溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Java爬蟲服務器被屏蔽怎么辦,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
屏蔽爬蟲程序是資源網站的一種保護措施,最常用的反爬蟲策略應該是基于用戶的訪問行為。比如限制每臺服務器在一定的時間內只能訪問 X 次,超過該次數就認為這是爬蟲程序進行的訪問,基于用戶訪問行為判斷是否是爬蟲程序也不止是根據訪問次數,還會根據每次請求的User Agent 請求頭、每次訪問的間隔時間等。總的來說是由多個因數決定的,其中以訪問次數為主。
反爬蟲是每個資源網站自保的措施,旨在保護資源不被爬蟲程序占用。例如我們前面使用到的豆瓣網,它會根據用戶訪問行為來屏蔽掉爬蟲程序,每個 IP 在每分鐘訪問次數達到一定次數后,后面一段時間內的請求返回直接返回 403 錯誤,以為著你沒有權限訪問該頁面。所以我們今天再次拿豆瓣網為例,我們用程序模擬出這個現象,下面是我編寫的一個采集豆瓣電影的程序
/**
* 采集豆瓣電影
*/
public class CrawlerMovie {
public static void main(String[] args) {
try {
CrawlerMovie crawlerMovie = new CrawlerMovie();
// 豆瓣電影鏈接
List<String> movies = crawlerMovie.movieList();
//創建10個線程的線程池
ExecutorService exec = Executors.newFixedThreadPool(10);
for (String url : movies) {
//執行線程
exec.execute(new CrawlMovieThread(url));
}
//線程關閉
exec.shutdown();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 豆瓣電影列表鏈接
* 采用反向解析法
*
* @return
*/
public List<String> movieList() throws Exception {
// 獲取100條電影鏈接
String url = "https://movie.douban.com/j/search_subjects?type=movie&tag=熱門&sort=recommend&page_limit=200&page_start=0";
CloseableHttpClient client = HttpClients.createDefault();
List<String> movies = new ArrayList<>(100);
try {
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response = client.execute(httpGet);
System.out.println("獲取豆瓣電影列表,返回驗證碼:" + response.getStatusLine().getStatusCode());
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity entity = response.getEntity();
