溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“JAVA中線上常見問題排查手段有哪些”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“JAVA中線上常見問題排查手段有哪些”這篇文章吧。
一、系統性能瓶頸在哪
我們常常提到項目的運行環境,那么運行環境包括哪些呢?一般包括你的操作系統、CPU、內存、硬盤、網絡帶寬、JRE環境、你的代碼依賴的各種組件等等。所以系統性能的瓶頸往往是IO瓶頸、CPU瓶頸、內存瓶頸或者程序導致的性能瓶頸
登錄到服務器上,我們使用TOP命令可以很全面的看到系統資源使用情況
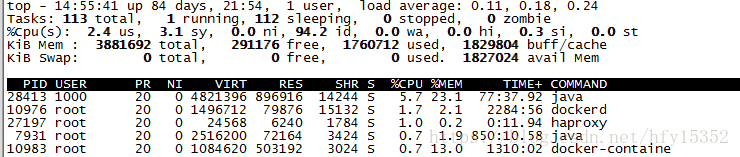
CPU瓶頸如何分析
使用TOP命令,輸入大寫P(即shift + P)可以按照CPU使用大小降序排序,在TOP命令第三行可以看到關鍵信息 %id:空閑CPU時間百分比,如果這個值過低,表明系統CPU存在瓶頸。如果過低,一般都是你的java程序導致的,所以需要登錄到docker容器通過jstack命令查看堆棧信息來分析原因
確認目標進程
查看對應進程信息 -> 登錄容器查看容器id -> 進入容器 -> 容器內top命令查看CPU過高的目標進程
#top #ps -ef | grep 進程號 #sudo docker ps -a #sudo docker exec -it 容器id bash #top
對于CPU使用情況詳細信息可以使用sar命令;命令中1 3 表示每秒采樣1次,一共采樣3次
#sar -u 1 3
打印堆棧信息
由于進程是admin用戶啟動的,所以jstack打印堆棧信息需要切換admin用戶,確保你的機器上裝了jstack命令;
然后退出容器,將文件復制移動到個人家目錄(如果cp命令不能使用,可以通過scp命令移動到個人家目錄)
通過sftp命令將文件copy到本地機器上,來分析堆棧日志信息;如果裝了sz命令,或者通過sz命令下載也可以
# sudo -u admin /opt/usr/java/bin/jstack -l 76 > /home/admin/test/logs/jstack.log # cp /home/admin/test/logs/jstack.log ~/
分析堆棧信息
進入容器,查看哪些線程占比高(截圖只是為了說明如何使用,實際cpu并沒有很高)
#top -H p 進程id
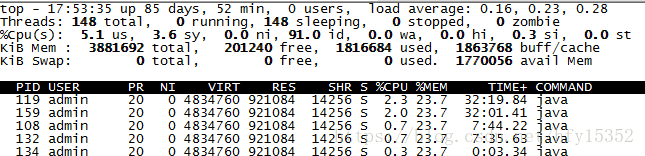
將占比高的線程PID換算成16進制,去堆棧日志找對應的線程堆棧信息,分析問題就可以了
內存瓶頸如何分析
