溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python Numpy中數組array和矩陣matrix的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
NumPy的主要對象是同種元素的多維數組。這是一個所有的元素都是一種類型、通過一個正整數元組索引的元素表格(通常是元素是數字)。
在NumPy中維度(dimensions)叫做軸(axes),軸的個數叫做秩(rank,但是和線性代數中的秩不是一樣的,在用python求線代中的秩中,我們用numpy包中的linalg.matrix_rank方法計算矩陣的秩,例子如下)。
結果是:
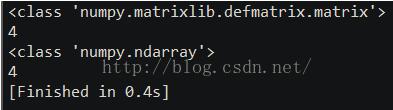
線性代數中秩的定義:設在矩陣A中有一個不等于0的r階子式D,且所有r+1階子式(如果存在的話)全等于0,那末D稱為矩陣A的最高階非零子式,數r稱為矩陣A的秩,記作R(A)。
numpy中數組和矩陣的區別:
matrix是array的分支,matrix和array在很多時候都是通用的,你用哪一個都一樣。但這時候,官方建議大家如果兩個可以通用,那就選擇array,因為array更靈活,速度更快,很多人把二維的array也翻譯成矩陣。
但是matrix的優勢就是相對簡單的運算符號,比如兩個矩陣相乘,就是用符號*,但是array相乘不能這么用,得用方法.dot()
array的優勢就是不僅僅表示二維,還能表示3、4、5...維,而且在大部分Python程序里,array也是更常用的。
現在我們討論numpy的多維數組
例如,在3D空間一個點的坐標[1, 2, 3]是一個秩為1的數組,因為它只有一個軸。那個軸長度為3.又例如,在以下例子中,數組的秩為2(它有兩個維度).第一個維度長度為2,第二個維度長度為3.
[[ 1., 0., 0.], [ 0., 1., 2.]]
NumPy的數組類被稱作ndarray。通常被稱作數組。注意numpy.array和標準Python庫類array.array并不相同,后者只處理一維數組和提供少量功能。更多重要ndarray對象屬性有:
ndarray.ndim
數組軸的個數,在python的世界中,軸的個數被稱作秩
ndarray.shape
數組的維度。這是一個指示數組在每個維度上大小的整數元組。例如一個n排m列的矩陣,它的shape屬性將是(2,3),這個元組的長度顯然是秩,即維度或者ndim屬性
ndarray.size
數組元素的總個數,等于shape屬性中元組元素的乘積。
ndarray.dtype
一個用來描述數組中元素類型的對象,可以通過創造或指定dtype使用標準Python類型。另外NumPy提供它自己的數據類型。
ndarray.itemsize
數組中每個元素的字節大小。例如,一個元素類型為float64的數組itemsiz屬性值為8(=64/8),又如,一個元素類型為complex32的數組item屬性為4(=32/8).
ndarray.data
包含實際數組元素的緩沖區,通常我們不需要使用這個屬性,因為我們總是通過索引來使用數組中的元素。
一個例子1
>>> from numpy import * >>> a = arange(15).reshape(3, 5) >>> a array([[ 0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9], [10, 11, 12, 13, 14]]) >>> a.shape (3, 5) >>> a.ndim 2 >>> a.dtype.name 'int32' >>> a.itemsize 4 >>> a.size 15 >>> type(a) numpy.ndarray >>> b = array([6, 7, 8]) >>> b array([6, 7, 8]) >>> type(b) numpy.ndarray
創建數組
有好幾種創建數組的方法。
例如,你可以使用array函數從常規的Python列表和元組創造數組。所創建的數組類型由原序列中的元素類型推導而來。
>>> from numpy import *
>>> a = array( [2,3,4] )
>>> a
array([2, 3, 4])
>>> a.dtype
dtype('int32')
>>> b = array([1.2, 3.5, 5.1])
>>> b.dtype
dtype('float64')一個常見的錯誤包括用多個數值參數調用array而不是提供一個由數值組成的列表作為一個參數。
>>> a = array(1,2,3,4) # WRONG >>> a = array([1,2,3,4]) # RIGHT
數組將序列包含序列轉化成二維的數組,序列包含序列包含序列轉化成三維數組等等。
>>> b = array( [ (1.5,2,3), (4,5,6) ] ) >>> b array([[ 1.5, 2. , 3. ], [ 4. , 5. , 6. ]])
數組類型可以在創建時顯示指定
>>> c = array( [ [1,2], [3,4] ], dtype=complex ) >>> c array([[ 1.+0.j, 2.+0.j], [ 3.+0.j, 4.+0.j]])
通常,數組的元素開始都是未知的,但是它的大小已知。因此,NumPy提供了一些使用占位符創建數組的函數。這最小化了擴展數組的需要和高昂的運算代價。
函數function創建一個全是0的數組,函數ones創建一個全1的數組,函數empty創建一個內容隨機并且依賴與內存狀態的數組。默認創建的數組類型(dtype)都是float64。
>>> zeros( (3,4) ) array([[0., 0., 0., 0.], [0., 0., 0., 0.], [0., 0., 0., 0.]]) >>> ones( (2,3,4), dtype=int16 ) # dtype can also be specified array([[[ 1, 1, 1, 1], [ 1, 1, 1, 1], [ 1, 1, 1, 1]], [[ 1, 1, 1, 1], [ 1, 1, 1, 1], [ 1, 1, 1, 1]]], dtype=int16) >>> empty( (2,3) ) array([[ 3.73603959e-262, 6.02658058e-154, 6.55490914e-260], [ 5.30498948e-313, 3.14673309e-307, 1.00000000e+000]])
為了創建一個數列,NumPy提供一個類似arange的函數返回數組而不是列表:
>>> arange( 10, 30, 5 ) array([10, 15, 20, 25]) >>> arange( 0, 2, 0.3 ) # it accepts float arguments array([ 0. , 0.3, 0.6, 0.9, 1.2, 1.5, 1.8])
當arange使用浮點數參數時,由于有限的浮點數精度,通常無法預測獲得的元素個數。因此,最好使用函數linspace去接收我們想要的元素個數來代替用range來指定步長。