String body = EntityUtils.toString(entity, "utf-8");
// 將請求結果格式化成json
JSONObject jsonObject = JSON.parseObject(body);
JSONArray data = jsonObject.getJSONArray("subjects");
for (int i = 0; i < data.size(); i++) {
JSONObject movie = data.getJSONObject(i);
movies.add(movie.getString("url"));
}
}
response.close();
} catch (Exception e) {
e.printStackTrace();
} finally {
client.close();
}
return movies;
}
}
/**
* 采集豆瓣電影線程
*/
class CrawlMovieThread extends Thread {
// 待采集鏈接
String url;
public CrawlMovieThread(String url) {
this.url = url;
}
public void run() {
try {
Connection connection = Jsoup.connect(url)
.method(Connection.Method.GET)
.timeout(50000);
Connection.Response Response = connection.execute();
System.out.println("采集豆瓣電影,返回狀態碼:" + Response.statusCode());
} catch (Exception e) {
System.out.println("采集豆瓣電影,采集出異常:" + e.getMessage());
}
}
}這段程序的邏輯比較簡單,先采集到豆瓣熱門電影,這里使用直接訪問 Ajax 獲取豆瓣熱門電影的鏈接,然后解析出電影的詳情頁鏈接,多線程訪問詳情頁鏈接,因為只有在多線程的情況下才能達到豆瓣的訪問要求。豆瓣熱門電影頁面如下:
多次運行上面的程序,你最后會得到下圖的結果
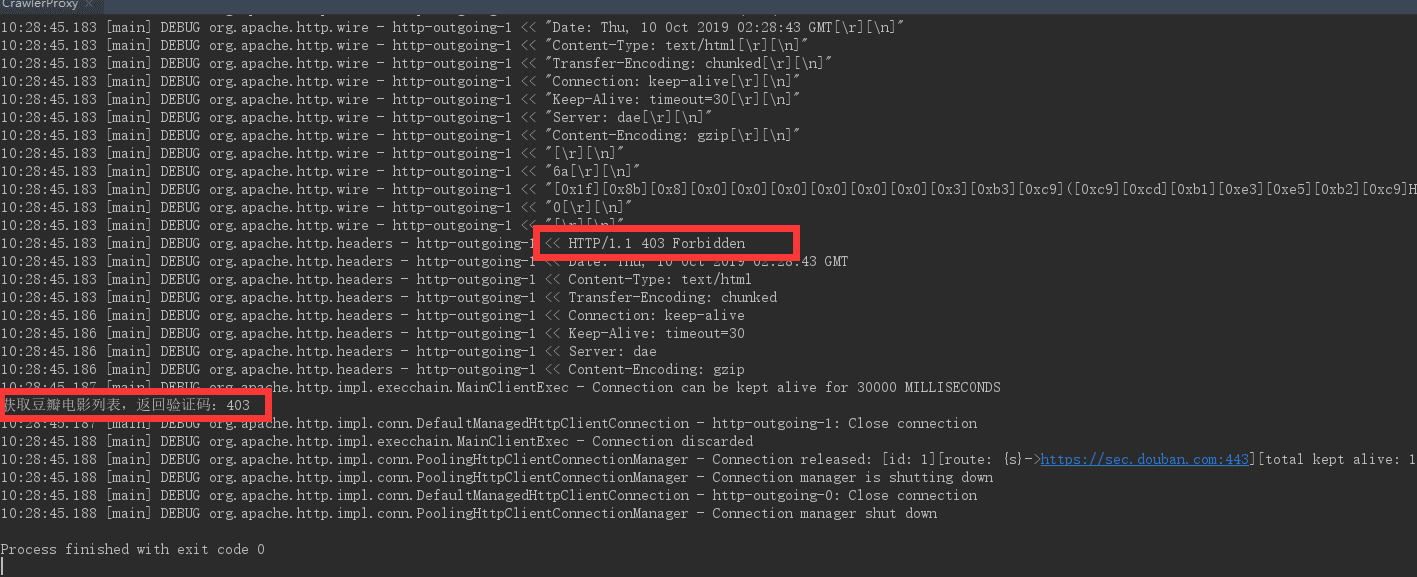
從上圖中我們可以看出,httpclient 訪問返回的狀態碼為 403 ,說明我們已經沒有權限訪問該頁面了,也就是說豆瓣網已經認為我們是爬蟲程序啦,拒接掉了我們的訪問請求。我們來分析一下我們現在的訪問架構,因為我們是直接訪問豆瓣網的,所以此時的訪問架構如下圖所示:
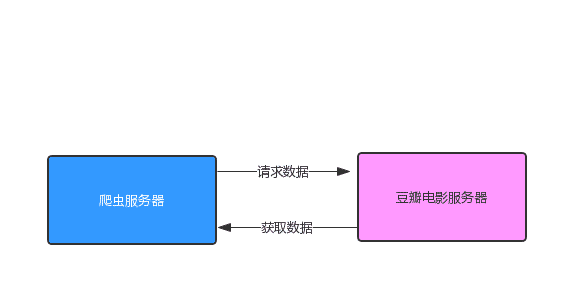
我們想要突破這層限制的話,我們就不能直接訪問豆瓣網的服務器,我們需要拉入第三方,讓別人代替我們去訪問,我們每次訪問都找不同的人,這樣就不會被限制了,這個也就是所謂的 IP代理。 此時的訪問架構就變成了下面這張圖:
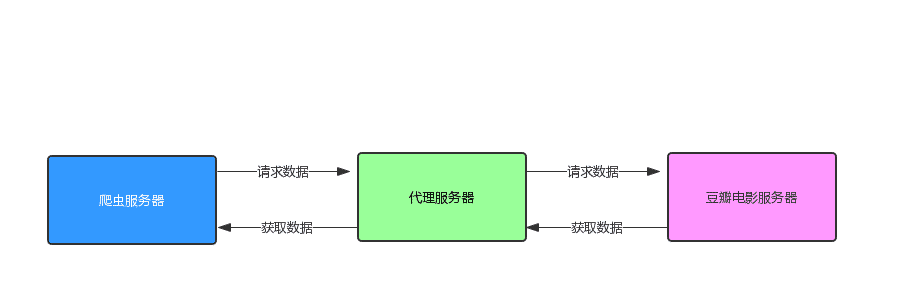
我們使用的 IP代理,我們就需要有 IP代理池,接下來我們就來聊一聊 IP 代理池
IP 代理池
代理服務器有很多廠商在做這一塊,具體的我就不說了,自己百度 IP 代理可以搜出一大堆,這些 IP代理商都有提供收費和免費的代理 IP,收費的代理 IP可用性高,速度快,在線上環境如果需要使用代理的話,建議使用收費的代理 IP。如果只是自己研究的話,我們就可以去采集這些廠商的免費公開代理 IP,這些 IP 的性能和可用性都比較差,但是不影響我們使用。