項目開發過程中,線程的不合理使用或者集合的不合理使用,通常會導致內存oom情況,對于內存瓶頸一般通過top命令查看,或者free命令查看內存使用情況;更詳細可以通過vmstat命令查看
free命令,實際可用內存為free + buff + available;
#free -m
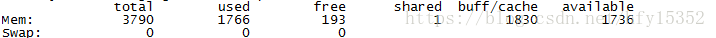
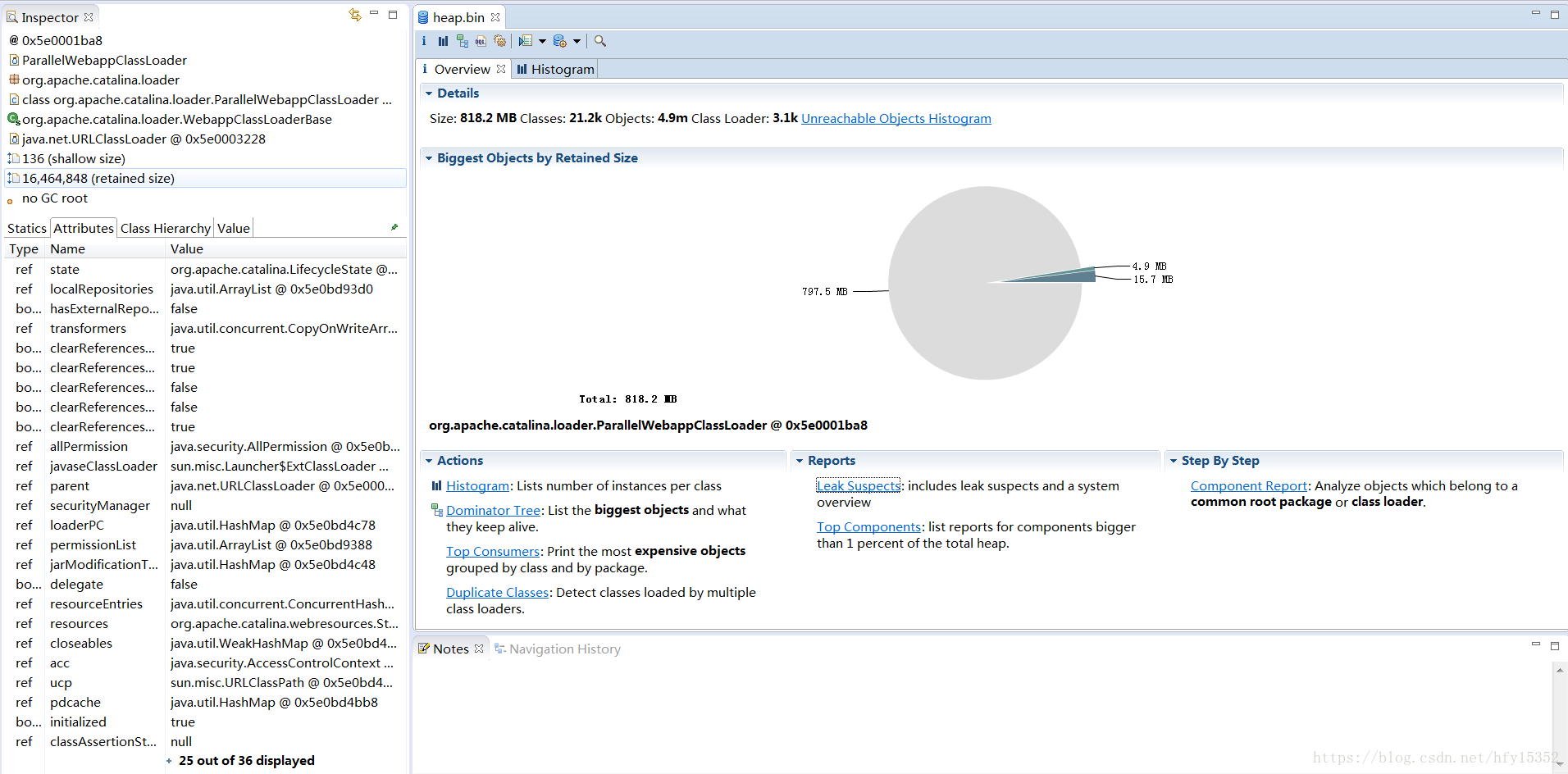
如何分析內存使用,找到內存過高的原因呢,需要登錄到docker容器中查看內存占比比較高的進程,通過jmap命令dump下來,通過IBM的分析工具MA來分析
確定目標進程 -> jmap -> 通過scp命令copy到個人家目錄 -> 由于dump文件比較大,所以下載到本地之前通過tar命令壓縮一下
#sudo -u admin /opt/usr/java/bin/jmap -dump:live,format=b,file=/home/admin/test/logs/java.heap.bin 進程號 #scp 用戶名@host:/home/admin/test/logs/java.heap.bin ~/ #cd ~ #tar -zcvf java.heap.bin.tar.gz java.heap.bin
一般內存分析查看最多的就是Actions下面的Histogram,查看對象引用有多少沒有GC;一般正常一個dump文件看起來不明顯,需要多個dump文件對比來查看內存泄露的原因
IO瓶頸如何分析
如果IO存在性能瓶頸,top工具中的%wa會偏高,進一步分析用iostat命令工具分析
#iostat -d -k -x 1 1
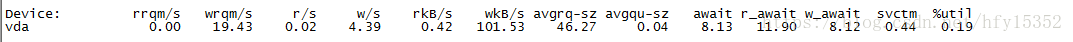
如果%iowait的值過高,表示硬盤存在I/O瓶頸。
如果 %util 接近 100%,說明產生的I/O請求太多,I/O系統已經滿負荷,該磁盤可能存在瓶頸。
如果 svctm 比較接近 await,說明 I/O 幾乎沒有等待時間;
如果 await 遠大于 svctm,說明I/O 隊列太長,io響應太慢,則需要進行必要優化。
如果avgqu-sz比較大,也表示有大量io在等待
解決這種問題一般方法有:使用緩存,講述磁盤IO;同步轉化成異步、隨機寫轉化成順序寫、替換硬件
調用第三方接口網絡報文分析
項目中有時候會遇到第三方接口的服務調用,一般通過HTTP客戶端請求,對于常見的服務連接超時、系統抖動等問題經常遇到;這種問題有時候排查起來比較麻煩,只有通過tcpdump來抓取網絡層的報文,在通過wireshark工具來分析原因;對于HTTS協議的,只能依賴第三方服務端抓包來分析