其它函數array, zeros, zeros_like, ones, ones_like, empty, empty_like, arange, linspace, rand, randn, fromfunction, fromfile參考:NumPy示例
打印數組
當你打印一個數組,NumPy以類似嵌套列表的形式顯示它,但是呈以下布局:
最后的軸從左到右打印
次后的軸從頂向下打印
剩下的軸從頂向下打印,每個切片通過一個空行與下一個隔開
一維數組被打印成行,二維數組成矩陣,三維數組成矩陣列表。
>>> a = arange(6) # 1d array >>> print a [0 1 2 3 4 5] >>> >>> b = arange(12).reshape(4,3) # 2d array >>> print b [[ 0 1 2] [ 3 4 5] [ 6 7 8] [ 9 10 11]] >>> >>> c = arange(24).reshape(2,3,4) # 3d array >>> print c [[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] [[12 13 14 15] [16 17 18 19] [20 21 22 23]]]
查看形狀操作一節獲得有關reshape的更多細節
如果一個數組用來打印太大了,NumPy自動省略中間部分而只打印角落
>>> print arange(10000) [ 0 1 2 ..., 9997 9998 9999] >>> >>> print arange(10000).reshape(100,100) [[ 0 1 2 ..., 97 98 99] [ 100 101 102 ..., 197 198 199] [ 200 201 202 ..., 297 298 299] ..., [9700 9701 9702 ..., 9797 9798 9799] [9800 9801 9802 ..., 9897 9898 9899] [9900 9901 9902 ..., 9997 9998 9999]]
禁用NumPy的這種行為并強制打印整個數組,你可以設置printoptions參數來更改打印選項。
>>> set_printoptions(threshold='nan')
基本運算
數組的算術運算是按元素的。新的數組被創建并且被結果填充。
>>> a = array( [20,30,40,50] ) >>> b = arange( 4 ) >>> b array([0, 1, 2, 3]) >>> c = a-b >>> c array([20, 29, 38, 47]) >>> b**2 array([0, 1, 4, 9]) >>> 10*sin(a) array([ 9.12945251, -9.88031624, 7.4511316 , -2.62374854]) >>> a<35 array([True, True, False, False], dtype=bool)
不像許多矩陣語言,NumPy中的乘法運算符*指示按元素計算,矩陣乘法可以使用dot函數或創建矩陣對象實現(參見教程中的矩陣章節)
>>> A = array( [[1,1], ... [0,1]] ) >>> B = array( [[2,0], ... [3,4]] ) >>> A*B # elementwise product array([[2, 0], [0, 4]]) >>> dot(A,B) # matrix product array([[5, 4], [3, 4]])
有些操作符像+=和*=被用來更改已存在數組而不創建一個新的數組。
>>> a = ones((2,3), dtype=int) >>> b = random.random((2,3)) >>> a *= 3 >>> a array([[3, 3, 3], [3, 3, 3]]) >>> b += a >>> b array([[ 3.69092703, 3.8324276 , 3.0114541 ], [ 3.18679111, 3.3039349 , 3.37600289]]) >>> a += b # b is converted to integer type >>> a array([[6, 6, 6], [6, 6, 6]])
當運算的是不同類型的數組時,結果數組和更普遍和精確的已知(這種行為叫做upcast)。
>>> a = ones(3, dtype=int32) >>> b = linspace(0,pi,3) >>> b.dtype.name 'float64' >>> c = a+b >>> c array([ 1. , 2.57079633, 4.14159265]) >>> c.dtype.name 'float64' >>> d = exp(c*1j) >>> d array([ 0.54030231+0.84147098j, -0.84147098+0.54030231j, -0.54030231-0.84147098j]) >>> d.dtype.name 'complex128'
許多非數組運算,如計算數組所有元素之和,被作為ndarray類的方法實現
>>> a = random.random((2,3)) >>> a array([[ 0.6903007 , 0.39168346, 0.16524769], [ 0.48819875, 0.77188505, 0.94792155]]) >>> a.sum() 3.4552372100521485 >>> a.min() 0.16524768654743593 >>> a.max() 0.9479215542670073
這些運算默認應用到數組好像它就是一個數字組成的列表,無關數組的形狀。然而,指定axis參數你可以吧運算應用到數組指定的軸上:
>>> b = arange(12).reshape(3,4) >>> b array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) >>> >>> b.sum(axis=0) # sum of each column array([12, 15, 18, 21]) >>> >>> b.min(axis=1) # min of each row array([0, 4, 8]) >>> >>> b.cumsum(axis=1) # cumulative sum along each row array([[ 0, 1, 3, 6], [ 4, 9, 15, 22], [ 8, 17, 27, 38]])
通用函數(ufunc)
NumPy提供常見的數學函數如sin,cos和exp。在NumPy中,這些叫作“通用函數”(ufunc)。在NumPy里這些函數作用按數組的元素運算,產生一個數組作為輸出。
>>> B = arange(3) >>> B array([0, 1, 2]) >>> exp(B) array([ 1. , 2.71828183, 7.3890561 ]) >>> sqrt(B) array([ 0. , 1. , 1.41421356]) >>> C = array([2., -1., 4.]) >>> add(B, C) array([ 2., 0., 6.])