因為我們是 Demo 項目,所以我們就自己搭建 IP代理池。我們該怎么設計一個 IP代理池呢?下圖是我畫的簡單 IP代理池架構圖
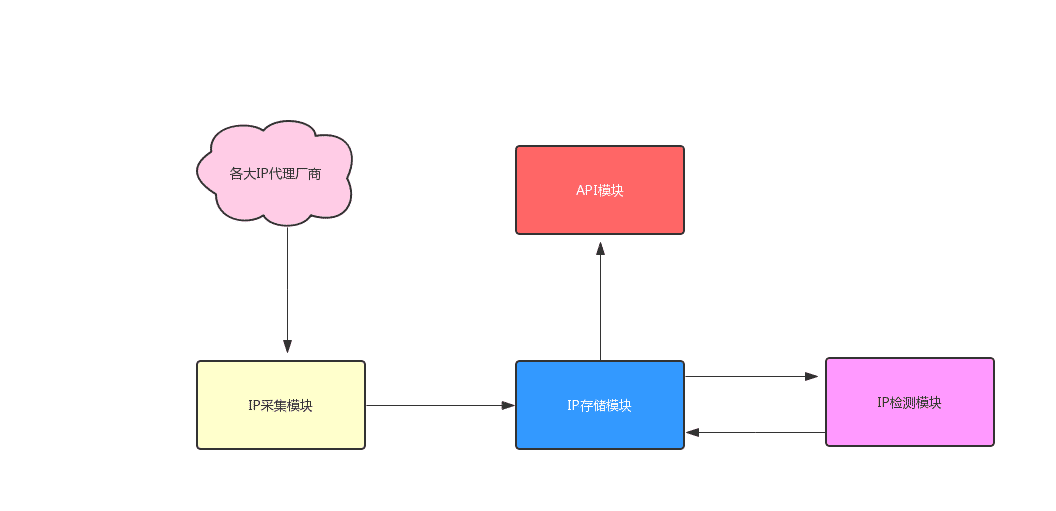
從上面的架構圖中,可以看出一個 IP 代理系統會涉及到 4 個模塊,分別為 IP 采集模塊、 IP 存儲模塊、IP 檢測模塊和 API 接口模塊。
IP 采集模塊
負責從各大 IP代理廠商采集代理 IP,采集的網站越多,代理 IP 的可用性就越高
IP 存儲模塊
存儲采集回來的代理 IP,比較常用的是 Redis 這樣的高性能的數據庫,在存儲方面我們需要存儲兩種數據,一種是檢測可用的代理 IP,另一種是采集回來還未檢測的代理 IP。
IP 檢測模塊
檢測采集回來的 IP 是否可用,這樣能夠讓我們提供的 IP 可用性變高,我們先過濾掉不可用的 IP。
API 接口模塊
以接口的形式對外提供可用代理 IP
上面就是關于 IP代理池的相關設計,對于這些我們只需要簡單了解一下就行了,因為現在基本上不需要我們去編寫 IP代理池服務啦,在 GitHub 上已經有大量優秀的開源項目,沒必要重復造輪子啦。我為大家選取了在 GitHub 上有 8K star 的開源 IP代理池項目 proxy_pool ,我們將使用它作為我們 IP 代理池。關于 proxy_pool 請訪問:https://github.com/jhao104/proxy_pool
部署 proxy_pool
proxy_pool 是用 python 語言寫的,不過這也沒什么關系,因為現在都可以容器化部署,使用容器化部署可以屏蔽掉一些環境的安裝,只需要運行鏡像就可以運行服務了,并不需要知道它里面的具體實現,所以這個項目不懂 Python 的 Java 程序員也是可以使用的。proxy_pool 使用的是 Redis 來存儲采集的 IP,所以在啟動 proxy_pool 前,你需要先啟動 Redis 服務。下面是 proxy_pool docker啟動步驟。
拉取鏡像
docker pull jhao104/proxy_pool
運行鏡像
docker run --env db_type=REDIS --env db_host=127.0.0.1 --env db_port=6379 --env db_password=pwd_str -p 5010:5010 jhao104/proxy_pool
運行鏡像后,我們等待一段時間,因為第一次啟動采集數據和處理數據需要一段時間。等待之后訪問 http://{your_host}:5010/get_all/,如果你得到下圖所示的結果,說明 proxy_pool 項目你已經部署成功。
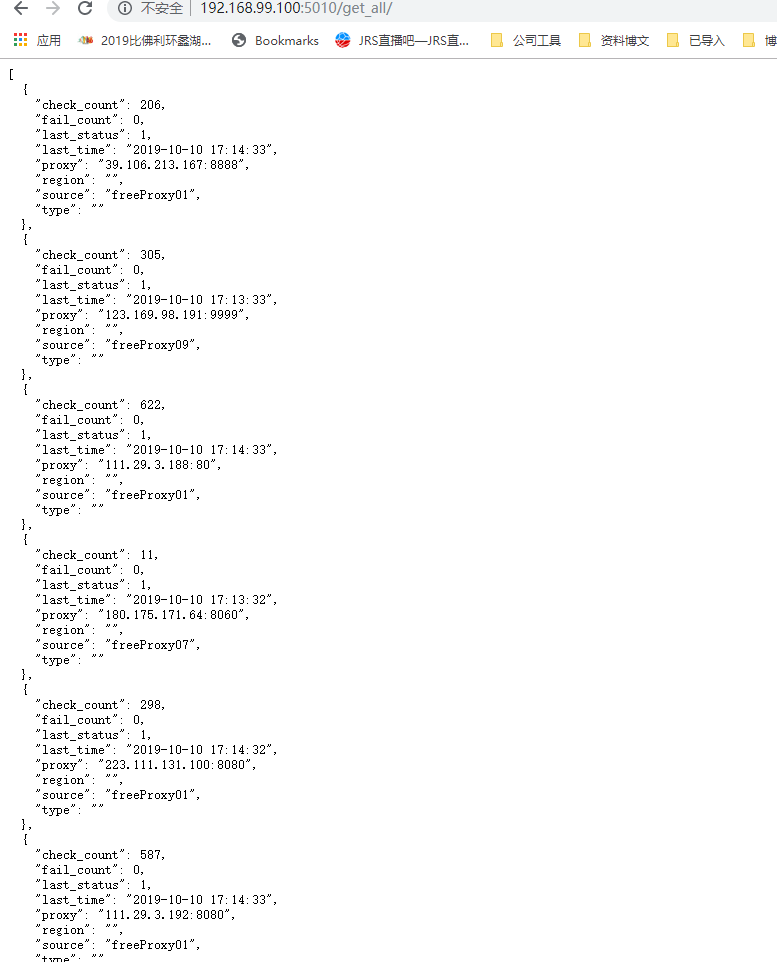
使用 IP 代理
搭建好 IP代理池之后,我們就可以使用代理 IP 來采集豆瓣電影啦,我們已經知道了除了 IP 之外,User Agent 請求頭也會是豆瓣網判斷訪問是否是爬蟲程序的一個因素,所以我們也對 User Agent 請求頭進行偽造,我們每次訪問使用不同的 User Agent 請求頭。
我們為豆瓣電影采集程序引入 IP代理和 隨機 User Agent 請求頭,具體代碼如下:
public class CrawlerMovieProxy {
/**
* 常用 user agent 列表
