溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
利用C語言怎么對英文進行統計?針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
主要運行步驟:
1. 打開文本把文本內容讀入流中并且開辟相應空間放入內存
2 .對文本內容進行處理,去除大寫字母(轉化為小寫),去除特殊字符
3. 基于單鏈表對詞頻進行統計
4. 把統計結果進行歸并排序
5.打印輸出全部詞頻或者頻率最高的10個單詞和其出現次數
6.釋放所有結點消耗的內存
廢話不多說,上代碼!
//
// main.c
// word_frequency_statistic
//
// Created by tianling on 14-3-16.
// Copyright (c) 2014年 tianling. All rights reserved.
// 實現英文文本的詞頻統計
//
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define ERROR 1
#define OK 0
const int WORD_LENGTH = 250;//定義單個單詞最大長度
typedef int status;
/*
**定義存儲單詞及其出現次數的結構體
*/
typedef struct Node{
char word[WORD_LENGTH];
int time;
struct Node *next;
}wordNode;
wordNode *headNode = NULL;//定義鏈表頭指針
/*
**函數聲明
*/
wordNode *wordSearch(char *word,int *num);
status wordCount(char *word,int *num);
void printCountList(int *num);
void PrintFirstTenTimes();
void mergeSort(wordNode **head);
void FrontBackSplit(wordNode *head,wordNode **pre,wordNode **next);
void wordJob(char word[]);
wordNode *SortedMerge(wordNode *pre,wordNode *next);
void release();
status main(int argc,char *argv[])
{
char temp[WORD_LENGTH];//定義用以臨時存放單詞的數組
FILE *file;
int count,articleWordNum = 0;//定義統計結點個數的變量
int *num = &articleWordNum,choose;
/*
**讀取文件
*/
if((file = fopen("/Users/tianling/Documents/Data_Structure/word_frequency_statistic/word_frequency_statistic/article.txt", "r")) == NULL){
//這里是絕對路徑,基于XCode編譯器查找方便的需求
printf("文件讀取失敗!");
exit(1);
}
while((fscanf(file,"%s",temp))!= EOF){
wordJob(temp);
count = wordCount(temp,num);
}
fclose(file);//關閉文件
printCountList(num);
printf("***********請選擇***********\n");
printf("*****1. 輸出詞頻最高的10個詞**\n");
printf("*****2. 退出****************\n");
scanf("%d",&choose);
if(choose == 1){
mergeSort(&headNode);
PrintFirstTenTimes();
}else{
release();
exit(0);
}
release();
return 0;
}
/*
**查找單詞所在結點
*/
wordNode *wordSearch(char *word,int *num){
wordNode *node;//聲明一個新結點
if(headNode == NULL){//若頭結點為空
node = (wordNode*)malloc(sizeof(wordNode));
strcpy(node->word, word);//將第一個單詞賦值給這個新結點
node->time = 0;//初始化該單詞的出現次數
*num+=1;
headNode = node;//將頭結點指向這個新結點
return node;
}
wordNode *nextNode = headNode;
wordNode *preNode = NULL;
while(nextNode != NULL && strcmp(nextNode->word, word) != 0){
preNode = nextNode;
nextNode = nextNode->next;
}
//若該單詞不存在,則在鏈表中生成新結點
if(nextNode == NULL){
node = (wordNode*)malloc(sizeof(wordNode));
strcpy(node->word, word);
node->time = 0;
node->next = headNode->next;
