溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一.NetApp存儲操作系統
Data ONTAP是NetApp最流行的存儲操作系統,它運行在NetApp FAS(Fabric Attached Storage)系統上。FAS系統是被設計為共享的存儲系統,它支持多種SAN和NAS存儲協議,并具有靈活的功能。
NetApp還提供在E-系列上運行的SANtricity操作系統。E系列系統是為某些應用程序應用程序需要專用的SAN存儲,特別是應用程序需要管理自己的數據。E系列系統從2011年收購Engenio發展而來。
Data ONTAP有兩種模式:7模式和集群也稱作為群集模式或CDOT)。FAS系統可以運行在7模式或集群,但不能同時運行兩種模式。兩種模式都完全相同,都是操作和控制存儲系統上的所有內容。
7模是是從NetApp的原始操作系統Data ONTAP -7G演進。集群模式是從ONTAP收購的Spinnaker發展而來,群集模式比7模式更具可擴展性。
群集ONTAP的早期軟件版本的功能與7模模相比有一些限制。在8.3之前的版本中,NetApp在兩個版本中都發布了DataONTAP以供用戶選擇,兩個版本中7模式具有全部的功能和特性,而集群模式有更好的可擴展性。而從8.3開始NetApp專注于開發集群模式,并不在開發7模式。
二.7-mode 可擴展限制
最多兩個FAS控制器可以配置為高可用性,HA配對并作為配對系統進行管理。控制器1擁有的磁盤將通過控制器1訪問。由單個節點處理的磁盤量和吞吐量是有最大限制的,可以購買額外的HA對,但是它們對客戶端來說是單獨的系統。
在同一個控制器上磁盤之間無中斷地移動數據,但在控制器這間移動將會中斷客戶端的訪單,并且比較復雜。
三.Cluster-mode
為克服7模式的可擴展性限制,NetApp完全重寫7模式軟件體系結構。集群的DataONTAP是從2003年收購Spinnaker Networks發展而來。
集群Data ONTAP能在NAS協議上擴展到24個節點,可以擴展到支持SAN協議的集群的8個節點。單個集群可以擴展到138PB。并且可以不中斷地添加磁盤,磁盤柜和節點。
整個集群可以作為單個系統進行管理。集群可以虛擬化為不同的虛擬存儲系統,稱為SVM存儲虛擬機或Vservers。SVM作為單個系統顯示給客戶端。可以創建SVM級管理員,SVM管理員呮能訪問自己的SVM。數據可以在集群中所有節點之間通過集群互連不中斷地移動。
數據處理遍布群集中的不同節點,每個都有自己的CPU,內存和網絡資源,可以提供跨集群的性能擴展和負載平衡。數據可以在群集中的多個節點上鏡像或緩存數據。
四.磁盤與磁盤柜
NetApp之前使用光纖通道連接控制器與磁盤架,但現在光纖通道磁盤架已經被其本停用了。
目前的型號使用的是SAS(串行連接SCSI)磁盤架,意思是控制器通過SAS端口和線纜連接到機柜。NetApp提供3種類型的磁盤 - SSD固態硬盤,SAS硬盤和SATA硬盤。所有3種類型的磁盤都適用于SAS磁盤架。
SSD磁盤提供最佳性能,但每GB的成本最高。
SATA(大容量)磁盤提供最低的性能,但是每GB成本最低。
SAS(性能)磁盤平衡了每GB的性能和成本。
五.NetApp存儲網絡
可以通過實施VLAN,可以提高局域網的性能和安全性。將LAN劃分為第2層的單獨廣播域在終端主機插入的端口上配置接入VLAN,只有該特定VLAN的流量才會被發送出訪問端口。配置全部在交換機上進行,終端主機不會知道自己的VLAN。
在交換機之間的鏈路上配置Dot1Q中繼,以傳輸需要攜帶多個VLAN的流量。當交換機將流量轉發到另一個交換機時,它將其標記在具有正確VLAN的第2層Dot1Q頭,接收交換機只會轉發出來的端那個VLAN。
終端主機通常只是一個VLAN的成員,并不會意識到VLAN的存在。一個特殊情況是虛擬化的主機,其中有多個虛擬機連接到不同的子網,在這種情況下,我們需要將VLAN中繼到主機。