*/
static List<String> USER_AGENT = new ArrayList<String>(10) {
{
add("Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19");
add("Mozilla/5.0 (Linux; U; Android 4.0.4; en-gb; GT-I9300 Build/IMM76D) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30");
add("Mozilla/5.0 (Linux; U; Android 2.2; en-gb; GT-P1000 Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1");
add("Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0");
add("Mozilla/5.0 (Android; Mobile; rv:14.0) Gecko/14.0 Firefox/14.0");
add("Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36");
add("Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19");
add("Mozilla/5.0 (iPad; CPU OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A334 Safari/7534.48.3");
add("Mozilla/5.0 (iPod; U; CPU like Mac OS X; en) AppleWebKit/420.1 (KHTML, like Gecko) Version/3.0 Mobile/3A101a Safari/419.3");
}
};
/**
* 隨機獲取 user agent
*
* @return
*/
public String randomUserAgent() {
Random random = new Random();
int num = random.nextInt(USER_AGENT.size());
return USER_AGENT.get(num);
}
/**
* 設置代理ip池
*
* @param queue 隊列
* @throws IOException
*/
public void proxyIpPool(LinkedBlockingQueue<String> queue) throws IOException {
// 每次能隨機獲取一個代理ip
String proxyUrl = "http://192.168.99.100:5010/get_all/";
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(proxyUrl);
CloseableHttpResponse response = httpclient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity entity = response.getEntity();
String body = EntityUtils.toString(entity, "utf-8");
