溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
volatile的用法
volatile通常被比喻成"輕量級的synchronized",也是Java并發編程中比較重要的一個關鍵字。和synchronized不同,volatile是一個變量修飾符,只能用來修飾變量。無法修飾方法及代碼塊等。
volatile的用法比較簡單,只需要在聲明一個可能被多線程同時訪問的變量時,使用volatile修飾就可以了。
如以下代碼,是一個比較典型的使用雙重鎖校驗的形式實現單例的,其中使用volatile關鍵字修飾可能被多個線程同時訪問到的singleton。
public class Singleton {
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
volatile的原理
為了提高處理器的執行速度,在處理器和內存之間增加了多級緩存來提升。但是由于引入了多級緩存,就存在緩存數據不一致問題。
但是,對于volatile變量,當對volatile變量進行寫操作的時候,JVM會向處理器發送一條lock前綴的指令,將這個緩存中的變量回寫到系統主存中。
但是就算寫回到內存,如果其他處理器緩存的值還是舊的,再執行計算操作就會有問題,所以在多處理器下,為了保證各個處理器的緩存是一致的,就會實現緩存一致性協議
緩存一致性協議:每個處理器通過嗅探在總線上傳播的數據來檢查自己緩存的值是不是過期了,當處理器發現自己緩存行對應的內存地址被修改,就會將當前處理器的緩存行設置成無效狀態,當處理器要對這個數據進行修改操作的時候,會強制重新從系統內存里把數據讀到處理器緩存里。
所以,如果一個變量被volatile所修飾的話,在每次數據變化之后,其值都會被強制刷入主存。而其他處理器的緩存由于遵守了緩存一致性協議,也會把這個變量的值從主存加載到自己的緩存中。這就保證了一個volatile在并發編程中,其值在多個緩存中是可見的。
volatile與可見性
可見性是指當多個線程訪問同一個變量時,一個線程修改了這個變量的值,其他線程能夠立即看得到修改的值。
Java內存模型規定了所有的變量都存儲在主內存中,每條線程還有自己的工作內存,線程的工作內存中保存了該線程中是用到的變量的主內存副本拷貝,線程對變量的所有操作都必須在工作內存中進行,而不能直接讀寫主內存。不同的線程之間也無法直接訪問對方工作內存中的變量,線程間變量的傳遞均需要自己的工作內存和主存之間進行數據同步進行。所以,就可能出現線程1改了某個變量的值,但是線程2不可見的情況。
前面的關于volatile的原理中介紹過了,Java中的volatile關鍵字提供了一個功能,那就是被其修飾的變量在被修改后可以立即同步到主內存,被其修飾的變量在每次是用之前都從主內存刷新。因此,可以使用volatile來保證多線程操作時變量的可見性。
volatile與有序性
有序性即程序執行的順序按照代碼的先后順序執行。
除了引入了時間片以外,由于處理器優化和指令重排等,CPU還可能對輸入代碼進行亂序執行,比如load->add->save 有可能被優化成load->save->add 。這就是可能存在有序性問題。
而volatile除了可以保證數據的可見性之外,還有一個強大的功能,那就是他可以禁止指令重排優化等。
普通的變量僅僅會保證在該方法的執行過程中所依賴的賦值結果的地方都能獲得正確的結果,而不能保證變量的賦值操作的順序與程序代碼中的執行順序一致。