#tcpdump -i eth0 dst host hostname -C 10240 -W 50 -w xx.cap
一般需要root用戶權限,hostname替換成實際主機ip或域名,eth0是網卡,一般服務器會有多個網卡,所以一定要指定抓取哪個網卡上對應的網絡數據報文
我們來回顧一下在傳輸層TCP三次握手和四次揮手的過程
客戶端和服務端進行數據傳輸一般都是HTTP或者HTTPS協議,HTTP超文本傳輸協議是建議在TCP傳輸協議上進行傳輸數據的,底層TCP傳輸通過套接字Socket進行數據流傳輸;至于為什么是三次握手,可以理解為信道不可靠,傳輸要可靠,三次握手是理論上的最小值
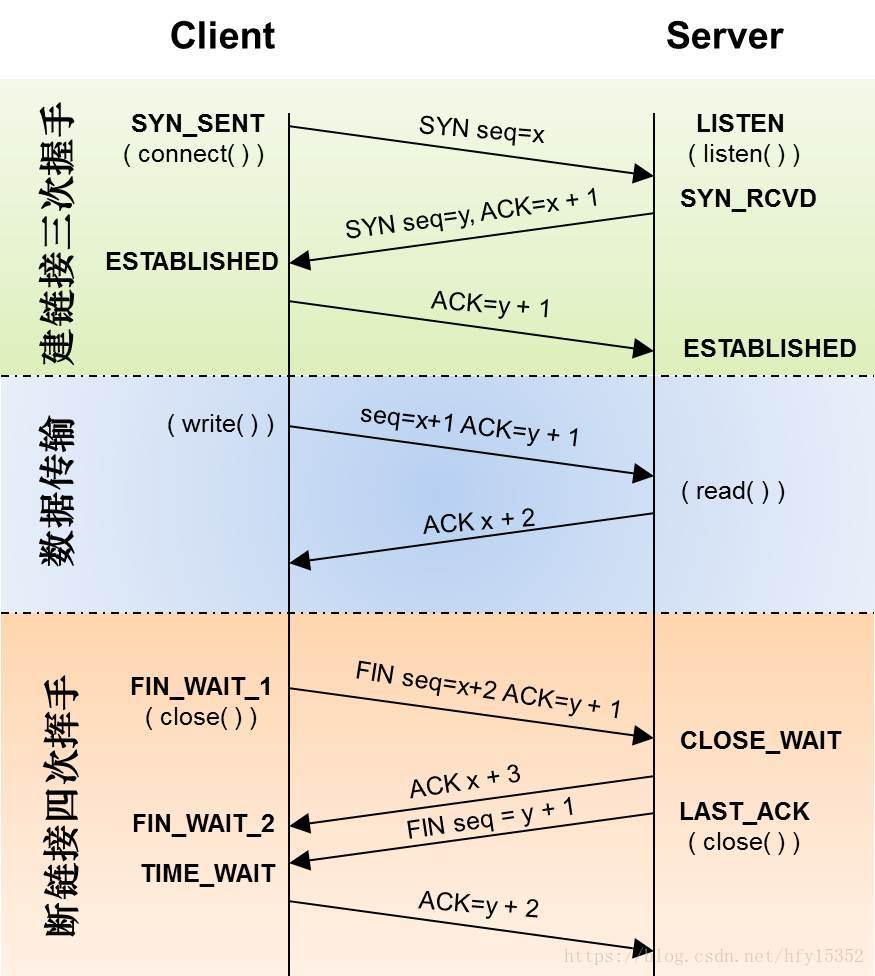
第一次握手:建立連接。客戶端發送連接請求報文段,將SYN位置為1,Sequence Number為x;然后,客戶端進入SYN_SEND狀態,等待服務器的確認;
第二次握手:服務器收到SYN報文段。服務器收到客戶端的SYN報文段,需要對這個SYN報文段進行確認,設置Acknowledgment Number為x+1(Sequence Number+1);同時,自己自己還要發送SYN請求信息,將SYN位置為1,Sequence Number為y;服務器端將上述所有信息放到一個報文段(即SYN+ACK報文段)中,一并發送給客戶端,此時服務器進入SYN_RECV狀態;
第三次握手:客戶端收到服務器的SYN+ACK報文段。然后將Acknowledgment Number設置為y+1,向服務器發送ACK報文段,這個報文段發送完畢以后,客戶端和服務器端都進入ESTABLISHED狀態,完成TCP三次握手。
完成了三次握手,客戶端和服務器端就可以開始傳送數據。以上就是TCP三次握手的總體介紹
那四次分手呢?
當客戶端和服務器通過三次握手建立了TCP連接以后,當數據傳送完畢,肯定是要斷開TCP連接的啊。那對于TCP的斷開連接,這里就有了神秘的“四次分手”。
第一次分手:主機1(可以使客戶端,也可以是服務器端),設置Sequence Number和Acknowledgment Number,向主機2發送一個FIN報文段;此時,主機1進入FIN_WAIT_1狀態;這表示主機1沒有數據要發送給主機2了;
第二次分手:主機2收到了主機1發送的FIN報文段,向主機1回一個ACK報文段,Acknowledgment Number為Sequence Number加1;主機1進入FIN_WAIT_2狀態;主機2告訴主機1,我“同意”你的關閉請求;
第三次分手:主機2向主機1發送FIN報文段,請求關閉連接,同時主機2進入LAST_ACK狀態;