headNode->next = node;
*num+=1;
return node;
}else
return nextNode;
}
/*
**詞頻統計
*/
status wordCount(char *word,int *num){
wordNode *tmpNode = NULL;
tmpNode = wordSearch(word,num);
if(tmpNode == NULL){
return ERROR;
}
tmpNode->time++;
return 0;
}
/*
**打印所有詞頻
*/
void printCountList(int *num){
if(headNode == NULL){
printf("該文件無內容!");
}else{
wordNode *preNode = headNode;
printf("總詞量 %d \n",*num);
while(preNode != NULL){
printf("%s 出現次數 %d\n",preNode->word,preNode->time);
preNode = preNode->next;
}
}
}
/*
**打印詞頻最高的10個詞
*/
void PrintFirstTenTimes(){
if(headNode == NULL){
printf("該文件無內容!");
}else{
wordNode *preNode = headNode;
int i = 0;
printf("出現次數最多的10個詞如下: \n");
while (preNode != NULL && i<=10) {
printf("%s 出現次數 %d\n",preNode->word,preNode->time);
preNode = preNode->next;
i++;
}
}
}
/*
**對詞頻統計結果進行歸并排序
*/
void mergeSort(wordNode **headnode){
wordNode *pre,*next,*head;
head = *headnode;
//若鏈表長度為0或1則停止排序
if(head == NULL || head->next == NULL){
return;
}
FrontBackSplit(head,&pre,&next);
mergeSort(&pre);
mergeSort(&next);
*headnode = SortedMerge(pre,next);
}
/*
**將鏈表進行分組
*/
void FrontBackSplit(wordNode *source,wordNode **pre,wordNode **next){
wordNode *fast;
wordNode *slow;
if(source == NULL || source->next == NULL){
*pre = source;
*next = NULL;
}else{
slow = source;
fast = source->next;
while(fast != NULL){
fast = fast->next;
if(fast != NULL){
slow = slow->next;
fast = fast->next;
}
}
*pre = source;
*next = slow->next;
slow->next = NULL;
}
}
/*
**根據排序結果更換頭結點
*/
wordNode *SortedMerge(wordNode *pre,wordNode *next){
wordNode *result = NULL;
if(pre == NULL)
return next;
else if(next == NULL)
return pre;
if(pre->time >= next->time){
result = pre;
result->next = SortedMerge(pre->next,next);
}else{
result = next;
result->next = SortedMerge(pre,next->next);
}
return result;
}
/*
**處理大寫字母及特殊字符
*/
void wordJob(char word[]){
int i,k;
char *specialChar = ",.;:'?!><+=|*&^%$#@\"";//定義特殊字符集
for(i = 0;i<strlen(word);i++){
//篩選并將字符串中的大寫字母轉化為小寫字母
if(word[i]>='A'&& word[i]<='Z'){
word[i] += 32;
}
//篩選并去除字符串中的特殊字符
for(k = 0;k<strlen(specialChar);k++){
if(word[i] == specialChar[k]){
while(i<strlen(word)){
word[i] = word[i+1];
i++;
}
}
}
}
}
/*
**釋放所有結點內存
*/
void release(){
if(headNode == NULL)
return;
wordNode *pre = headNode;
while(pre != NULL){
headNode = pre->next;
free(pre);
pre = headNode;
}
}調試結果:(Xcode環境)
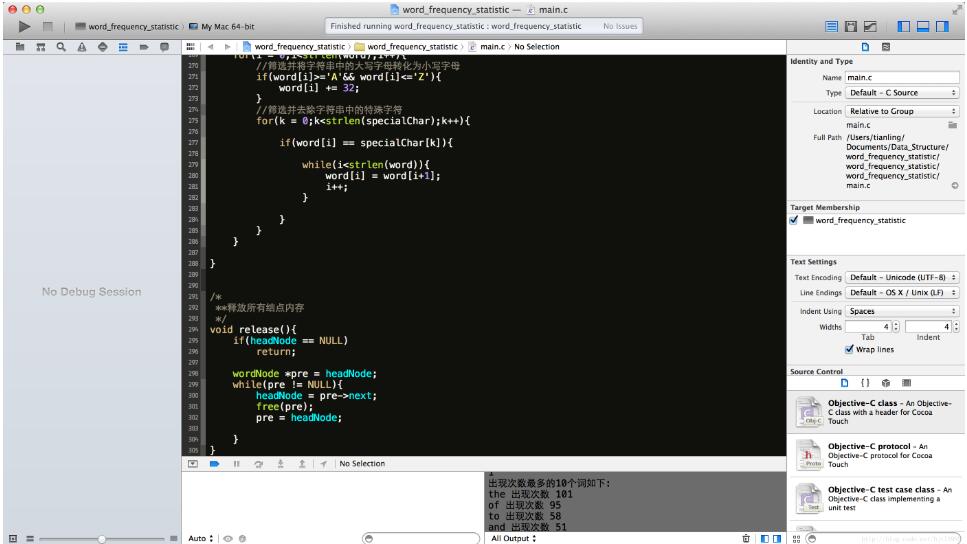
關于利用C語言怎么對英文進行統計問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