volatile可以禁止指令重排,這就保證了代碼的程序會嚴格按照代碼的先后順序執行。這就保證了有序性。被volatile修飾的變量的操作,會嚴格按照代碼順序執行,load->add->save 的執行順序就是:load、add、save。
volatile與原子性原子性是指一個操作是不可中斷的,要全部執行完成,要不就都不執行。
線程是CPU調度的基本單位。CPU有時間片的概念,會根據不同的調度算法進行線程調度。當一個線程獲得時間片之后開始執行,在時間片耗盡之后,就會失去CPU使用權。所以在多線程場景下,由于時間片在線程間輪換,就會發生原子性問題。
為了保證原子性,需要通過字節碼指令monitorenter和monitorexit,但是volatile和這兩個指令之間是沒有任何關系的。
所以,volatile是不能保證原子性的。
在以下兩個場景中可以使用volatile來代替synchronized:
1、運算結果并不依賴變量的當前值,或者能夠確保只有單一的線程會修改變量的值。
2、變量不需要與其他狀態變量共同參與不變約束。
除以上場景外,都需要使用其他方式來保證原子性,如synchronized或者concurrent包。
我們來看一下volatile和原子性的例子:
public class Test {
public volatile int inc = 0;
public void increase() {
inc++;
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保證前面的線程都執行完
Thread.yield();
System.out.println(test.inc);
}
}
以上代碼比較簡單,就是創建10個線程,然后分別執行1000次i++操作。正常情況下,程序的輸出結果應該是10000,但是,多次執行的結果都小于10000。這其實就是volatile無法滿足原子性的原因。
為什么會出現這種情況呢,那就是因為雖然volatile可以保證inc在多個線程之間的可見性。但是無法inc++的原子性。
總結與思考
我們介紹過了volatile關鍵字和synchronized關鍵字。現在我們知道,synchronized可以保證原子性、有序性和可見性。而volatile卻只能保證有序性和可見性。
我們知道volatile關鍵字的作用是保證變量在多線程之間的可見性,它是java.util.concurrent包的核心,沒有volatile就沒有這么多的并發類給我們使用。
本文詳細解讀一下volatile關鍵字如何保證變量在多線程之間的可見性,在此之前,有必要講解一下CPU緩存的相關知識,掌握這部分知識一定會讓我們更好地理解volatile的原理,從而更好、更正確地地使用volatile關鍵字。
CPU緩存
CPU緩存的出現主要是為了解決CPU運算速度與內存讀寫速度不匹配的矛盾,因為CPU運算速度要比內存讀寫速度快得多,舉個例子:
這種訪問速度的顯著差異,導致CPU可能會花費很長時間等待數據到來或把數據寫入內存。
基于此,現在CPU大多數情況下讀寫都不會直接訪問內存(CPU都沒有連接到內存的管腳),取而代之的是CPU緩存,CPU緩存是位于CPU與內存之間的臨時存儲器,它的容量比內存小得多但是交換速度卻比內存快得多。而緩存中的數據是內存中的一小部分數據,但這一小部分是短時間內CPU即將訪問的,當CPU調用大量數據時,就可先從緩存中讀取,從而加快讀取速度。
按照讀取順序與CPU結合的緊密程度,CPU緩存可分為:
每一級緩存中所存儲的數據全部都是下一級緩存中的一部分,這三種緩存的技術難度和制造成本是相對遞減的,所以其容量也相對遞增。
