溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python爬蟲中urllib庫有什么用,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
urllib的基本用法
urllib庫的基本組成
利用最簡單的urlopen方法爬取網頁html
利用Request方法構建headers模擬瀏覽器操作
error的異常操作
urllib庫除了以上基礎的用法外,還有很多高級的功能,可以更加靈活的適用在爬蟲應用中,比如:
使用HTTP的POST請求方法向服務器提交數據實現用戶登錄
使用代理IP解決防止反爬
設置超時提高爬蟲效率
解析URL的方法
本次將會對這些內容進行詳細的分析和講解。
POST請求
POST是HTTP協議的請求方法之一,也是比較常用到的一種方法,用于向服務器提交數據。博主先介紹進行post請求的一些準備工作,然后舉一個例子,對其使用以及更深層概念進行詳細的的剖析。
POST請求的準備工作
既然要提交信息給服務器,我們就需要知道信息往哪填,填什么,填寫格式是什么?帶這些問題,我們往下看。
同樣提交用戶登錄信息(用戶名和密碼),不同網站可能需要的東西不一樣,比如淘寶反爬機制較復雜,會有其它一大串的額外信息。這里,我們以豆瓣為例(相對簡單),目標是弄清楚POST是如何使用的,復雜內容會在后續實戰部分與大家繼續分享。
拋出上面像淘寶一樣需要的復雜信息,如果僅考慮用戶名和密碼的話,我們的準備工作其實就是要弄明白用戶名和密碼標簽的屬性name是什么,以下兩種方法可以實現。
瀏覽器F12查看element獲取
也可以通過抓包工具Fiddler獲取。
廢話不多說了,讓我們看看到底如何找到name?
1. 瀏覽器F12
通過瀏覽器F12元素逐層查看到(我是用的Chrome),郵箱/手機號標簽的name="form_email", 密碼的標簽name="form_email",如下圖紅框所示。
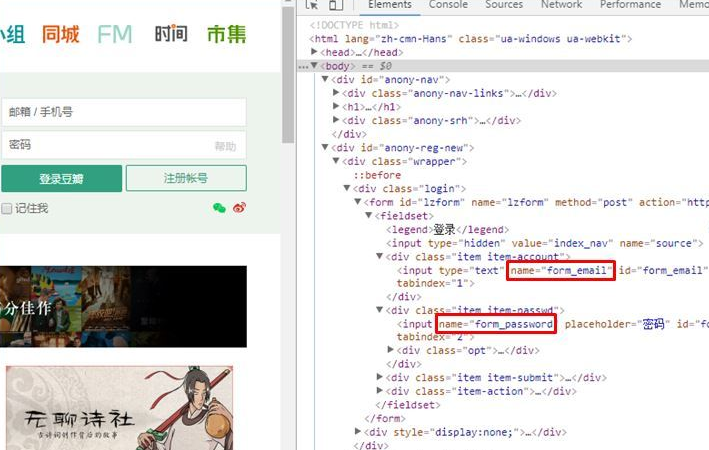
但要說明的是,兩個標簽的name名稱并不是固定的,上面查看的name名稱只是豆瓣網站定義的,不代表所有。其它的網站可能有會有不同的名稱,比如name="username", name="password"之類的。因此,針對不同網站的登錄,需要每次查看name是什么。
2. 通過fiddler抓包工具
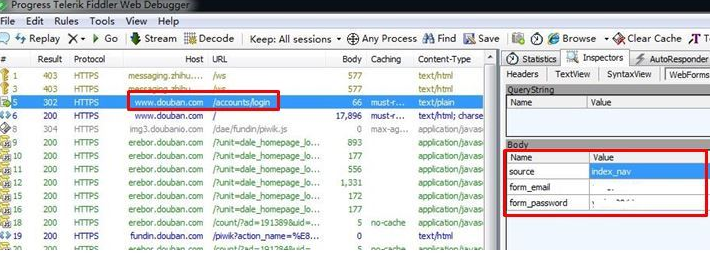
博主推薦使用fiddler工具,非常好用。爬蟲本身就是模擬瀏覽器工作,我們只需要知道瀏覽器是怎么工作的就可以了。
fiddler會幫助我們抓取瀏覽器POST請求的所有內容,這樣我們得到了瀏覽器POST的信息,把它填到爬蟲程序里模擬瀏覽器操作就OK了。另外,也可以通過fiddler抓到瀏覽器請求的headers,非常方便。
安裝fiddler的小伙伴們注意:fiddler證書問題的坑(無法抓取HTTPs包),可以通過Tools —> Options —>HTTPS里面打勾Decrypt HTTPS traffic修改證書來解決。否則會一直顯示抓取 Tunnel 信息包...
