溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Pandas如何實現數據類型轉換的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
前言
Pandas是Python當中重要的數據分析工具,利用Pandas進行數據分析時,確保使用正確的數據類型是非常重要的,否則可能會導致一些不可預知的錯誤發生。
Pandas 的數據類型:數據類型本質上是編程語言用來理解如何存儲和操作數據的內部結構。例如,一個程序需要理解你可以將兩個數字加起來,比如 5 + 10 得到 15。或者,如果是兩個字符串,比如「cat」和「hat」,你可以將它們連接(加)起來得到「cathat」。尚學堂?百戰程序員陳老師指出有關 Pandas 數據類型的一個可能令人困惑的地方是,Pandas、Python 和 numpy 的數據類型之間有一些重疊。
大多數情況下,你不必擔心是否應該明確地將熊貓類型強制轉換為對應的 NumPy 類型。一般來說使用 Pandas 的默認 int64 和 float64 就可以。我列出此表的唯一原因是,有時你可能會在代碼行間或自己的分析過程中看到 Numpy 的類型。
數據類型是在你遇到錯誤或意外結果之前并不會關心的事情之一。不過當你將新數據加載到 Pandas 進行進一步分析時,這也是你應該檢查的第一件事情。
筆者使用Pandas已經有一段時間了,但是還是會在一些小問題上犯錯誤,追根溯源發現在對數據進行操作時某些特征列并不是Pandas所能處理的類型。因此本文將討論一些小技巧如何將Python的基本數據類型轉化為Pandas所能處理的數據類型。
Pandas、Numpy、Python各自支持的數據類型
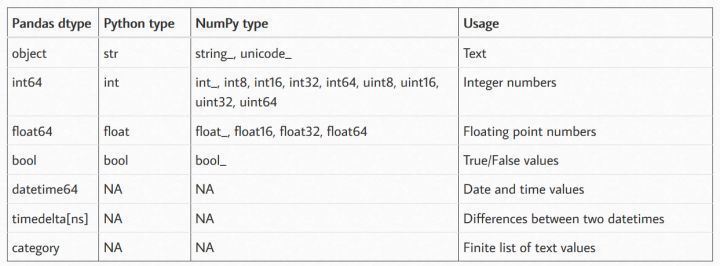
從上述表格中可以看出Pandas支持的數據類型最為豐富,在某種情形下Numpy的數據類型可以和Pandas的數據類型相互轉化,畢竟Pandas庫是在Numpy的基礎之上開發的的。
引入實際數據進行分析
數據類型是你平常可能不太關心,直到得到了錯誤的結果才映像深刻的東西,因此在這里引入一個實際數據分析的例子來加深理解。
import numpy as np
import pandas as pd
data = pd.read_csv('data.csv', encoding='gbk') #因為數據中含有中文數據
data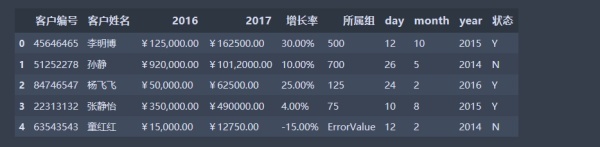
數據加載完畢,如果現在想要在該數據上進行一些操作,比如把數據列2016、2017對應項相加。
data['2016'] + data['2017'] #想當然的做法
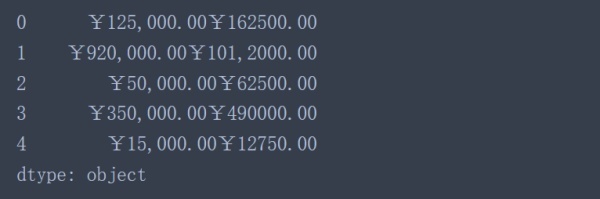
從結果來看并沒有像想象中那樣數值對應相加,這是因為在Pandas中object類型相加等價于Python中的字符串相加。
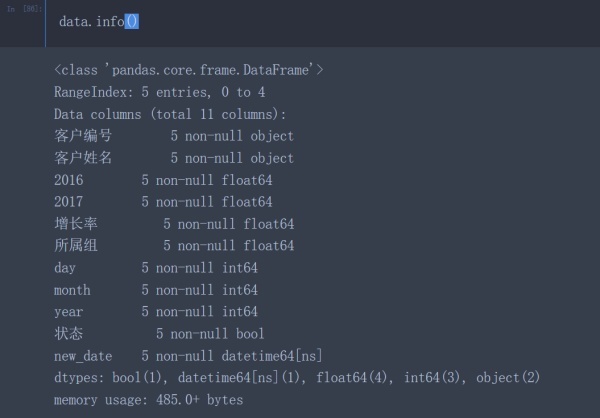
data.info() #在對數據進行處理之前應該先查看加載數據的相關信息
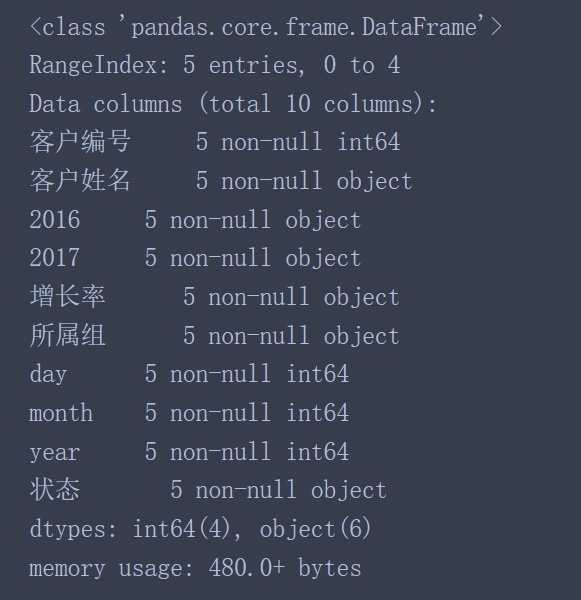
在看到加載數據的相關信息后可以發現如下幾個問題:
客戶編號的數據類型是int64而不是object類型
2016、2017列的數據類型是object而不是數值類型(int64、float64)
增長率、所屬組的數據類型應該為數值類型而不是object類型
year、month、day的數據類型應該為datetime64類型而不是object類型
Pandas中進行數據類型轉換有三種基本方法:
使用astype()函數進行強制類型轉換
自定義函數進行數據類型轉換
使用Pandas提供的函數如to_numeric()、to_datetime()
使用astype()函數進行類型轉換
對數據列進行數據類型轉換最簡單的方法就是使用astype()函數