更多函數 all, alltrue, any, apply along axis, argmax, argmin, argsort, average, bincount, ceil, clip, conj, conjugate, corrcoef, cov, cross, cumprod, cumsum, diff, dot, floor, inner, inv, lexsort, max, maximum, mean, median, min, minimum, nonzero, outer, prod, re, round, sometrue, sort, std, sum, trace, transpose, var, vdot, vectorize, where 參見:NumPy示例
索引,切片和迭代
一維數組可以被索引、切片和迭代,就像列表和其它Python序列。
>>> a = arange(10)**3 >>> a array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729]) >>> a[2] 8 >>> a[2:5] array([ 8, 27, 64]) >>> a[:6:2] = -1000 # equivalent to a[0:6:2] = -1000; from start to position 6, exclusive, set every 2nd element to -1000 >>> a array([-1000, 1, -1000, 27, -1000, 125, 216, 343, 512, 729]) >>> a[ : :-1] # reversed a array([ 729, 512, 343, 216, 125, -1000, 27, -1000, 1, -1000]) >>> for i in a: ... print i**(1/3.), ... nan 1.0 nan 3.0 nan 5.0 6.0 7.0 8.0 9.0
多維數組可以每個軸有一個索引。這些索引由一個逗號分割的元組給出。
>>> def f(x,y): ... return 10*x+y ... >>> b = fromfunction(f,(5,4),dtype=int) >>> b array([[ 0, 1, 2, 3], [10, 11, 12, 13], [20, 21, 22, 23], [30, 31, 32, 33], [40, 41, 42, 43]]) >>> b[2,3] 23 >>> b[0:5, 1] # each row in the second column of b array([ 1, 11, 21, 31, 41]) >>> b[ : ,1] # equivalent to the previous example array([ 1, 11, 21, 31, 41]) >>> b[1:3, : ] # each column in the second and third row of b array([[10, 11, 12, 13], [20, 21, 22, 23]])
當少于軸數的索引被提供時,確失的索引被認為是整個切片:
>>> b[-1] # the last row. Equivalent to b[-1,:] array([40, 41, 42, 43])
b[i]中括號中的表達式被當作i和一系列:,來代表剩下的軸。NumPy也允許你使用“點”像b[i,...]。
點(…)代表許多產生一個完整的索引元組必要的分號。如果x是秩為5的數組(即它有5個軸),那么:
x[1,2,…] 等同于 x[1,2,:,:,:], x[…,3] 等同于 x[:,:,:,:,3] x[4,…,5,:] 等同 x[4,:,:,5,:]. >>> c = array( [ [[ 0, 1, 2], # a 3D array (two stacked 2D arrays) ... [ 10, 12, 13]], ... ... [[100,101,102], ... [110,112,113]] ] ) >>> c.shape (2, 2, 3) >>> c[1,...] # same as c[1,:,:] or c[1] array([[100, 101, 102], [110, 112, 113]]) >>> c[...,2] # same as c[:,:,2] array([[ 2, 13], [102, 113]])
迭代多維數組是就第一個軸而言的:2
>>> for row in b: ... print row ... [0 1 2 3] [10 11 12 13] [20 21 22 23] [30 31 32 33] [40 41 42 43]
然而,如果一個人想對每個數組中元素進行運算,我們可以使用flat屬性,該屬性是數組元素的一個迭代器:
>>> for element in b.flat: ... print element, ... 0 1 2 3 10 11 12 13 20 21 22 23 30 31 32 33 40 41 42 43
更多[], …, newaxis, ndenumerate, indices, index exp 參考NumPy示例
形狀操作
更改數組的形狀
一個數組的形狀由它每個軸上的元素個數給出:
>>> a = floor(10*random.random((3,4))) >>> a array([[ 7., 5., 9., 3.], [ 7., 2., 7., 8.], [ 6., 8., 3., 2.]]) >>> a.shape (3, 4)
一個數組的形狀可以被多種命令修改:
>>> a.ravel() # flatten the array array([ 7., 5., 9., 3., 7., 2., 7., 8., 6., 8., 3., 2.]) >>> a.shape = (6, 2) >>> a.transpose() array([[ 7., 9., 7., 7., 6., 3.], [ 5., 3., 2., 8., 8., 2.]])