NIC Teaming是將多個物理網卡組合成一個邏輯接口, 以提供冗余和(可選)負載平衡。NIC Teaming也被稱作為綁定、負載或聚合。當在交換機上將多個物理端口捆綁為一個邏輯鏈路上時它被稱為端口通道(Port Channel),以太通道(Ether channel)或鏈路束(Link Bundle)。
在服務器上將網卡進行主/備組合,所有流量都將通過主物理端口傳輸。如果該端口出現故障,流量將自動故障切換到備用端口。對于主備冗余,不需要在交換機上估任何配置。
主動/主動的NIC Teaming,流量將在所有的物理端口上負載平衡。在端口出現故障的情況下,有多個端口提供冗余。對于主動/主動模式,服務器和連接的交換機都需要將物理端口加入一個邏輯鏈路,兩端的配置需要一致。用于協商服務器和交換機之間的協議有:靜態802.3ad或LACP鏈路聚合控制協議,如果服務器和交換機都支持LACP,那么它是首選。
六.SAN存儲入門
SAN術語:
LUN(邏輯單元號)對主機呈現為磁盤
LUN特定于SAN(而不是NAS)協議
客戶端被稱為發起者
存儲系統稱為目標
光纖通道是原始的SAN協議,并且仍然非常流行。它使用專用適配器,電纜和交換機。不同于以太網在OSI中的分層(包括物理層),FCP通過光纖通道網絡發送SCSI命令。光纖通道是一個非常穩定可靠的協議,它是無損的,不像TCP和UDP,它支持2,4,6,8和16 Gbps的帶寬
FCP使用WWN全名稱進行尋址,WWN是由16個十六進制字符組成的8字節地址,格式為:15:00:00:f0:8c:08:95:de。 WWNN全名稱在存儲網絡中分配給該節點,同一個WWNN可以識別單個網絡節點的多個網絡接口。
在節點上,每個單獨的端為會被分配不同的WWPN全名稱端口名。多端口HBA在每個端口上具有不同的WWPN。WWPN相當于以太網中的MAC地址,WWPN被制造商燒錄,并保證在全球唯一。WWPN分配到客戶端和存儲系統上的HBA上,當配置光纖通道網絡時,我們主要關心WWPN,而不是WWNN。
可以配置別名進行更方便的配置和故障排除,例如,我們可以為具有WWPN的Exchange Server 15:00:00:f0:8c:08:95:de創建一個名為EXCHANGE-SERVER的別名。可以在光纖通道交換機和存儲系統上配置別名。
為了安全起見,將在交換機上配置分區(zoning)以進行控制哪些主機被允許相互通信,在光纖通道網絡上服務器被允許與存儲系統通信,但是服務器將不允許彼此通信。
將正確的LUN呈現給正確的主機至關重要,如果錯誤的主機能夠連接到LUN,那么它可能會損壞它。分區防止未經授權的主機連接到存儲系統,但它不會阻止主機訪問它所到達的錯誤的LUN。在存儲系統上配置LUN mask,以將LUN鎖定到被授權訪問的主機。為了保護存儲,需要在交換機上配置分區并存儲系統上的LUN masking.
光纖通道網絡中的每個交換機將被分配一個唯一的Domain ID,網絡中的一個交換機將被自動分配為根交換機,它將為其他交換機分配Domain ID。每個交換機根據他們的Domain ID偵聽網絡中的其他交換機以及如何路由去其它機換機。
當服務器或存儲系統的HBA加電時,它將發送一個FLOGI Fabric登錄請求到其本地連接的光纖通道交換機,然后交換機將為其分配24位FCID光纖通道ID地址。分配給主機的FCID由交換機的域ID和主機接入的交換機端口生成。FCID類似于IP地址。由光纖通道交換機使用在服務器及其存儲之間路由流量。交換機維護FCID表到WWPN地址映射到主機所在的端口。
光纖通道交換機共享FLOGI數據庫信息,彼此使用FCNS光纖通道名稱服務(Channel Name Service)。網絡中的每個交換機都會學習每個WWPN在哪里以及如何路由。
FLOGI Fabric登錄過程完成后,發起者將發送PLOGI端口登錄,基于在交換機上的分區配置,主機將學習它可用的目標WWPN。最后發起主機將向其目標發送PLRI進程登錄到存儲,存儲系統將基于它配置的LUN masking授予對主機的訪問權限.