第四次分手:主機1收到主機2發送的FIN報文段,向主機2發送ACK報文段,然后主機1進入TIME_WAIT狀態;主機2收到主機1的ACK報文段以后,就關閉連接;此時,主機1等待2MSL后依然沒有收到回復,則證明Server端已正常關閉,那好,主機1也可以關閉連接了。
追蹤online應用java動態運行細節
對于online應用,有時候需要關注java運行時的一些細節,可以通過Btrace命令跟蹤
https://legacy.gitbook.com/book/json-liu/btrace/details
二、項目代碼常見問題排查
在講述這個問題之前,有必要聊一下java的類加載機制以及JVM內存結構,理解了這些,對于我們常見的OOM問題、性能調優會帶來很大幫助
類加載機制
類加載虛擬機內存到最終卸載是有一個完整的生命周期的,它的整個生命周期包括:加載、驗證、準備、解析、初始化、使用和卸載七個階段

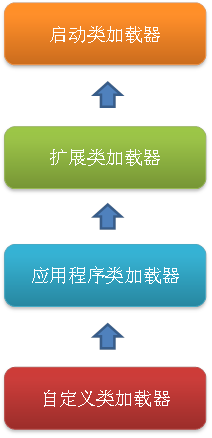
類加載過程,類加載器采用的是雙親委派原則,首先是啟動類加載器BootStrap加載,然后是擴展類加載器、應用程序加載器、
自定義類加載器
驗證:通過對class文件的類全名通過getResourceAsStream轉化成二進制流,然后將靜態的數據結構(構造函數、屬性、方法等)轉化成運行時方法區的數據結構
驗證主要有class文件格式校驗(class文件是否以一些非法字符開頭)、元數據信息校驗(比如java類是否有父類,父類是否被final修飾符修飾等等)、字節碼驗證(對類的方法進行驗證)、符號引用驗證(通過全限定名能否找到對應的類)
準備:就是對類進行分配內存、對變量進行初始化賦值 public static int = 123 賦值為0 還不是123 因為 putstatic指令存在類構造器方法中,只有在初始化階段賦值為123
解析:類、接口、方法解析,主要是將符號引用替換為直接引用,符號引用java虛擬機內存引用無關,直接引用可以是指針位置,偏移量可以具體定位到內存具體位置的
初始化:對變量進行賦值,putstatic getstatic、invokestatic指令,《clinit》構造方法中,進行賦值
JVM內存結構
java虛擬機在執行java代碼的時候,會把它所管理的內存劃分不同的區域,JVM內存的劃分結構如下:
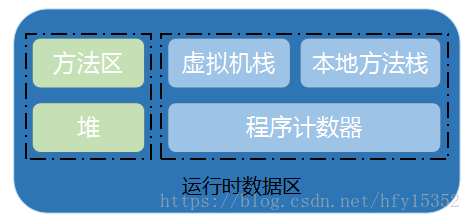
其中方法區和堆區是所有線程共享的區域,虛擬機棧、本地方法棧、程序計數器是線程私有
在這幾個區域中,除了程序計數器不會產生oom問題,其他區域都有可能產生oom
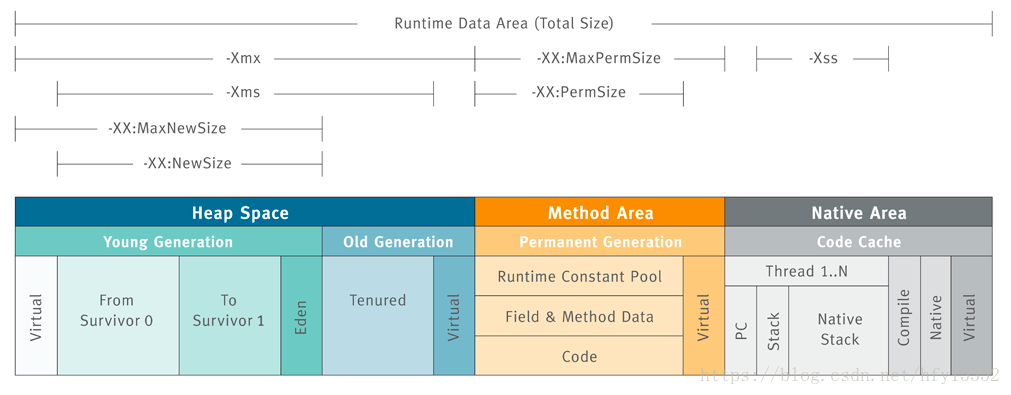
堆區