由ravel()展平的數組元素的順序通常是“C風格”的,就是說,最右邊的索引變化得最快,所以元素a[0,0]之后是a[0,1]。如果數組被改變形狀(reshape)成其它形狀,數組仍然是“C風格”的。NumPy通常創建一個以這個順序保存數據的數組,所以ravel()將總是不需要復制它的參數3。但是如果數組是通過切片其它數組或有不同尋常的選項時,它可能需要被復制。函數reshape()和ravel()還可以被同過一些可選參數構建成FORTRAN風格的數組,即最左邊的索引變化最快。
reshape函數改變參數形狀并返回它,而resize函數改變數組自身。
>>> a array([[ 7., 5.], [ 9., 3.], [ 7., 2.], [ 7., 8.], [ 6., 8.], [ 3., 2.]]) >>> a.resize((2,6)) >>> a array([[ 7., 5., 9., 3., 7., 2.], [ 7., 8., 6., 8., 3., 2.]])
如果在改變形狀操作中一個維度被給做-1,其維度將自動被計算
更多 shape, reshape, resize, ravel 參考NumPy示例
組合(stack)不同的數組
幾種方法可以沿不同軸將數組堆疊在一起:
>>> a = floor(10*random.random((2,2))) >>> a array([[ 1., 1.], [ 5., 8.]]) >>> b = floor(10*random.random((2,2))) >>> b array([[ 3., 3.], [ 6., 0.]]) >>> vstack((a,b)) array([[ 1., 1.], [ 5., 8.], [ 3., 3.], [ 6., 0.]]) >>> hstack((a,b)) array([[ 1., 1., 3., 3.], [ 5., 8., 6., 0.]])
函數column_stack以列將一維數組合成二維數組,它等同與vstack對一維數組。
>>> column_stack((a,b)) # With 2D arrays array([[ 1., 1., 3., 3.], [ 5., 8., 6., 0.]]) >>> a=array([4.,2.]) >>> b=array([2.,8.]) >>> a[:,newaxis] # This allows to have a 2D columns vector array([[ 4.], [ 2.]]) >>> column_stack((a[:,newaxis],b[:,newaxis])) array([[ 4., 2.], [ 2., 8.]]) >>> vstack((a[:,newaxis],b[:,newaxis])) # The behavior of vstack is different array([[ 4.], [ 2.], [ 2.], [ 8.]])
row_stack函數,另一方面,將一維數組以行組合成二維數組。
對那些維度比二維更高的數組,hstack沿著第二個軸組合,vstack沿著第一個軸組合,concatenate允許可選參數給出組合時沿著的軸。
Note
在復雜情況下,r_[]和c_[]對創建沿著一個方向組合的數很有用,它們允許范圍符號(“:”):
>>> r_[1:4,0,4] array([1, 2, 3, 0, 4])
當使用數組作為參數時,r_和c_的默認行為和vstack和hstack很像,但是允許可選的參數給出組合所沿著的軸的代號。
更多函數hstack , vstack, column_stack , row_stack , concatenate , c_ , r_ 參見NumPy示例.
將一個數組分割(split)成幾個小數組
使用hsplit你能將數組沿著它的水平軸分割,或者指定返回相同形狀數組的個數,或者指定在哪些列后發生分割:
>>> a = floor(10*random.random((2,12))) >>> a array([[ 8., 8., 3., 9., 0., 4., 3., 0., 0., 6., 4., 4.], [ 0., 3., 2., 9., 6., 0., 4., 5., 7., 5., 1., 4.]]) >>> hsplit(a,3) # Split a into 3 [array([[ 8., 8., 3., 9.], [ 0., 3., 2., 9.]]), array([[ 0., 4., 3., 0.], [ 6., 0., 4., 5.]]), array([[ 0., 6., 4., 4.], [ 7., 5., 1., 4.]])] >>> hsplit(a,(3,4)) # Split a after the third and the fourth column [array([[ 8., 8., 3.], [ 0., 3., 2.]]), array([[ 9.], [ 9.]]), array([[ 0., 4., 3., 0., 0., 6., 4., 4.], [ 6., 0., 4., 5., 7., 5., 1., 4.]])]