在企為中服務器訪問其存儲是關鍵任務,必須沒有單點失效問題。所以需要配置冗余光纖通道網絡。每個服務器和存儲系統都將通過冗余的HBA端口連接到兩個光纖通道網絡。
光纖通道交換機將共享信息彼此分發的信息(例如Domain ID,FCNS數據庫和Zoning)。如果其中的一個交換機發生錯誤能夠傳播到另一臺交換機上,這樣使兩臺交換機失效并降低服務器到存儲的連接。因此,不同旁路的FABRIC不要相互交叉連接,兩個旁路fabric保持物理分離。主機連接到兩個FABRICS,但交換機不是.
存儲使用ALUA非對稱邏輯單元分配,存儲系統告訴客戶端哪些是其使用的首選路徑。將擁有LUN的節點的直接路徑標記為優化路徑,其他路徑被標記為非優化路徑。
在進程登錄期間,啟動者將檢測可用的端口連接到存儲目標端口組,并且ALUA將會通知哪些是首選路徑,啟動者上的多路徑軟件將選擇哪些路徑或路徑可以到達存儲。所有流行的操作系統都有多路徑軟件,并支持主動/主動或主動/備用路徑。客戶端的某個端口如果失效將自動故障轉移到備用路徑。
客戶端與SAN存儲的連接與以太網的工作方式完全不同。在以太網中,所有的路由和交換決策都是由網絡基礎設備處理的。但在SAN存儲中,由客戶端和主機啟用多路徑智能選擇。
在光纖通道中,發起者將通過FLOGI自動檢測可用路徑,在發起者上的PLOGI和PLRI進程將選擇哪個路徑或使用路徑。
iSCSI是互聯網小型計算機系統接口協議,它運行在以太網上,最初被視為一個較少便宜的替代光纖通道方案。它具有更高的頭部分組開銷,可靠性和性能比光纖通道低。它通過以太網運行,可以共享數據網絡或擁有自己的數據專用網絡基礎設施。TOE(TCP卸載引擎)卡是可以使用的專業適配器,用于降低服務器的CPU負載。有時稱為iSCSI HBA。
光纖通道使用WWN來識別發起者和目標,iSCSI使用IQN iSCSI合格名稱(或較不常見的EUI擴展唯一)標識符進行尋址。IQN最多可達255個字符,具有以下格式:iqn.yyyy-mm.naming-authority:唯一的名字例如iqn.1991-05.com.microsoft:testHost。IQN作為一個整體分配給主機,類似于Fiber中的WWNN。ISCSI通過以太網運行,因此各個端口由IP地址尋址。
iSCSI不支持光纖通道FLOGI/ PLOGI / PLRI進程,管理員必須通過指定明確地將發啟者指向其目標端口組中的IP地址之一,然后,它將發現目標的IQN和TPG中的其他端口。發啟器上的多路徑軟件可以選擇哪個路徑或要采取的路徑。雖然它運行在以太網上,但iSCSI仍然是SAN協議,在發啟者上仍使用多路徑軟件進行智能選路。
LUN masking的配置方式與使用光纖通道相同,在存儲系統上使用IQN而不是WWPN識別客戶端。iSCSI不支持Zoning。通常在發啟都上配置基于密碼的身份驗證以防范欺騙***。端到端也可以啟用IPSec加密來增強安全性。
以太網光纖通道(FCoE)是最新的SAN協議,隨著10Gbps以太網的出現成為可能,在相同的適配器上以足夠的帶寬來支持數據和存儲流量。
FCoE使用封裝在以太網中的光纖通道協議,但在以太網上運行。QoS用于保證存儲流量所需的帶寬,它保留了光纖通道的可靠性和性能。
以太網光纖通道(FCoE)的工作方式與原本的光纖通道FCP的工作原理一樣,只是封裝在以太網中,以便可以越過以太網。我們仍然有WWPN的發起者和目標,并使用FLOGI,PLOGI和PLRI過程。
