}
System.out.println("如果沒有重寫:導致相同的對象不會被覆蓋!");
}
}
class Student implements Comparable<Student>
{
public String name;
public double score;
public Student(String name,double score)
{
this.name = name;
this.score = score;
}
public String toString()
{
return this.name+"\t"+this.score;
}
public int compareTo(Student obj)
{
if(this.score > obj.score)
return 1;
else
return -1;
}
}輸出結果:
先測試Java中自帶的數據類型: wangting 87.5 wangwu 98.6 lisi 88.6 zhangsan 96.0 Java中自帶的數據類型:相同的對象會覆蓋! 測試用戶自定義的數據類型--為重寫兩個方法之前: zhangsan 88.8 beijing wangwu 66.9 beijing lisi 88.8 beijing wangwu 66.9 beijing zhangsan 88.8 beijing lisi 88.8 beijing 如果沒有重寫:導致相同的對象不會被覆蓋!
實例程序2:重寫之后
package IT;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
public class App
{
public static void main(String[] args)
{
//用戶自定義的數據類型:為重寫之后
System.out.println("測試用戶自定義的數據類型--重寫兩個方法之后:");
HashMap<Student, String> hashMap2 = new HashMap<Student,String>();
hashMap2.put(new Student("zhangsan",88.8), "beijing");
hashMap2.put(new Student("lisi",88.8), "beijing");
hashMap2.put(new Student("wangwu",66.9), "beijing");
hashMap2.put(new Student("zhangsan",88.8), "beijing");
hashMap2.put(new Student("lisi",88.8), "beijing");
hashMap2.put(new Student("wangwu",66.9), "beijing");
Set<Student> keySet2 = hashMap2.keySet();
Iterator<Student> iterator2 = keySet2.iterator();
while(iterator2.hasNext())
{
Student key = iterator2.next();
System.out.println(key+"\t"+hashMap2.get(key));
}
System.out.println("重寫過后:相同的對象會被覆蓋!");
}
}
class Student implements Comparable<Student>
{
public String name;
public double score;
public Student(String name,double score)
{
this.name = name;
this.score = score;
}
public String toString()
{
return this.name+"\t"+this.score;
}
public int compareTo(Student obj)
{
if(this.score > obj.score)
return 1;
else
return -1;
}
@Override
public int hashCode()
{
return (int) (this.name.hashCode()*score);//保證相同對象映射到同一個索引位置
}
@Override
public boolean equals(Object obj)
{
Student cc = (Student)obj;
return this.name==cc.name&&this.score==cc.score;
}
}輸出結果:
測試用戶自定義的數據類型--重寫兩個方法之后: wangwu 66.9 beijing zhangsan 88.8 beijing lisi 88.8 beijing 重寫過后:相同的對象會被覆蓋!
8、重要的一個邏輯:邏輯上來講,只要兩個對象的內容相同,其地址(hashCode()返回值)以及這兩個對象就應該相同(equals()),
實例程序(為重寫之前):
package IT;
public class App
{
public static void main(String[] args)
{
//Java中自帶的數據類型
System.out.println(new Integer(1).equals(new Integer(1)));
System.out.println(new Integer(1).hashCode()==new Integer(1).hashCode());
System.out.println(new String("zhang").equals(new String("zhang")));
System.out.println(new String("zhang").hashCode()==new String("zhang").hashCode());
System.out.println("\n");
//用戶自定義的數據類型
System.out.println(new Student("zhangsan",98.8).equals(new Student("zhangsan",98.8)));
System.out.println(new Student("zhangsan",98.8).hashCode());
System.out.println(new Student("zhangsan",98.8).hashCode());
}
}
class Student implements Comparable<Student>
{
public String name;
public double score;
public Student(String name,double score)
{
this.name = name;
this.score = score;
}
public String toString()
{
return this.name+"\t"+this.score;
}
public int compareTo(Student obj)
{
if(this.score > obj.score)
return 1;
else
return -1;
}
}輸出結果:
true true true true false 488676694 1211729930
重寫之后:
package IT;
public class App
{
public static void main(String[] args)
{
System.out.println(new Student("zhangsan",98.8).equals(new Student("zhangsan",98.8)));
System.out.println(new Student("zhangsan",98.8).hashCode());
System.out.println(new Student("zhangsan",98.8).hashCode());
}
}
class Student implements Comparable<Student>
{
public String name;
public double score;
public Student(String name,double score)
{
this.name = name;
this.score = score;
}
public String toString()
{
return this.name+"\t"+this.score;
}
public int compareTo(Student obj)
{
if(this.score > obj.score)
return 1;
else
return -1;
}
@Override
public int hashCode()
{
return (int) (this.name.hashCode()*score);
}
@Override
public boolean equals(Object obj)
{
Student cc = (Student)obj;
return this.name==cc.name&&this.score==cc.score;
}
}輸出結果:
true -2147483648 -2147483648
上面的5、6、7、8可以歸結為4個”凡是”,1個“邏輯”:
1、凡是把類對象放到容器中,相應的類都應該實現Object類中的toString()方法;
2、凡是需要進行比較排序的類都應該實現Comparable接口中的compareTo()方法;凡是把類對象放到以樹為內部結構的容器中都應該實現Comparable接口中的compareTo()方法
3、凡是把類對象放到以哈希表為內部存儲結構的容器中,相應的類必須要實現equals方法和hashCode方法,這樣才符合哈希表真實的邏輯功能.