vsplit沿著縱向的軸分割,array split允許指定沿哪個軸分割。
復制和視圖
當運算和處理數組時,它們的數據有時被拷貝到新的數組有時不是。這通常是新手的困惑之源。這有三種情況:
完全不拷貝
簡單的賦值不拷貝數組對象或它們的數據。
>>> a = arange(12) >>> b = a # no new object is created >>> b is a # a and b are two names for the same ndarray object True >>> b.shape = 3,4 # changes the shape of a >>> a.shape (3, 4)
Python 傳遞不定對象作為參考4,所以函數調用不拷貝數組。
>>> def f(x): ... print id(x) ... >>> id(a) # id is a unique identifier of an object 148293216 >>> f(a) 148293216
視圖(view)和淺復制
不同的數組對象分享同一個數據。視圖方法創造一個新的數組對象指向同一數據。
>>> c = a.view() >>> c is a False >>> c.base is a # c is a view of the data owned by a True >>> c.flags.owndata False >>> >>> c.shape = 2,6 # a's shape doesn't change >>> a.shape (3, 4) >>> c[0,4] = 1234 # a's data changes >>> a array([[ 0, 1, 2, 3], [1234, 5, 6, 7], [ 8, 9, 10, 11]])
切片數組返回它的一個視圖:
>>> s = a[ : , 1:3] # spaces added for clarity; could also be written "s = a[:,1:3]" >>> s[:] = 10 # s[:] is a view of s. Note the difference between s=10 and s[:]=10 >>> a array([[ 0, 10, 10, 3], [1234, 10, 10, 7], [ 8, 10, 10, 11]])
深復制
這個復制方法完全復制數組和它的數據。
>>> d = a.copy() # a new array object with new data is created >>> d is a False >>> d.base is a # d doesn't share anything with a False >>> d[0,0] = 9999 >>> a array([[ 0, 10, 10, 3], [1234, 10, 10, 7], [ 8, 10, 10, 11]])
函數和方法(method)總覽
這是個NumPy函數和方法分類排列目錄。這些名字鏈接到NumPy示例,你可以看到這些函數起作用。5
創建數組
arange, array, copy, empty, empty_like, eye, fromfile, fromfunction, identity, linspace, logspace, mgrid, ogrid, ones, ones_like, r , zeros, zeros_like
轉化
astype, atleast 1d, atleast 2d, atleast 3d, mat
操作
array split, column stack, concatenate, diagonal, dsplit, dstack, hsplit, hstack, item, newaxis, ravel, repeat, reshape, resize, squeeze, swapaxes, take, transpose, vsplit, vstack
詢問
all, any, nonzero, where
排序
argmax, argmin, argsort, max, min, ptp, searchsorted, sort
運算
choose, compress, cumprod, cumsum, inner, fill, imag, prod, put, putmask, real, sum
基本統計
cov, mean, std, var
基本線性代數
cross, dot, outer, svd, vdot
進階
廣播法則(rule)
廣播法則能使通用函數有意義地處理不具有相同形狀的輸入。
廣播第一法則是,如果所有的輸入數組維度不都相同,一個“1”將被重復地添加在維度較小的數組上直至所有的數組擁有一樣的維度。
廣播第二法則確定長度為1的數組沿著特殊的方向表現地好像它有沿著那個方向最大形狀的大小。對數組來說,沿著那個維度的數組元素的值理應相同。
應用廣播法則之后,所有數組的大小必須匹配。更多細節可以從這個文檔找到。
花哨的索引和索引技巧
NumPy比普通Python序列提供更多的索引功能。除了索引整數和切片,正如我們之前看到的,數組可以被整數數組和布爾數組索引。
通過數組索引
>>> a = arange(12)**2 # the first 12 square numbers >>> i = array( [ 1,1,3,8,5 ] ) # an array of indices >>> a[i] # the elements of a at the positions i array([ 1, 1, 9, 64, 25]) >>> >>> j = array( [ [ 3, 4], [ 9, 7 ] ] ) # a bidimensional array of indices >>> a[j] # the same shape as j array([[ 9, 16], [81, 49]])
當被索引數組a是多維的時,每一個唯一的索引數列指向a的第一維[^5]。以下示例通過將圖片標簽用調色版轉換成色彩圖像展示了這種行為。
>>> palette = array( [ [0,0,0], # black ... [255,0,0], # red ... [0,255,0], # green ... [0,0,255], # blue ... [255,255,255] ] ) # white >>> image = array( [ [ 0, 1, 2, 0 ], # each value corresponds to a color in the palette ... [ 0, 3, 4, 0 ] ] ) >>> palette[image] # the (2,4,3) color image array([[[ 0, 0, 0], [255, 0, 0], [ 0, 255, 0], [ 0, 0, 0]], [[ 0, 0, 0], [ 0, 0, 255], [255, 255, 255], [ 0, 0, 0]]])
我們也可以給出不不止一維的索引,每一維的索引數組必須有相同的形狀。