在FCoE中,存儲和數據流量都是共享物理接口,存儲流量使用FCP,因此需要WWPN。以太網數據流量需要一個MAC地址,以太網數據流量和FCP存儲流量的工作原理完全不同,所以我們如何能讓物理接口夠同時支持他們?答案是 - 我們將物理接口虛擬化為兩個虛擬接口:具有以太網數據流量的MAC地址的虛擬NIC和具有WWPN的虛擬HBA用于存儲流量。存儲和數據流量分為兩個不同的VLAN中。
光纖通道在發起者和目標之間傳輸是無損協議,它確保沒有幀丟失。以太網不是無損的。 TCP需要得到接收方的確認,以確認數的據到達目的地。如果確認未被收到,數據包將被重新發送。FCoE使用假設無損網絡的FCP,所以我們需要一種方法確保我們的存儲數據包在穿過以太網時不會丟失。
PFC優先流量控制用于以太網的FCoE擴展確保無損到達,PFC以逐跳為基礎工作。必須在發起者和目標之間的路徑中的每個NIC和交換機都必須支持FCoE。具有FCoE功能的網卡被稱為CNA融合網絡適配器。
NIC:網絡接口適配器, 傳統的以太網卡,它被用于NAS協議和iSCSI。
TOE:TCP卸載引擎, 用于從服務器的CPU中卸載TCP / IP處理,可以提高NAS協議和iSCSI的性能。
HBA:主機總線適配器。 光纖通道等效于NIC。
iSCSI HBA:針對iSCSI優化的以太網TOE卡。
CNA:融合網絡適配器。 支持FCoE的10Gb以太網卡。
UTA:通用目標適配器 支持FCoE的NetApp專有卡或光纖通道。
RAID是廉價磁盤或冗余冗余陣列,多個物理磁盤組合成一個邏輯單元提供冗余或改進的性能,或兩者兼而有之。與單個磁盤相比,不同的RAID級別提供不同級別的冗余和性能,RAID可以通過操作系統的軟件進行管理或由硬件RAID控制器控制。
七.NetApp 存儲系統配置
Vol0
存儲系統出工廠時,它已經安裝有Data ONTAP
操作系統映像是安裝在CompactFlash(CF卡)上
系統配置信息存儲在硬盤上
需要一個已存在的聚合和卷來存放系統配置
Aggr0和Vol0存在于集群中的每個節點上
系統信息包括復制數據庫(RDB)和日志文件存儲在Vol0上
系統信息在集群上的節點網絡之間復制
不要在Vol0上存放用戶數據,它僅用于存儲系統信息
復制數據庫(RDB)
RDB包括五個單元:
- 管理網關
- 卷位置數據庫
- 虛擬接口管理器
- 阻止配置和操作管理
- 配置復制服務
群集中的某一個節點將被選定為每個節點的復制RDB信息
相同的節點在發生故障轉移時將成為新的主節點
管理網關
管理網關提供管理CLI
集群作為一個整體,可以通過一個命令行對整個集群進行管理,而不需要對每個節點進行單獨的配置
通過連接到集群的管理地址來管理集群,可以使用GUI或CLI模式
當在集群中發生任何更改時,這些更改將在整個集群所有節點中復制
卷位置數據庫(VLDB)
卷位置數據庫列出哪個聚合包含哪些卷,以及哪個節點包含哪些聚合
客戶端可以連接到不同的節點查看卷,而不需要到卷的宿主節點上。VLDB允許集群中的所有節點跟蹤卷位于哪里
管理員可以將卷移動到不同的聚合,這個時候將觸發VLDB更新
VLDB緩存在每個節點的內存中,以優化性能
虛擬接口管理器(VIFMGR)
虛擬接口管理器列出邏輯接口當前開啟在哪個物理接口上
IP地址存在于邏輯接口(LIF)
如果發生故障切換,邏輯接口可以移動到不同的物理接口
磁盤塊配置和操作管理(BCOM)