java heap是JVM內存最大的一塊區域,幾乎所有的java實例以及數組分配都在這里完成,根據內存的回收算法,可以將堆區劃分年輕代和老年代,比例為1:2的關系,其中年輕代又分為Eden和2個survival區,為8:1:1的關系;在這個區域最容易發生oom,一般原因有2種可能,流量峰值超過程序設定的閾值或者內存泄露;比如內存泄露最常見的就是集合局部變量,由于使用不得當,一直無法GC,就會觸發java.lang.OutOfMemoryError;
回顧一下年輕代和老年代的垃圾回收算法:在年輕代用復制算法、在老年代用標記清除、標記整理算法,對于java不同的對象,生命周期不一樣,有的存活年齡短,有的存活年齡長,JVM是如何判斷java對象實例可以GC的呢?java一般引用的是根搜索算法,從GC ROOT節點開始搜索,如果對樣到GC ROOT對象節點沒有任何引用鏈相連,就認為對象不可用;常常會有一些大對象初始化,年輕代放不了,會借代老年代存大對象,就容易產生Full GC的情況,所以對于大對象讀取一定不要一次性讀入內存,而是按照行讀取處理;如果因為堆區設置參數不合理,可以通過Xmx來調整堆區大小
方法區
在類加載過程中,會對class文件進行讀取,轉化成二進制流信息,最后轉化成元數據信息進行存儲,包括類的全限定名稱、版本、方法、字段等信息,這些在編譯時就JVM就分配內存,這塊區域就是方法區,對于一些常量池等等也在這里分配;在方法區也涉及到垃圾回收,比如類的卸載、無用的常量、無用的類都會回收;一般不斷創建動態代理會導致方法區的oom;可以通過MaxPermSize來調節方法區的大小
虛擬機棧
這一塊區域屬于線程私有的,線程要想在java虛擬機正常的運行,不僅需要計數器來記錄行號,線程還需要擁有自己的運行空間,虛擬機棧可以保存方法的運行順序,方法局部變量以及方法在運算時,需要自己的內存空間;我們把這一塊區域稱為虛擬機棧;每一個棧內部劃分局部變量表、操作數棧、動態鏈表、返回地址;方法執行都需要一塊區域存儲局部變量,方法運算時,需要內存空間,就是操作數棧,有些方法需要運行時加載指定的方法,符號引用轉化直接引用,就需要動態鏈表;方法遇到返回指令或者拋出異常就會返回,需要返回地址;在這一塊,也會產生oom問題,典型的就是線程池沒有設置大小,代碼中不斷創建線程,而創建線程需要內存空間,物理內存不夠就會oom,遇到這樣問題通常是調小棧的大小,通過Xss來設置
本地方法棧
和虛擬機棧一樣,在java虛擬機中,不但要執行java方法,還要執行本地方法,也會產生oom,除此之外,也會和虛擬機棧一樣產生棧溢出異常
程序計數器*
眾所周知,虛擬機在處理多線程時,通過輪流切換線程,來獲取CPU資源的,為了保證每個線程下次能夠正確的執行,需要記錄每個線程的當前運行位置;程序計數器的作用就是將各個線程下次所執行的(字節碼)行號(準確來說是指令的地址)記錄下來,以保證其下次執行時可以正確的執行;內存很小,幾乎可以忽略不計
