溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
可見性
如果一個線程對共享變量值的修改, 能夠及時的被其他線程看到, 叫做共享變量的可見性.
Java 虛擬機規范試圖定義一種 Java 內存模型 (JMM), 來屏蔽掉各種硬件和操作系統的內存訪問差異, 讓 Java 程序在各種平臺上都能達到一致的內存訪問效果.
簡單來說, 由于 CPU 執行指令的速度是很快的, 但是內存訪問的速度就慢了很多, 相差的不是一個數量級, 所以搞處理器的那群大佬們又在 CPU 里加了好幾層高速緩存.
在 Java 內存模型里, 對上述的優化又進行了一波抽象. JMM 規定所有變量都是存在主存中的, 類似于上面提到的普通內存, 每個線程又包含自己的工作內存, 方便理解就可以看成 CPU 上的寄存器或者高速緩存.
所以線程的操作都是以工作內存為主, 它們只能訪問自己的工作內存, 且工作前后都要把值在同步回主內存.
簡單點就是, 多線程中讀取或修改共享變量時, 首先會讀取這個變量到自己的工作內存中成為一個副本, 對這個副本進行改動后, 再更新回主內存中.
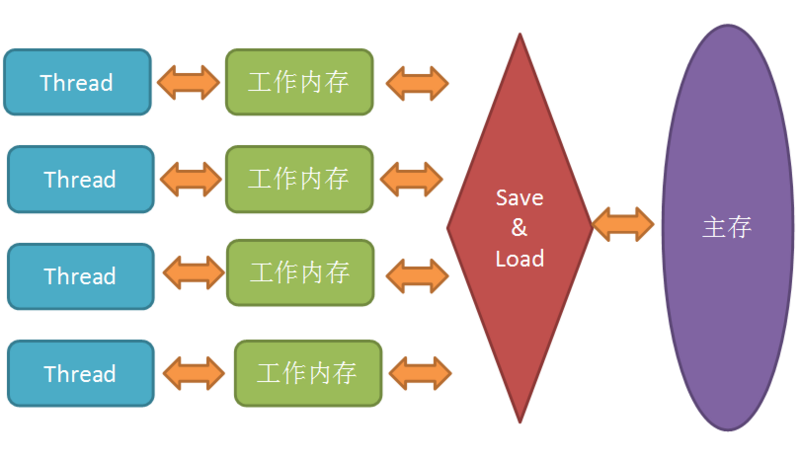
使用工作內存和主存, 雖然加快的速度, 但是也帶來了一些問題. 比如看下面一個例子:
i = i + 1;
假設 i 初值為 0, 當只有一個線程執行它時, 結果肯定得到 1, 當兩個線程執行時, 會得到結果 2 嗎? 這倒不一定了. 可能存在這種情況:
線程1: load i from 主存 // i = 0
i + 1 // i = 1
線程2: load i from主存 // 因為線程1還沒將i的值寫回主內存,所以i還是0
i + 1 //i = 1
線程1: save i to 主存
線程2: save i to 主存
如果兩個線程按照上面的執行流程, 那么 i 最后的值居然是 1 了. 如果最后的寫回生效的慢, 你再讀取 i 的值, 都可能是 0, 這就是緩存不一致問題.
這種情況一般稱為 失效數據, 因為線程1 還沒將 i 的值寫回主內存, 所以 i 還是 0, 在線程2 中讀到的就是 i 的失效值(舊值).
也可以理解成, 在操作完成之后將工作內存中的副本回寫到主內存, 并且在其它線程從主內存將變量同步回自己的工作內存之前, 共享變量的改變對其是不可見的.
有序性
有序性: 即程序執行的順序按照代碼的先后順序執行. 舉個簡單的例子, 看下面這段代碼:
int i = 0; boolean flag = false; i = 1; //語句1 flag = true; //語句2
上面代碼定義了一個 int 型變量, 定義了一個 boolean 類型變量, 然后分別對兩個變量進行賦值操作.
從代碼順序上看, 語句1 是在語句2 前面的, 那么 JVM 在真正執行這段代碼的時候會保證語句1 一定會在語句2 前面執行嗎? 不一定, 為什么呢? 這里可能會發生指令重排序.
重排序
指令重排是指 JVM 在編譯 Java 代碼的時候, 或者 CPU 在執行 JVM 字節碼的時候, 對現有的指令順序進行重新排序.
它不保證程序中各個語句的執行先后順序同代碼中的順序一致, 但是它會保證程序最終執行結果和代碼順序執行的結果是一致的(指的是不改變單線程下的程序執行結果).
雖然處理器會對指令進行重排序, 但是它會保證程序最終結果會和代碼順序執行結果相同, 那么它靠什么保證的呢? 再看下面一個例子:
int a = 10; //語句1 int r = 2; //語句2 a = a + 3; //語句3 r = a*a; //語句4
這段代碼有 4 個語句, 那么可能的一個執行順序是:

那么可不可能是這個執行順序呢?
語句2 語句1 語句4 語句3.
不可能, 因為處理器在進行重排序時是會考慮指令之間的數據依賴性, 如果一個指令 Instruction 2 必須用到 Instruction 1 的結果, 那么處理器會保證 Instruction 1 會在 Instruction 2 之前執行.
雖然重排序不會影響單個線程內程序執行的結果, 但是多線程呢? 下面看一個例子:
//線程1:
context = loadContext(); //語句1
inited = true; //語句2
//線程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);
上面代碼中, 由于語句1 和語句2 沒有數據依賴性, 因此可能會被重排序.
假如發生了重排序, 在線程1 執行過程中先執行語句2, 而此時線程2 會以為初始化工作已經完成, 那么就會跳出 while 循環, 去執行 doSomethingwithconfig(context) 方法, 而此時 context 并沒有被初始化, 就會導致程序出錯.
從上面可以看出, 指令重排序不會影響單個線程的執行, 但是會影響到線程并發執行的正確性.
原子性
Java 中, 對基本數據類型的讀取和賦值操作是原子性操作, 所謂原子性操作就是指這些操作是不可中斷的, 要做一定做完, 要么就沒有執行.
JMM 只實現了基本的原子性, 像 i++ 的操作, 必須借助于 synchronized 和 Lock 來保證整塊代碼的原子性了. 線程在釋放鎖之前, 必然會把 i 的值刷回到主存的.
重點, 要想并發程序正確地執行, 必須要保證原子性、可見性以及有序性. 只要有一個沒有被保證, 就有可能會導致程序運行不正確.
volatile 關鍵字
volatile 關鍵字的兩層語義
一旦一個共享變量 (類的成員變量、類的靜態成員變量) 被 volatile 修飾之后, 那么就具備了兩層語義:
1) 禁止進行指令重排序.
2) 讀寫一個變量時, 都是直接操作主內存.
在一個變量被 volatile 修飾后, JVM 會為我們做兩件事:
1.在每個 volatile 寫操作前插入 StoreStore 屏障, 在寫操作后插入 StoreLoad 屏障.
2.在每個 volatile 讀操作前插入 LoadLoad 屏障, 在讀操作后插入 LoadStore 屏障.
或許這樣說有些抽象, 我們看一看剛才線程A代碼的例子:
boolean contextReady = false; //在線程A中執行: context = loadContext(); contextReady = true;
我們給 contextReady 增加 volatile 修飾符, 會帶來什么效果呢?

由于加入了 StoreStore 屏障, 屏障上方的普通寫入語句 context = loadContext() 和屏障下方的 volatile 寫入語句 contextReady = true 無法交換順序, 從而成功阻止了指令重排序.

也就是說, 當程序執行到 volatile 變量的讀或寫操作時, 在其前面的操作的更改肯定全部已經進行, 且結果已經對后面的操作可見.
volatile特性之一:
保證變量在線程之間的可見性. 可見性的保證是基于 CPU 的內存屏障指令, 被 JSR-133 抽象為 happens-before 原則.
volatile特性之二:
阻止編譯時和運行時的指令重排. 編譯時 JVM 編譯器遵循內存屏障的約束, 運行時依靠 CPU 屏障指令來阻止重排.
volatile除了保證可見性和有序性, 還解決了long類型和double類型數據的 8 字節賦值問題.
虛擬機規范中允許對 64 位數據類型, 分為 2 次 32 位的操作來處理, 當讀取一個非volatile類型的 long 變量時, 如果對該變量的讀操作和寫操作不在同一個線程中執行, 那么很有可能會讀取到某個值得高 32 位和另一個值得低 32 位.
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