當CPU要讀取一個數據時,首先從一級緩存中查找,如果沒有再從二級緩存中查找,如果還是沒有再從三級緩存中或內存中查找。一般來說每級緩存的命中率大概都有80%左右,也就是說全部數據量的80%都可以在一級緩存中找到,只剩下20%的總數據量才需要從二級緩存、三級緩存或內存中讀取。
使用CPU緩存帶來的問題
用一張圖表示一下CPU-->CPU緩存-->主內存數據讀取之間的關系:
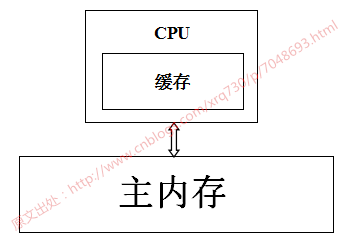
當系統運行時,CPU執行計算的過程如下:
程序以及數據被加載到主內存指令和數據被加載到CPU緩存CPU執行指令,把結果寫到高速緩存高速緩存中的數據寫回主內存
如果服務器是單核CPU,那么這些步驟不會有任何的問題,但是如果服務器是多核CPU,那么問題來了,以Intel Core i7處理器的高速緩存概念模型為例(圖片摘自《深入理解計算機系統》):
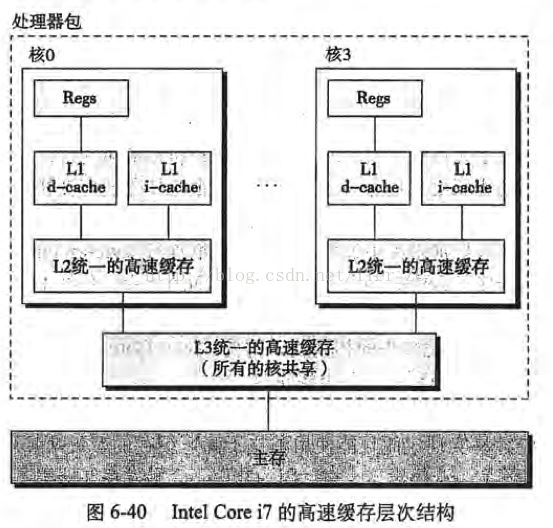
試想下面一種情況:
核0讀取了一個字節,根據局部性原理,它相鄰的字節同樣被被讀入核0的緩存核3做了上面同樣的工作,這樣核0與核3的緩存擁有同樣的數據核0修改了那個字節,被修改后,那個字節被寫回核0的緩存,但是該信息并沒有寫回主存核3訪問該字節,由于核0并未將數據寫回主存,數據不同步
為了解決這個問題,CPU制造商制定了一個規則:當一個CPU修改緩存中的字節時,服務器中其他CPU會被通知,它們的緩存將視為無效。于是,在上面的情況下,核3發現自己的緩存中數據已無效,核0將立即把自己的數據寫回主存,然后核3重新讀取該數據。
反匯編Java字節碼,查看匯編層面對volatile關鍵字做了什么
有了上面的理論基礎,我們可以研究volatile關鍵字到底是如何實現的。首先寫一段簡單的代碼:
/**
* @author 五月的倉頡http://www.cnblogs.com/xrq730/p/7048693.html
*/
public class LazySingleton {
private static volatile LazySingleton instance = null;
public static LazySingleton getInstance() {
if (instance == null) {
instance = new LazySingleton();
}
return instance;
}
public static void main(String[] args) {
LazySingleton.getInstance();
}
}
首先反編譯一下這段代碼的.class文件,看一下生成的字節碼:
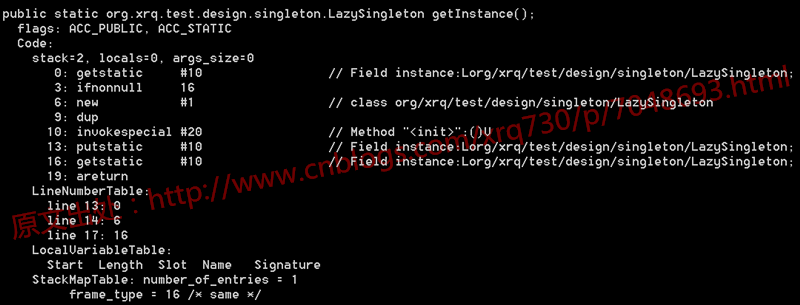
沒有任何特別的。要知道,字節碼指令,比如上圖的getstatic、ifnonnull、new等,最終對應到操作系統的層面,都是轉換為一條一條指令去執行,我們使用的PC機、應用服務器的CPU架構通常都是IA-32架構的,這種架構采用的指令集是CISC(復雜指令集),而匯編語言則是這種指令集的助記符。
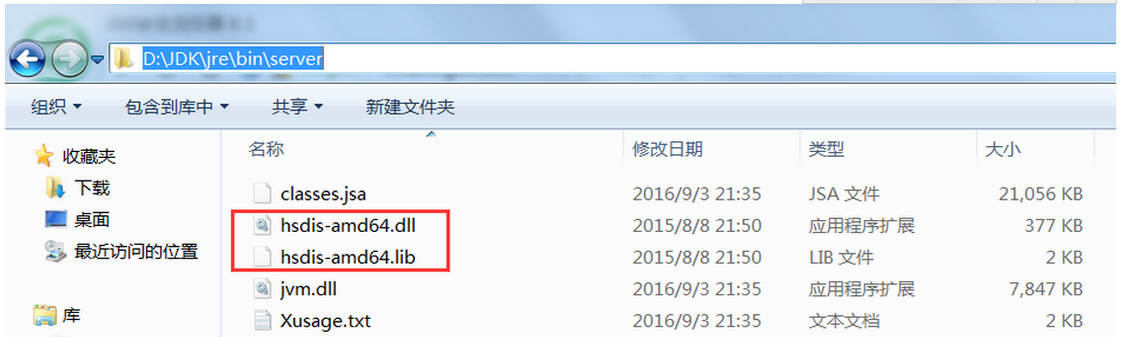
因此,既然在字節碼層面我們看不出什么端倪,那下面就看看將代碼轉換為匯編指令能看出什么端倪。Windows上要看到以上代碼對應的匯編碼不難(吐槽一句,說說不難,為了這個問題我找遍了各種資料,差點就準備安裝虛擬機,在Linux系統上搞了),訪問hsdis工具路徑可直接下載hsdis工具,下載完畢之后解壓,將hsdis-amd64.dll與hsdis-amd64.lib兩個文件放在%JAVA_HOME%\jre\bin\server路徑下即可,如下圖:
然后跑main函數,跑main函數之前,加入如下虛擬機參數:
-server -Xcomp -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -XX:CompileCommand=compileonly,*LazySingleton.getInstance
這么長長的匯編代碼,可能大家不知道CPU在哪里做了手腳,沒事不難,定位到59、60兩行:
0x0000000002931351: lock add dword ptr [rsp],0h ;*putstatic instance
; - org.xrq.test.design.singleton.LazySingleton::getInstance@13 (line 14)
之所以定位到這兩行是因為這里結尾寫明了line 14,line 14即volatile變量instance賦值的地方。后面的add dword ptr [rsp],0h都是正常的匯編語句,意思是將雙字節的棧指針寄存器+0,這里的關鍵就是add前面的lock指令,后面詳細分析一下lock指令的作用和為什么加上lock指令后就能保證volatile關鍵字的內存可見性。
lock指令做了什么
之前有說過IA-32架構,關于CPU架構的問題大家有興趣的可以自己查詢一下,這里查詢一下IA-32手冊關于lock指令的描述,沒有IA-32手冊的可以去這個地址下載IA-32手冊下載地址,是個中文版本的手冊。
我摘抄一下IA-32手冊中關于lock指令作用的一些描述(因為lock指令的作用在手冊中散落在各處,并不是在某一章或者某一節專門講):
在修改內存操作時,使用LOCK前綴去調用加鎖的讀-修改-寫操作,這種機制用于多處理器系統中處理器之間進行可靠的通訊,具體描述如下:
(1)在Pentium和早期的IA-32處理器中,LOCK前綴會使處理器執行當前指令時產生一個LOCK#信號,這種總是引起顯式總線鎖定出現
(2)在Pentium4、Inter Xeon和P6系列處理器中,加鎖操作是由高速緩存鎖或總線鎖來處理。如果內存訪問有高速緩存且只影響一個單獨的高速緩存行,那么操作中就會調用高速緩存鎖,而系統總線和系統內存中的實際區域內不會被鎖定。同時,這條總線上的其它Pentium4、Intel Xeon或者P6系列處理器就回寫所有已修改的數據并使它們的高速緩存失效,以保證系統內存的一致性。如果內存訪問沒有高速緩存且/或它跨越了高速緩存行的邊界,那么這個處理器就會產生LOCK#信號,并在鎖定操作期間不會響應總線控制請求
32位IA-32處理器支持對系統內存中的某個區域進行加鎖的原子操作。這些操作常用來管理共享的數據結構(如信號量、段描述符、系統段或頁表),兩個或多個處理器可能同時會修改這些數據結構中的同一數據域或標志。處理器使用三個相互依賴的機制來實現加鎖的原子操作:
1、保證原子操作
2、總線加鎖,使用LOCK#信號和LOCK指令前綴
3、高速緩存相干性協議,確保對高速緩存中的數據結構執行原子操作(高速緩存鎖)。這種機制存在于Pentium4、Intel Xeon和P6系列處理器中
IA-32處理器提供有一個LOCK#信號,會在某些關鍵內存操作期間被自動激活,去鎖定系統總線。當這個輸出信號發出的時候,來自其他處理器或總線代理的控制請求將被阻塞。軟件能夠通過預先在指令前添加LOCK前綴來指定需要LOCK語義的其它場合。