>>> a = arange(12).reshape(3,4) >>> a array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) >>> i = array( [ [0,1], # indices for the first dim of a ... [1,2] ] ) >>> j = array( [ [2,1], # indices for the second dim ... [3,3] ] ) >>> >>> a[i,j] # i and j must have equal shape array([[ 2, 5], [ 7, 11]]) >>> >>> a[i,2] array([[ 2, 6], [ 6, 10]]) >>> >>> a[:,j] # i.e., a[ : , j] array([[[ 2, 1], [ 3, 3]], [[ 6, 5], [ 7, 7]], [[10, 9], [11, 11]]])
自然,我們可以把i和j放到序列中(比如說列表)然后通過list索引。
>>> l = [i,j] >>> a[l] # equivalent to a[i,j] array([[ 2, 5], [ 7, 11]])
然而,我們不能把i和j放在一個數組中,因為這個數組將被解釋成索引a的第一維。
>>> s = array( [i,j] ) >>> a[s] # not what we want --------------------------------------------------------------------------- IndexError Traceback (most recent call last) in () ----> 1 a[s] IndexError: index (3) out of range (0<=index<2) in dimension 0 >>> >>> a[tuple(s)] # same as a[i,j] array([[ 2, 5], [ 7, 11]])
另一個常用的數組索引用法是搜索時間序列最大值6。
>>> time = linspace(20, 145, 5) # time scale >>> data = sin(arange(20)).reshape(5,4) # 4 time-dependent series >>> time array([ 20. , 51.25, 82.5 , 113.75, 145. ]) >>> data array([[ 0. , 0.84147098, 0.90929743, 0.14112001], [-0.7568025 , -0.95892427, -0.2794155 , 0.6569866 ], [ 0.98935825, 0.41211849, -0.54402111, -0.99999021], [-0.53657292, 0.42016704, 0.99060736, 0.65028784], [-0.28790332, -0.96139749, -0.75098725, 0.14987721]]) >>> >>> ind = data.argmax(axis=0) # index of the maxima for each series >>> ind array([2, 0, 3, 1]) >>> >>> time_max = time[ ind] # times corresponding to the maxima >>> >>> data_max = data[ind, xrange(data.shape[1])] # => data[ind[0],0], data[ind[1],1]... >>> >>> time_max array([ 82.5 , 20. , 113.75, 51.25]) >>> data_max array([ 0.98935825, 0.84147098, 0.99060736, 0.6569866 ]) >>> >>> all(data_max == data.max(axis=0)) True
你也可以使用數組索引作為目標來賦值:
>>> a = arange(5) >>> a array([0, 1, 2, 3, 4]) >>> a[[1,3,4]] = 0 >>> a array([0, 0, 2, 0, 0])
然而,當一個索引列表包含重復時,賦值被多次完成,保留最后的值:
>>> a = arange(5) >>> a[[0,0,2]]=[1,2,3] >>> a array([2, 1, 3, 3, 4])
這足夠合理,但是小心如果你想用Python的+=結構,可能結果并非你所期望:
>>> a = arange(5) >>> a[[0,0,2]]+=1 >>> a array([1, 1, 3, 3, 4])
即使0在索引列表中出現兩次,索引為0的元素僅僅增加一次。這是因為Python要求a+=1和a=a+1等同。
通過布爾數組索引
當我們使用整數數組索引數組時,我們提供一個索引列表去選擇。通過布爾數組索引的方法是不同的我們顯式地選擇數組中我們想要和不想要的元素。
我們能想到的使用布爾數組的索引最自然方式就是使用和原數組一樣形狀的布爾數組。
>>> a = arange(12).reshape(3,4) >>> b = a > 4 >>> b # b is a boolean with a's shape array([[False, False, False, False], [False, True, True, True], [True, True, True, True]], dtype=bool) >>> a[b] # 1d array with the selected elements array([ 5, 6, 7, 8, 9, 10, 11])
這個屬性在賦值時非常有用:
>>> a[b] = 0 # All elements of 'a' higher than 4 become 0 >>> a array([[0, 1, 2, 3], [4, 0, 0, 0], [0, 0, 0, 0]])
你可以參考曼德博集合示例看看如何使用布爾索引來生成曼德博集合的圖像。
第二種通過布爾來索引的方法更近似于整數索引;對數組的每個維度我們給一個一維布爾數組來選擇我們想要的切片。
>>> a = arange(12).reshape(3,4) >>> b1 = array([False,True,True]) # first dim selection >>> b2 = array([True,False,True,False]) # second dim selection >>> >>> a[b1,:] # selecting rows array([[ 4, 5, 6, 7], [ 8, 9, 10, 11]]) >>> >>> a[b1] # same thing array([[ 4, 5, 6, 7], [ 8, 9, 10, 11]]) >>> >>> a[:,b2] # selecting columns array([[ 0, 2], [ 4, 6], [ 8, 10]]) >>> >>> a[b1,b2] # a weird thing to do array([ 4, 10])
注意一維數組的長度必須和你想要切片的維度或軸的長度一致,在之前的例子中,b1是一個秩為1長度為三的數組(a的行數),b2(長度為4)與a的第二秩(列)相一致。7