好了,完成了準備工作,我們直接上一段代碼理解下。
POST請求的使用
# coding: utf-8
import urllib.request
import urllib.error
import urllib.parse
# headers 信息,從fiddler上或你的瀏覽器上可復制下來
headers = {'Accept': 'text/html,application/xhtml+xml,
application/xml;q=0.9,image/webp,image/apng,
*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3;
Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko)Chrome/48.0
.2564.48 Safari/537.36'
}
# POST請求的信息,填寫你的用戶名和密碼
value = {'source': 'index_nav',
'form_password': 'your password',
'form_email': 'your username'
}
try:
data = urllib.parse.urlencode(value).encode('utf8')
response = urllib.request.Request(
'https://www.douban.com/', data=data, headers=headers)
html = urllib.request.urlopen(response)
result = html.read().decode('utf8')
print(result)
except urllib.error.URLError as e:
if hasattr(e, 'reason'):
print('錯誤原因是' + str(e.reason))
except urllib.error.HTTPError as e:
if hasattr(e, 'code'):
print('錯誤編碼是' + str(e.code))
else:
print('請求成功通過。')運行結果:
<!DOCTYPE HTML>
<html lang="zh-cmn-Hans" class="ua-windows ua-webkit">
<head>
<meta charset="UTF-8">
<meta name="description" content="提供圖書、電影、音樂唱片的
推薦、評論和價格比較,以及城市獨特的文化生活。">
.....
window.attachEvent('onload', _ga_init);
}
</script>
</body>
</html>注意:復制header的時候請去掉 這一項'Accept-Encoding':' gzip, deflate, 否則會提示decode的錯誤。
POST請求代碼分析
我們來分析一下上面的代碼,與urllib庫request的使用基本一致,urllib庫request的基本用法可參考上篇文章Python從零學爬蟲,這里多出了post的data參數和一些解析的內容,著重講解一下。
data = urllib.parse.urlencode(value).encode('utf8')這句的意思是利用了urllib庫的parse來對post內容解析,為什么要解析呢?
這是因為post內容需要進行一定的編碼格式處理后才能發送,而編碼的規則需要遵從RFC標準,百度了一下RFC定義,供大家參考:
Request ForComments(RFC),是一系列以編號排定的文件。文件收集了有關互聯網相關信息,以及UNIX和互聯網社區的軟件文件。目前RFC文件是由InternetSociety(ISOC)贊助發行。基本的互聯網通信協議都有在RFC文件內詳細說明。RFC文件還額外加入許多的論題在標準內,例如對于互聯網新開發的協議及發展中所有的記錄。因此幾乎所有的互聯網標準都有收錄在RFC文件之中。
而parse的urlencode方法是將一個字典或者有順序的二元素元組轉換成為URL的查詢字符串(說白了就是按照RFC標準轉換了一下格式)。然后再將轉換好的字符串按UTF-8的編碼轉換成為二進制格式才能使用。
注:以上是在Python3.x環境下完成,Python3.x中編碼解碼規則為 byte—>string—>byte的模式,其中byte—>string為解碼,string—>byte為編碼
代理IP
代理IP的使用
為什么要使用代理IP?因為各種反爬機制會檢測同一IP爬取網頁的頻率速度,如果速度過快,就會被認定為機器人封掉你的IP。但是速度過慢又會影響爬取的速度,因此,我們將使用代理IP取代我們自己的IP,這樣不斷更換新的IP地址就可以達到快速爬取網頁而降低被檢測為機器人的目的了。
同樣利用urllib的request就可以完成代理IP的使用,但是與之前用到的urlopen不同,我們需要自己創建訂制化的opener。什么意思呢?
urlopen就好像是opener的通用版本,當我們需要特殊功能(例如代理IP)的時候,urlopen滿足不了我們的需求,我們就不得不自己定義并創建特殊的opener了。
request里面正好有處理各種功能的處理器方法,如下:
ProxyHandler, UnknownHandler, HTTPHandler, HTTPDefaultErrorHandler, HTTPRedirectHandler, FTPHandler, FileHandler, HTTPErrorProcessor, DataHandler
我們要用的是第一個ProxyHandler來處理代理問題。
讓我們看一段代碼如何使用。
# coding:utf-8
import urllib.request
import urllib.error
import urllib.parse
# headers信息,從fiddler上或瀏覽器上可復制下來
headers = {'Accept': 'text/html,application/xhtml+xml,
application/xml;q=0.9,image/webp,image/apng,
*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3;
Win64;
x64) AppleWebKit/537.36 (KHTML,
like Gecko)Chrome/48.0.2564.48
Safari/537.36'
}
# POST請求的信息
value = {'source': 'index_nav',
'form_password': 'your password',
'form_email': 'your username'
}
# 代理IP信息為字典格式,key為'http',value為'代理ip:端口號'
proxy = {'http': '115.193.101.21:61234'}
try:
data = urllib.parse.urlencode(value).encode('utf8')
response = urllib.request.Request(
'https://www.douban.com/', data=data, headers=headers)
# 使用ProxyHandler方法生成處理器對象
proxy_handler = urllib.request.ProxyHandler(proxy)
# 創建代理IP的opener實例
opener = urllib.request.build_opener(proxy_handler)
# 將設置好的post信息和headers的response作為參數
html = opener.open(response)
result = html.read().decode('utf8')
print(result)
except urllib.error.URLError as e:
if hasattr(e, 'reason'):
print('錯誤原因是' + str(e.reason))
except urllib.error.HTTPError as e:
if hasattr(e, 'code'):
print('錯誤編碼是' + str(e.code))
else:
print('請求成功通過。')在上面post請求代碼的基礎上,用自己創建的opener替換urlopen即可完成代理IP的操作,代理ip可以到一些免費的代理IP網站上查找。
以上是“Python爬蟲中urllib庫有什么用”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