BCOM存儲關于SAN協議的信息
包含LUNs和iGroups (LUN Masking)上的信息
配置復制服務(CRS)
配置復制服務是用于MetroCluster去復制配置和操作數據復制到遠程輔協集群
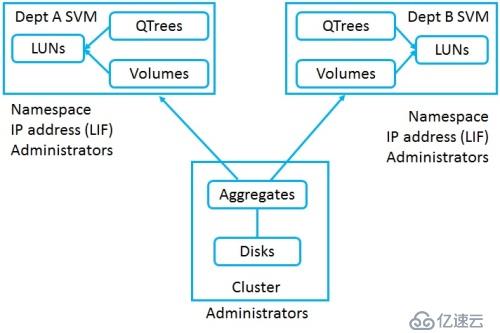
數據SVMs
數據SVM向客戶端提供數據
默認(初始)情況下不存在數據SVM
您必須至少有一個數據SVM并包含卷以讓客戶端訪問數據
您可以為不同部門創建多個數據SVM來創建分離的安全邏輯存儲系統
管理的SVM
管理SVM也稱為群集管理服務器,它提供對系統的管理訪問
管理SVM是在系統設置過程中創建的
管理SVM不托管用戶卷,它是純粹用于管理訪問
管理SVM擁有集群管理LIF,集群管理LIF可以故障轉移到整個集群中的另一個物理端口
節點SVM
節點SVM也純粹用于管理訪問
在系統設置期間也創建節點SVM
節點SVM擁有該節點的節點管理LIF
節點管理LIF可以故障切換到同一個節點的另一個物理端口
就像群集管理LIF一樣,節點管理LIF也可以用于管理整個集群,而不僅僅是該個體節點
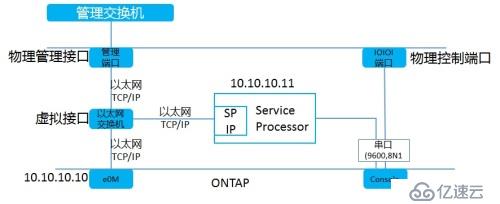
服務處理器(SP)
服務處理器提供對于控制器的遠程管理功能
SP是控制器內獨立系統,只要電源線連通后,SP例可以使用,即使Data ONTAP處理關閉狀態
可以通過SP的CLI查看環境屬性,如溫度、風扇速度、電壓等
如果管理IP地址沒有響應,可以通過連接到Data ONTAP CLI重新啟動系統。
如果有任何環境限制,SP可以關閉控制器,并通知NetApp支持
cluster1::>system nodeservice-processor network modify –node cluster1-01
-address-type IPv4 -enable true-ip-address 172.23.1.14
-netmask 255.255.255.0 –gateway172.23.1.254
訪問服務處理器
有兩種方式訪問服務處理器
通過SSH服務處理器的IP地址
在控制器會話中按Ctrl+G, 按Ctrl+D結束會話
登陸到SP需要使用一個特別的用戶名:naroot,并使用admin的密碼
硬件輔助的故障轉移
HA pair對之間的控制器通過HA連接線相互發送keepaives
如果多個keepalives未收到,開始故障轉移
通過硬件輔助的故障轉移,如果檢測到自己的控制器失效,SP發送信號到對端控制器并要求立即接管。
授權,有三種授權
標準授權
標準許可證是節點鎖定許可證。許可證與節點的序列號相關聯。如果節點離開集群,許可證將一起離開集群。只要集群中至少有一個節點,功能就可以使用。集群中的每個節點都應具有許可證。
站點授權
站點許可證與集群序列號相關,而不是特定的節點。功能可用于集群中的所有節點。如果一個節點離開集群,許可證仍然會留在站點。
評估授權
評估許可證是演示許可,有過期時間限制。它們與集群序列號綁定,而不是特定節點。功能可用于集群中的所有節點。如果一個節點離開了集群,許可證仍然會留在站點。
八.NetApp 物理資源與結構
存儲結構
SVM (Vservers) 結構
磁盤柜
您可以在堆疊中最多存放10個磁盤柜,最佳做法是不要在相同的堆棧中混合媒體類型,將以0結尾ID分配頂層的磁盤柜。