在Intel386、Intel486、Pentium處理器中,明確地對指令加鎖會導致LOCK#信號的產生。由硬件設計人員來保證系統硬件中LOCK#信號的可用性,以控制處理器間的內存訪問。
對于Pentinum4、Intel Xeon以及P6系列處理器,如果被訪問的內存區域是在處理器內部進行高速緩存的,那么通常不發出LOCK#信號;相反,加鎖只應用于處理器的高速緩存。
為顯式地強制執行LOCK語義,軟件可以在下列指令修改內存區域時使用LOCK前綴。當LOCK前綴被置于其它指令之前或者指令沒有對內存進行寫操作(也就是說目標操作數在寄存器中)時,會產生一個非法操作碼異常(#UD)。
【1】位測試和修改指令(BTS、BTR、BTC)
【2】交換指令(XADD、CMPXCHG、CMPXCHG8B)
【3】自動假設有LOCK前綴的XCHG指令
【4】下列單操作數的算數和邏輯指令:INC、DEC、NOT、NEG
【5】下列雙操作數的算數和邏輯指令:ADD、ADC、SUB、SBB、AND、OR、XOR
一個加鎖的指令會保證對目標操作數所在的內存區域加鎖,但是系統可能會將鎖定區域解釋得稍大一些。軟件應該使用相同的地址和操作數長度來訪問信號量(用作處理器之間發送信號的共享內存)。例如,如果一個處理器使用一個字來訪問信號量,其它處理器就不應該使用一個字節來訪問這個信號量。總線鎖的完整性不收內存區域對齊的影響。加鎖語義會一直持續,以滿足更新整個操作數所需的總線周期個數。但是,建議加鎖訪問應該對齊在它們的自然邊界上,以提升系統性能:
【1】任何8位訪問的邊界(加鎖或不加鎖)
【2】鎖定的字訪問的16位邊界
【3】鎖定的雙字訪問的32位邊界
【4】鎖定的四字訪問的64位邊界
對所有其它的內存操作和所有可見的外部事件來說,加鎖的操作都是原子的。所有取指令和頁表操作能夠越過加鎖的指令。加鎖的指令可用于同步一個處理器寫數據而另一個處理器讀數據的操作。
IA-32架構提供了幾種機制用來強化或弱化內存排序模型,以處理特殊的編程情形。這些機制包括:
【1】I/O指令、加鎖指令、LOCK前綴以及串行化指令等,強制在處理器上進行較強的排序
【2】SFENCE指令(在Pentium III中引入)和LFENCE指令、MFENCE指令(在Pentium4和Intel Xeon處理器中引入)提供了
某些特殊類型內存操作的排序和串行化功能
...(這里還有兩條就不寫了)
這些機制可以通過下面的方式使用。
總線上的內存映射設備和其它I/O設備通常對向它們緩沖區寫操作的順序很敏感,I/O指令(IN指令和OUT指令)以下面的方式對這種訪問執行強寫操作的排序。在執行了一條I/O指令之前,處理器等待之前的所有指令執行完畢以及所有的緩沖區都被都被寫入了內存。只有取指令和頁表查詢能夠越過I/O指令,后續指令要等到I/O指令執行完畢才開始執行。
反復思考IA-32手冊對lock指令作用的這幾段描述,可以得出lock指令的幾個作用:
鎖總線,其它CPU對內存的讀寫請求都會被阻塞,直到鎖釋放,不過實際后來的處理器都采用鎖緩存替代鎖總線,因為鎖總線的開銷比較大,鎖總線期間其他CPU沒法訪問內存lock后的寫操作會回寫已修改的數據,同時讓其它CPU相關緩存行失效,從而重新從主存中加載最新的數據不是內存屏障卻能完成類似內存屏障的功能,阻止屏障兩遍的指令重排序
(1)中寫了由于效率問題,實際后來的處理器都采用鎖緩存來替代鎖總線,這種場景下多緩存的數據一致是通過緩存一致性協議來保證的,我們來看一下什么是緩存一致性協議。
緩存一致性協議
講緩存一致性之前,先說一下緩存行的概念:
緩存是分段(line)的,一個段對應一塊存儲空間,我們稱之為緩存行,它是CPU緩存中可分配的最小存儲單元,大小32字節、64字節、128字節不等,這與CPU架構有關,通常來說是64字節。當CPU看到一條讀取內存的指令時,它會把內存地址傳遞給一級數據緩存,一級數據緩存會檢查它是否有這個內存地址對應的緩存段,如果沒有就把整個緩存段從內存(或更高一級的緩存)中加載進來。注意,這里說的是一次加載整個緩存段,這就是上面提過的局部性原理
上面說了,LOCK#會鎖總線,實際上這不現實,因為鎖總線效率太低了。因此最好能做到:使用多組緩存,但是它們的行為看起來只有一組緩存那樣。緩存一致性協議就是為了做到這一點而設計的,就像名稱所暗示的那樣,這類協議就是要使多組緩存的內容保持一致。
緩存一致性協議有多種,但是日常處理的大多數計算機設備都屬于"嗅探(snooping)"協議,它的基本思想是:
所有內存的傳輸都發生在一條共享的總線上,而所有的處理器都能看到這條總線:緩存本身是獨立的,但是內存是共享資源,所有的內存訪問都要經過仲裁(同一個指令周期中,只有一個CPU緩存可以讀寫內存)。
CPU緩存不僅僅在做內存傳輸的時候才與總線打交道,而是不停在嗅探總線上發生的數據交換,跟蹤其他緩存在做什么。所以當一個緩存代表它所屬的處理器去讀寫內存時,其它處理器都會得到通知,它們以此來使自己的緩存保持同步。只要某個處理器一寫內存,其它處理器馬上知道這塊內存在它們的緩存段中已失效。
MESI協議是當前最主流的緩存一致性協議,在MESI協議中,每個緩存行有4個狀態,可用2個bit表示,它們分別是:

這里的I、S和M狀態已經有了對應的概念:失效/未載入、干凈以及臟的緩存段。所以這里新的知識點只有E狀態,代表獨占式訪問,這個狀態解決了"在我們開始修改某塊內存之前,我們需要告訴其它處理器"這一問題:只有當緩存行處于E或者M狀態時,處理器才能去寫它,也就是說只有在這兩種狀態下,處理器是獨占這個緩存行的。當處理器想寫某個緩存行時,如果它沒有獨占權,它必須先發送一條"我要獨占權"的請求給總線,這會通知其它處理器把它們擁有的同一緩存段的拷貝失效(如果有)。只有在獲得獨占權后,處理器才能開始修改數據----并且此時這個處理器知道,這個緩存行只有一份拷貝,在我自己的緩存里,所以不會有任何沖突。
反之,如果有其它處理器想讀取這個緩存行(馬上能知道,因為一直在嗅探總線),獨占或已修改的緩存行必須先回到"共享"狀態。如果是已修改的緩存行,那么還要先把內容回寫到內存中。
由lock指令回看volatile變量讀寫
相信有了上面對于lock的解釋,volatile關鍵字的實現原理應該是一目了然了。首先看一張圖:
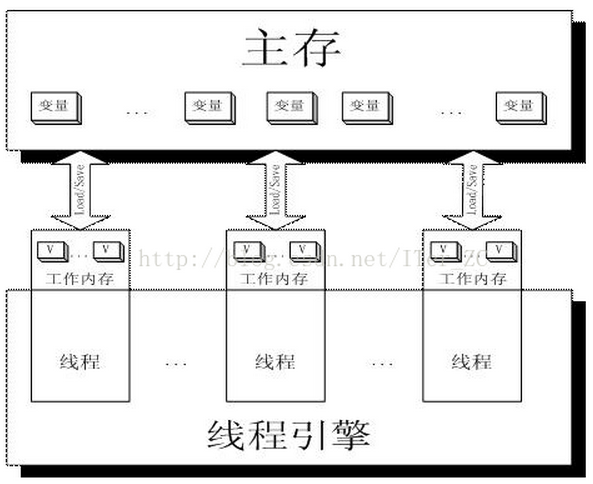
工作內存Work Memory其實就是對CPU寄存器和高速緩存的抽象,或者說每個線程的工作內存也可以簡單理解為CPU寄存器和高速緩存。
那么當寫兩條線程Thread-A與Threab-B同時操作主存中的一個volatile變量i時,Thread-A寫了變量i,那么:
Thread-A發出LOCK#指令發出的LOCK#指令鎖總線(或鎖緩存行),同時讓Thread-B高速緩存中的緩存行內容失效Thread-A向主存回寫最新修改的i
Thread-B讀取變量i,那么:
Thread-B發現對應地址的緩存行被鎖了,等待鎖的釋放,緩存一致性協議會保證它讀取到最新的值
由此可以看出,volatile關鍵字的讀和普通變量的讀取相比基本沒差別,差別主要還是在變量的寫操作上。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