ix_()函數
ix_函數可以為了獲得多元組的結果而用來結合不同向量。例如,如果你想要用所有向量a、b和c元素組成的三元組來計算a+b*c:
>>> a = array([2,3,4,5]) >>> b = array([8,5,4]) >>> c = array([5,4,6,8,3]) >>> ax,bx,cx = ix_(a,b,c) >>> ax array([[[2]], [[3]], [[4]], [[5]]]) >>> bx array([[[8], [5], [4]]]) >>> cx array([[[5, 4, 6, 8, 3]]]) >>> ax.shape, bx.shape, cx.shape ((4, 1, 1), (1, 3, 1), (1, 1, 5)) >>> result = ax+bx*cx >>> result array([[[42, 34, 50, 66, 26], [27, 22, 32, 42, 17], [22, 18, 26, 34, 14]], [[43, 35, 51, 67, 27], [28, 23, 33, 43, 18], [23, 19, 27, 35, 15]], [[44, 36, 52, 68, 28], [29, 24, 34, 44, 19], [24, 20, 28, 36, 16]], [[45, 37, 53, 69, 29], [30, 25, 35, 45, 20], [25, 21, 29, 37, 17]]]) >>> result[3,2,4] 17 >>> a[3]+b[2]*c[4] 17
你也可以實行如下簡化:
def ufunc_reduce(ufct, *vectors): vs = ix_(*vectors) r = ufct.identity for v in vs: r = ufct(r,v) return r
然后這樣使用它:
>>> ufunc_reduce(add,a,b,c) array([[[15, 14, 16, 18, 13], [12, 11, 13, 15, 10], [11, 10, 12, 14, 9]], [[16, 15, 17, 19, 14], [13, 12, 14, 16, 11], [12, 11, 13, 15, 10]], [[17, 16, 18, 20, 15], [14, 13, 15, 17, 12], [13, 12, 14, 16, 11]], [[18, 17, 19, 21, 16], [15, 14, 16, 18, 13], [14, 13, 15, 17, 12]]])
這個reduce與ufunc.reduce(比如說add.reduce)相比的優勢在于它利用了廣播法則,避免了創建一個輸出大小乘以向量個數的參數數組。8
用字符串索引
參見RecordArray。
線性代數
繼續前進,基本線性代數包含在這里。
簡單數組運算
參考numpy文件夾中的linalg.py獲得更多信息
>>> from numpy import * >>> from numpy.linalg import * >>> a = array([[1.0, 2.0], [3.0, 4.0]]) >>> print a [[ 1. 2.] [ 3. 4.]] >>> a.transpose() array([[ 1., 3.], [ 2., 4.]]) >>> inv(a) array([[-2. , 1. ], [ 1.5, -0.5]]) >>> u = eye(2) # unit 2x2 matrix; "eye" represents "I" >>> u array([[ 1., 0.], [ 0., 1.]]) >>> j = array([[0.0, -1.0], [1.0, 0.0]]) >>> dot (j, j) # matrix product array([[-1., 0.], [ 0., -1.]]) >>> trace(u) # trace 2.0 >>> y = array([[5.], [7.]]) >>> solve(a, y) array([[-3.], [ 4.]]) >>> eig(j) (array([ 0.+1.j, 0.-1.j]), array([[ 0.70710678+0.j, 0.70710678+0.j], [ 0.00000000-0.70710678j, 0.00000000+0.70710678j]])) Parameters: square matrix Returns The eigenvalues, each repeated according to its multiplicity. The normalized (unit "length") eigenvectors, such that the column ``v[:,i]`` is the eigenvector corresponding to the eigenvalue ``w[i]`` .
矩陣類
這是一個關于矩陣類的簡短介紹。
>>> A = matrix('1.0 2.0; 3.0 4.0')
>>> A
[[ 1. 2.]
[ 3. 4.]]
>>> type(A) # file where class is defined
>>> A.T # transpose
[[ 1. 3.]
[ 2. 4.]]
>>> X = matrix('5.0 7.0')
>>> Y = X.T
>>> Y
[[5.]
[7.]]
>>> print A*Y # matrix multiplication
[[19.]
[43.]]
>>> print A.I # inverse
[[-2. 1. ]
[ 1.5 -0.5]]
>>> solve(A, Y) # solving linear equation
matrix([[-3.],
[ 4.]])索引:比較矩陣和二維數組
注意NumPy中數組和矩陣有些重要的區別。NumPy提供了兩個基本的對象:一個N維數組對象和一個通用函數對象。其它對象都是建構在它們之上的。特別的,矩陣是繼承自NumPy數組對象的二維數組對象。對數組和矩陣,索引都必須包含合適的一個或多個這些組合:整數標量、省略號(ellipses)、整數列表;布爾值,整數或布爾值構成的元組,和一個一維整數或布爾值數組。矩陣可以被用作矩陣的索引,但是通常需要數組、列表或者其它形式來完成這個任務。
像平常在Python中一樣,索引是從0開始的。傳統上我們用矩形的行和列表示一個二維數組或矩陣,其中沿著0軸的方向被穿過的稱作行,沿著1軸的方向被穿過的是列。9
讓我們創建數組和矩陣用來切片:
>>> A = arange(12) >>> A array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]) >>> A.shape = (3,4) >>> M = mat(A.copy()) >>> print type(A)," ",type(M) >>> print A [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] >>> print M [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]]