JSONArray jsonArray = JSON.parseArray(body);
int size = Math.min(100, jsonArray.size());
for (int i = 0; i < size; i++) {
// 將請求結果格式化成json
JSONObject data = jsonArray.getJSONObject(i);
String proxy = data.getString("proxy");
queue.add(proxy);
}
}
response.close();
httpclient.close();
return;
}
/**
* 隨機獲取一個代理ip
*
* @return
* @throws IOException
*/
public String randomProxyIp() throws IOException {
// 每次能隨機獲取一個代理ip
String proxyUrl = "http://192.168.99.100:5010/get/";
String proxy = "";
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(proxyUrl);
CloseableHttpResponse response = httpclient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity entity = response.getEntity();
String body = EntityUtils.toString(entity, "utf-8");
// 將請求結果格式化成json
JSONObject data = JSON.parseObject(body);
proxy = data.getString("proxy");
}
return proxy;
}
/**
* 豆瓣電影鏈接列表
*
* @return
*/
public List<String> movieList(LinkedBlockingQueue<String> queue) {
// 獲取60條電影鏈接
String url = "https://movie.douban.com/j/search_subjects?type=movie&tag=熱門&sort=recommend&page_limit=40&page_start=0";
List<String> movies = new ArrayList<>(40);
try {
CloseableHttpClient client = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
// 設置 ip 代理
HttpHost proxy = null;
// 隨機獲取一個代理IP
String proxy_ip = randomProxyIp();
if (StringUtils.isNotBlank(proxy_ip)) {
String[] proxyList = proxy_ip.split(":");
System.out.println(proxyList[0]);
proxy = new HttpHost(proxyList[0], Integer.parseInt(proxyList[1]));