4、邏輯上來講,只要兩個對象的內容相同,其地址(hashCode()返回值)以及這兩個對象就應該相同(equals())。
9、哈希沖突的相關概念
本質上講就是:hash(對象1.hashCode())=hash3(對象2.hashCode()),即第一個對象的hashCode()方法返回的哈希碼值帶入到哈希函數后得到的索引位置與第二個對象的hashCode()方法返回的哈希碼值帶入到哈希函數后得到的索引位置相同,這就是哈希沖突。
最常見的哈希算法是取模法。
下面簡單講講取模法的計算過程。
比如:數組的長度是5。這時有一個數據是6。那么如何把這個6存放到長度只有5的數組中呢。按照取模法,計算6%5,結果是1,那么就把6放到數組下標是1的位置。那么,7
就應該放到2這個位置。到此位置,哈斯沖突還沒有出現。這時,有個數據是11,按照取模法,11%5=1,也等于1。那么原來數組下標是1的地方已經有數了,是6。這時又計算出1這個位置,那么數組1這個位置,就必須儲存兩個數了。這時,就叫哈希沖突。沖突之后就要按照順序來存放了。
如果數據的分布比較廣泛,而且儲存數據的數組長度比較大。
那么哈希沖突就比較少。否則沖突是很高的。
10、iterator接口的作用
重要方法:
boolean hasNext():是用來判斷當前游標(迭代器)的后面是否存在元素,如果存在返回真,否則返回假
Object next():先返回當前游標右邊的元素,然后游標后移一個位置
void remove():不推薦使用iterator的remove()方法,而是推薦使用容器自帶的remove方法。
實例程序:
package IT;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
public class App
{
public static void main(String[] args)
{
HashMap<String, Double> hashMap = new HashMap<String,Double>();
hashMap.put("zhangsan", 88.6);
hashMap.put("lisi", 69.0);
hashMap.put("wanqwu", 100.0);
hashMap.put("lisi", 69.0);
Set<String> keySet = hashMap.keySet();
Iterator<String> iterator = keySet.iterator();
while(iterator.hasNext())
{
String key = iterator.next();//獲取迭代器右邊的元素,同時右移
System.out.println(key+hashMap.get(key));
}
}
}思考題:
package IT;
import java.util.TreeSet;
public class App
{
public static void main(String[] args)
{
TreeSet<Student> treeSet = new TreeSet<Student>();
treeSet.add(new Student("zhangsan",98));
treeSet.add(new Student("zhangsan",98));
System.out.println(treeSet.size());
System.out.println(treeSet);
//本程序中并沒有重寫equals方法,但是treeSet將識別出兩個new Student("zhangsan",98)為相同的,因為內部數據結構嗎?
System.out.println(new Student("zhangsan",98).equals(new Student("zhangsan",98)));
}
}
class Student implements Comparable<Object>
{
public String name;
public double score;
public Student(String name,double score)
{
this.name = name;
this.score = score;
}
public String toString()
{
return name + "\t" + score;
}
@Override
public int compareTo(Object obj)
{
Student cc = (Student)obj;
return (int) (this.score - cc.score);
}
}關于“Java開發中容器概念、分類與用法的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