磁盤(和由它們組成的聚合)屬于某一個節點。如果一個節點失效,HA對等體可以獲取磁盤的所有權,通過SAS連接的HA對等體是主動/備用結構。節點可以通過集群互連達到其他節點的聚合交換機。
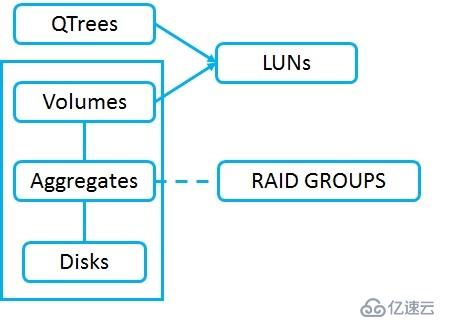
Aggr0 和vol0:當系統通電時,它將從CF卡加載Data ONTAP系統映像,然后從磁盤加載系統信息。最低可訪問數據的級別卷(volume)級別,所以需要一個aggr和vol來保存系統信息。系統根集合和卷是Aggr0和Vol0,系統信息在集群中的所有節點上復制,群集中的每個節點都有Aggr0和Vol0。如果系統出廠重置,那么所有磁盤都將被擦除,然后將再創建一個新的Aggr0,并在每個節點上創建Vol0。
Ownership: 必須將磁盤分配給HA對中的特定節點以便使用磁盤。默認情況下磁盤自動分配,自動分配可以在Stack,Shelf或bay級完成。在Stack級別,Stack中的所有磁盤都將分配給連接到Stack上的IOM-A控制器。在Shelf層,Stack中的一半Shelf將分配給每個節點。在bay級別,一個Shelf中的一半磁盤將被分配給每個節點。可以禁用自動磁盤分配,如果這樣做,需要手動分配所有新添加的磁盤到系統然后才能使用。在較小的2節點系統上,可能需要將所有磁盤分配給特定的節點,可以做一個大的聚合,這樣做,系統將作為主動/待機(而不是每個節點控制一個aggr)。客戶端的讀寫請求將只有一個節點處理。
磁盤分組到RAID組。RAID組被分配給聚合。 RAID組配置是聚合的屬性。RAID組配置指定我們擁有多少個數據磁盤、容量,多少個奇偶校驗磁盤用于冗余。
RAID組可以是RAID 4或RAID-DP。RAID 4- 單奇偶校, 存在單個硬盤故障,-aggr0的最小大小為2個磁盤,- 正常數據聚合的最小大小為3個磁盤。RAID-DP- 雙重奇偶校驗,能容忍存在兩塊硬盤故障,- aggr0的最小大小為3個磁盤,- 正常數據聚合的最小大小為5個磁盤。
RAID組中的磁盤必須是相同類型(SAS,SATA或SSD)相同的大小和速度。
如果硬盤發生故障,系統將自動將其替換為備用磁盤。相同類型、大小和速度的磁盤和數據將被重建。在重建完成之前會出現性能下降。在磁盤系統中應該至少有兩種備用磁盤,每種類型的大小和速度。
聚合可以由一個或多個RAID組組成,小的聚合將只有一個RAID組,更大的聚合將會有多個RAID組,目的是在能力和冗余之間取得良好的平衡。可以擁有由16個單個RAID-DP組組成的聚合磁盤,這將給14個數據驅動器的容量和2個奇偶校驗磁盤,為了冗余不要把一個48個硬盤的聚合只有一個RAID組。這將給46個數據磁盤和2個奇偶校驗磁盤。因為有太多的機會發生多個驅動器故障。磁盤越多故障的機率越高。使用3個大小為16個磁盤的RAID組。這樣會提高冗余能力。聚合中的所有RAID組應盡可能接近相同的大小,HDD的推薦RAID組大小為12到20個磁盤;SSD的推薦RAID組大小為20到28個磁盤。我們還需要考慮性能,擁有的磁盤越多,性能越好,因為可以同時從多個磁盤讀取和寫入數據。
高級磁盤分區,僅在入門級平臺(FAS2500)和AFF上支持ADP,它使用RAID-DP,不支持MetroCluster。新的系統配有ADP,運行較早版本的Data ONTAP的系統可以轉換為ADP。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