}
// 隨機獲取一個請求頭
httpGet.setHeader("User-Agent", randomUserAgent());
RequestConfig requestConfig = RequestConfig.custom()
.setProxy(proxy)
.setConnectTimeout(10000)
.setSocketTimeout(10000)
.setConnectionRequestTimeout(3000)
.build();
httpGet.setConfig(requestConfig);
CloseableHttpResponse response = client.execute(httpGet);
System.out.println("獲取豆瓣電影列表,返回驗證碼:" + response.getStatusLine().getStatusCode());
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity entity = response.getEntity();
String body = EntityUtils.toString(entity, "utf-8");
// 將請求結果格式化成json
JSONObject jsonObject = JSON.parseObject(body);
JSONArray data = jsonObject.getJSONArray("subjects");
for (int i = 0; i < data.size(); i++) {
JSONObject movie = data.getJSONObject(i);
movies.add(movie.getString("url"));
}
}
response.close();
} catch (Exception e) {
e.printStackTrace();
} finally {
}
return movies;
}
public static void main(String[] args) {
// 存放代理ip的隊列
LinkedBlockingQueue<String> queue = new LinkedBlockingQueue(100);
try {
CrawlerMovieProxy crawlerProxy = new CrawlerMovieProxy();
// 初始化ip代理隊列
crawlerProxy.proxyIpPool(queue);
// 獲取豆瓣電影列表
List<String> movies = crawlerProxy.movieList(queue);
//創建固定大小的線程池
ExecutorService exec = Executors.newFixedThreadPool(5);
for (String url : movies) {
//執行線程
exec.execute(new CrawlMovieProxyThread(url, queue, crawlerProxy));
}
//線程關閉
exec.shutdown();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* 采集豆瓣電影線程
*/
class CrawlMovieProxyThread extends Thread {
// 待采集鏈接