講述完這2個概念之后,我們來看看java的一些常見問題
NoSuchMethodException
出現這種問題的原因一般有2種可能:java ClassLoader機制、java二方包沖突;針對ClassLoader問題可以在JVM配置-XX:+TraceClassLoading 來跟蹤class加載過程,二方包沖突直接排除pom文件沖突文件即可
三、數據庫mysql慢sql優化
想必大家在和數據庫打交道的時候,經常會遇到sql查詢很慢,數據量大的時候,性能很低。碰到這樣的問題有一定開發經驗的同學想到通過explain執行計劃,來分析sql;綜合業務場景建立合適的索引來優化;在這里我只是總結一下如何分析慢sql,以及如何建立索引
談到索引,不得不提到數據結構;mysql是一種關系型基于磁盤的關系型數據庫,對于磁盤的IO和從內存讀取數據性能相差好幾個量級,所以為了減少磁盤的IO次數,使用了B+樹這種多路平衡樹來存儲數據,樹的高度越低,磁盤IO次數就會越少;假設數據量為N,每個磁盤塊數據量為m,則樹的高度h=log(m+1)*N,而m=磁盤塊的大小/數據項的大小 對于B+樹,所有數據都存在葉子節點,這樣就會內節點磁盤塊就會存儲更多的內節點,每個節點的索引范圍更大,對于磁盤塊大小都固定1頁大大小,默認為16K,這樣數據項的大小越大,m越小,高度就越低。
原理闡述清楚之后,了解一下建立索引的一些原則
最左匹配原則,因為建立搜索樹的時候,是通過從做往右的順序建立的,當遇到范圍查詢、模糊查詢或者并集查詢,索引不會生效
索引字段區分度要高,也就是不重復比例要大,這樣建立索引區分數據才明顯
索引字段不能參與計算,因為B+樹存儲的data域都是字段名稱,如果含有函數計算,成本相當大
sql語句通過執行計劃分析,關鍵看rows大小,一般情況下rows越小,查詢越快,避免全表查詢,多表查詢盡量采用union或union all來查詢
關于mysql存儲引擎的區別:從5.7之后,myql默認采用InnoDB存儲引擎,相比MyISAM存儲引擎,InnoDB支持事務特性,同樣使用B+樹,但葉子節點data域存儲值不一樣,InnoDB存儲的是完整的數據記錄,默認按照主鍵索引順序,所以InnoDB一定要有主鍵,對于普通索引,data域存儲的是主鍵索引的值,所以需要先到普通索引樹中找到主鍵索引,再到主索引樹中找到相應的記錄。而MyISAM葉子節點存儲的是數據的地址,數據文件和索引文件是分離的
以上是“JAVA中線上常見問題排查手段有哪些”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