現在,讓我們簡單的切幾片。基本的切片使用切片對象或整數。例如,A[:]和M[:]的求值將表現得和Python索引很相似。然而要注意很重要的一點就是NumPy切片數組不創建數據的副本;切片提供統一數據的視圖。
>>> print A[:]; print A[:].shape [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] (3, 4) >>> print M[:]; print M[:].shape [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] (3, 4)
現在有些和Python索引不同的了:你可以同時使用逗號分割索引來沿著多個軸索引。
>>> print A[:,1]; print A[:,1].shape [1 5 9] (3,) >>> print M[:,1]; print M[:,1].shape [[1] [5] [9]] (3, 1)
注意最后兩個結果的不同。對二維數組使用一個冒號產生一個一維數組,然而矩陣產生了一個二維矩陣。10例如,一個M[2,:]切片產生了一個形狀為(1,4)的矩陣,相比之下,一個數組的切片總是產生一個最低可能維度11的數組。例如,如果C是一個三維數組,C[...,1]產生一個二維的數組而C[1,:,1]產生一個一維數組。從這時開始,如果相應的矩陣切片結果是相同的話,我們將只展示數組切片的結果。
假如我們想要一個數組的第一列和第三列,一種方法是使用列表切片:
>>> A[:,[1,3]] array([[ 1, 3], [ 5, 7], [ 9, 11]])
稍微復雜點的方法是使用take()方法(method):
>>> A[:,].take([1,3],axis=1) array([[ 1, 3], [ 5, 7], [ 9, 11]])
如果我們想跳過第一行,我們可以這樣:
>>> A[1:,].take([1,3],axis=1) array([[ 5, 7], [ 9, 11]])
或者我們僅僅使用A[1:,[1,3]]。還有一種方法是通過矩陣向量積(叉積)。
>>> A[ix_((1,2),(1,3))] array([[ 5, 7], [ 9, 11]])
為了讀者的方便,在次寫下之前的矩陣:
>>> A[ix_((1,2),(1,3))] array([[ 5, 7], [ 9, 11]])
現在讓我們做些更復雜的。比如說我們想要保留第一行大于1的列。一種方法是創建布爾索引:
>>> A[0,:]>1 array([False, False, True, True], dtype=bool) >>> A[:,A[0,:]>1] array([[ 2, 3], [ 6, 7], [10, 11]])
就是我們想要的!但是索引矩陣沒這么方便。
>>> M[0,:]>1 matrix([[False, False, True, True]], dtype=bool) >>> M[:,M[0,:]>1] matrix([[2, 3]])
這個過程的問題是用“矩陣切片”來切片產生一個矩陣12,但是矩陣有個方便的A屬性,它的值是數組呈現的。所以我們僅僅做以下替代:
>>> M[:,M.A[0,:]>1] matrix([[ 2, 3], [ 6, 7], [10, 11]])
如果我們想要在矩陣兩個方向有條件地切片,我們必須稍微調整策略,代之以:
>>> A[A[:,0]>2,A[0,:]>1] array([ 6, 11]) >>> M[M.A[:,0]>2,M.A[0,:]>1] matrix([[ 6, 11]])
我們需要使用向量積ix_:
>>> A[ix_(A[:,0]>2,A[0,:]>1)] array([[ 6, 7], [10, 11]]) >>> M[ix_(M.A[:,0]>2,M.A[0,:]>1)] matrix([[ 6, 7], [10, 11]])
技巧和提示
下面我們給出簡短和有用的提示。
“自動”改變形狀
更改數組的維度,你可以省略一個尺寸,它將被自動推導出來。
>>> a = arange(30) >>> a.shape = 2,-1,3 # -1 means "whatever is needed" >>> a.shape (2, 5, 3) >>> a array([[[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8], [ 9, 10, 11], [12, 13, 14]], [[15, 16, 17], [18, 19, 20], [21, 22, 23], [24, 25, 26], [27, 28, 29]]])
向量組合(stacking)
我們如何用兩個相同尺寸的行向量列表構建一個二維數組?在MATLAB中這非常簡單:如果x和y是兩個相同長度的向量,你僅僅需要做m=[x;y]。在NumPy中這個過程通過函數column_stack、dstack、hstack和vstack來完成,取決于你想要在那個維度上組合。例如:
x = arange(0,10,2) # x=([0,2,4,6,8]) y = arange(5) # y=([0,1,2,3,4]) m = vstack([x,y]) # m=([[0,2,4,6,8], # [0,1,2,3,4]]) xy = hstack([x,y]) # xy =([0,2,4,6,8,0,1,2,3,4])
二維以上這些函數背后的邏輯會很奇怪。
參考寫個Matlab用戶的NumPy指南并且在這里添加你的新發現: )
直方圖(histogram)
NumPy中histogram函數應用到一個數組返回一對變量:直方圖數組和箱式向量。注意:matplotlib也有一個用來建立直方圖的函數(叫作hist,正如matlab中一樣)與NumPy中的不同。主要的差別是pylab.hist自動繪制直方圖,而numpy.histogram僅僅產生數據。
import numpy import pylab # Build a vector of 10000 normal deviates with variance 0.5^2 and mean 2 mu, sigma = 2, 0.5 v = numpy.random.normal(mu,sigma,10000) # Plot a normalized histogram with 50 bins pylab.hist(v, bins=50, normed=1) # matplotlib version (plot) pylab.show() # Compute the histogram with numpy and then plot it (n, bins) = numpy.histogram(v, bins=50, normed=True) # NumPy version (no plot) pylab.plot(.5*(bins[1:]+bins[:-1]), n) pylab.show()
關于“Python Numpy中數組array和矩陣matrix的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