String url;
// 代理ip隊列
LinkedBlockingQueue<String> queue;
// 代理類
CrawlerMovieProxy crawlerProxy;
public CrawlMovieProxyThread(String url, LinkedBlockingQueue<String> queue, CrawlerMovieProxy crawlerProxy) {
this.url = url;
this.queue = queue;
this.crawlerProxy = crawlerProxy;
}
public void run() {
String proxy;
String[] proxys = new String[2];
try {
Connection connection = Jsoup.connect(url)
.method(Connection.Method.GET)
.timeout(50000);
// 如果代理ip隊列為空,則重新獲取ip代理
if (queue.size() == 0) crawlerProxy.proxyIpPool(queue);
// 從隊列中獲取代理ip
proxy = queue.poll();
// 解析代理ip
proxys = proxy.split(":");
// 設置代理ip
connection.proxy(proxys[0], Integer.parseInt(proxys[1]));
// 設置 user agent
connection.header("User-Agent", crawlerProxy.randomUserAgent());
Connection.Response Response = connection.execute();
System.out.println("采集豆瓣電影,返回狀態碼:" + Response.statusCode() + " ,請求ip:" + proxys[0]);
} catch (Exception e) {
System.out.println("采集豆瓣電影,采集出異常:" + e.getMessage() + " ,請求ip:" + proxys[0]);
}
}
}運行修改后的采集程序,可能需要多次運行,因為你的代理 IP 不一定每次都有效。代理 IP 有效的話,你將得到如下結果
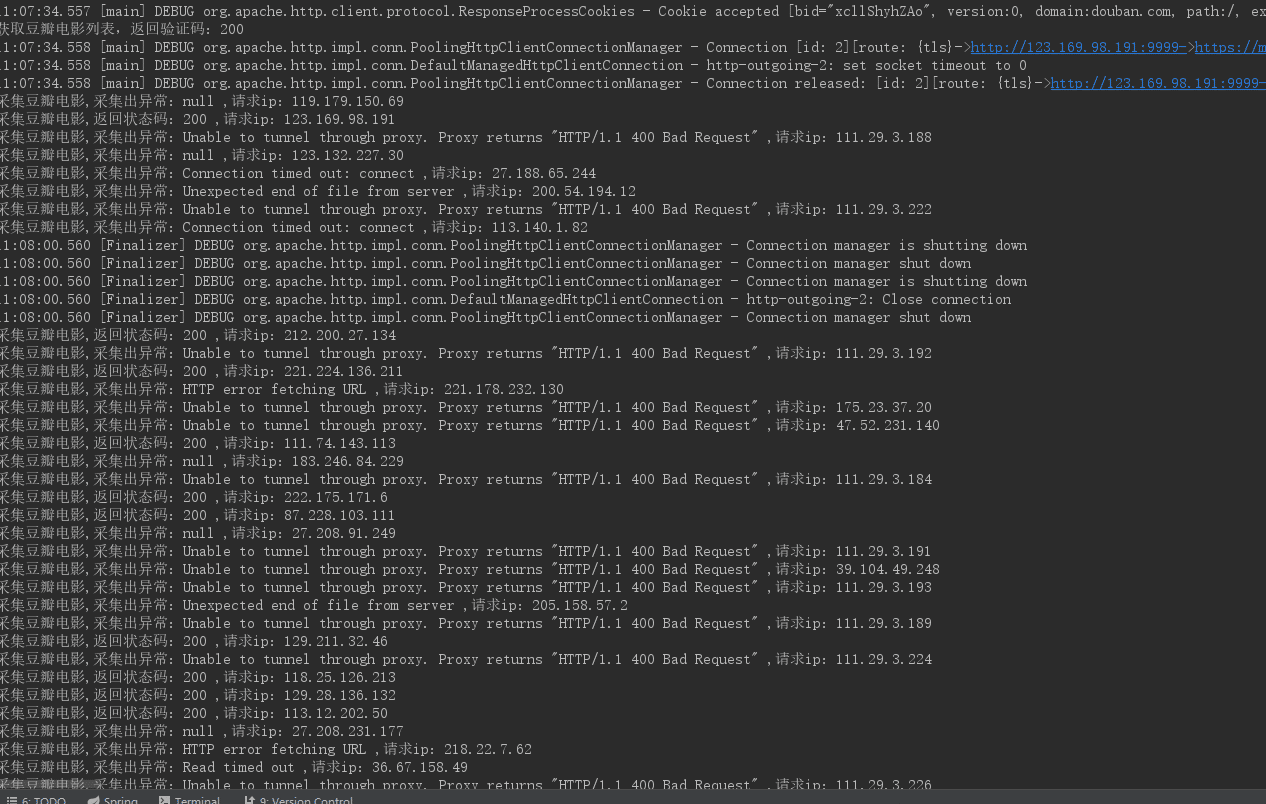
結果中我們可以看出,40 次的電影詳情頁訪問,有大量的代理 IP 是無效的,只有一小部分的代理 IP 有效。結果直接證明了免費的代理 IP 可用性不高,所以如果線上需要使用代理 IP 的話,最好使用收費的代理 IP。盡管我們自己搭建的 IP代理池可用性不是太高,但是我們設置的 IP 代理訪問豆瓣電影已經成功了,使用 IP 代理成功繞過了豆瓣網的限制。
關于爬蟲服務器被屏蔽,原因有很多,我們這篇文章主要介紹的是通過 設置 IP 代理和偽造 User Agent 請求頭來繞過豆瓣網的訪問限制。如何讓我們的程序不被資源網站視為爬蟲程序呢?需要做好以下三點:
偽造 User Agent 請求頭
使用 IP 代理
不固定的采集間隔時間
感謝你能夠認真閱讀完這篇文章,希望小編分享的“Java爬蟲服務器被屏蔽怎么辦”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