data['客戶編號'].astype('object')
data['客戶編號'] = data['客戶編號'].astype('object') #對原始數據進行轉換并覆蓋原始數據列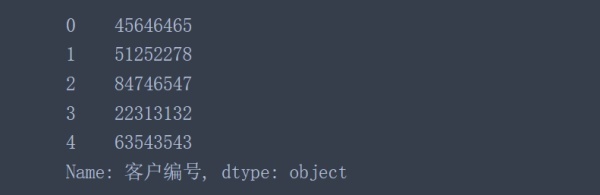
上面的結果看起來很不錯,接下來給出幾個astype()函數作用于列數據但失效的例子
data['2017'].astype('float')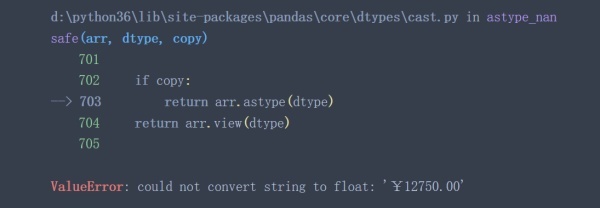
data['所屬組'].astype('int')
從上面兩個例子可以看出,當待轉換列中含有不能轉換的特殊值時(例子中¥,ErrorValue等)astype()函數將失效。有些時候astype()函數執行成功了也并不一定代表著執行結果符合預期(神坑!)
data['狀態'].astype('bool')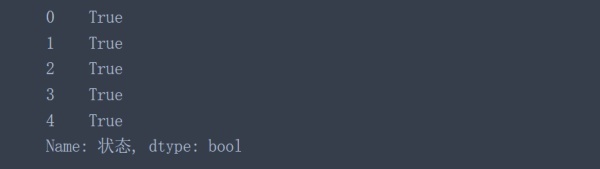
乍一看,結果看起來不錯,但仔細觀察后,會發現一個大問題。那就是所有的值都被替換為True了,但是該列中包含好幾個N標志,所以astype()函數在該列也是失效的。
總結一下astype()函數有效的情形:
數據列中的每一個單位都能簡單的解釋為數字(2, 2.12等)
數據列中的每一個單位都是數值類型且向字符串object類型轉換
如果數據中含有缺失值、特殊字符astype()函數可能失效。
使用自定義函數進行數據類型轉換
該方法特別適用于待轉換數據列的數據較為復雜的情形,可以通過構建一個函數應用于數據列的每一個數據,并將其轉換為適合的數據類型。
對于上述數據中的貨幣,需要將它轉換為float類型,因此可以寫一個轉換函數:
def convert_currency(value):
"""
轉換字符串數字為float類型
- 移除 ¥ ,
- 轉化為float類型
"""
new_value = value.replace(',', '').replace('¥', '')
return np.float(new_value)現在可以使用Pandas的apply函數通過covert_currency函數應用于2016列中的所有數據中。
data['2016'].apply(convert_currency)
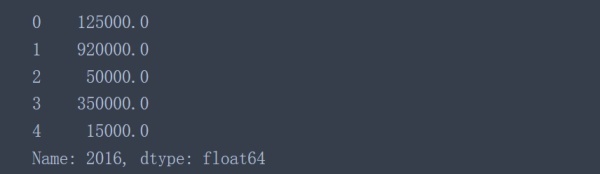
該列所有的數據都轉換成對應的數值類型了,因此可以對該列數據進行常見的數學操作了。如果利用lambda表達式改寫一下代碼,可能會比較簡潔但是對新手不太友好。
data['2016'].apply(lambda x: x.replace('¥', '').replace(',', '')).astype('float')當函數需要重復應用于多個列時,個人推薦使用第一種方法,先定義函數還有一個好處就是可以搭配read_csv()函數使用(后面介紹)。
#2016、2017列完整的轉換代碼 data['2016'] = data['2016'].apply(convert_currency) data['2017'] = data['2017'].apply(convert_currency)
同樣的方法運用于增長率,首先構建自定義函數
def convert_percent(value):
"""
轉換字符串百分數為float類型小數
- 移除 %
- 除以100轉換為小數
"""
new_value = value.replace('%', '')
return float(new_value) / 100使用Pandas的apply函數通過covert_percent函數應用于增長率列中的所有數據中。
data['增長率'].apply(convert_percent)
使用lambda表達式:
data['增長率'].apply(lambda x: x.replace('%', '')).astype('float') / 100結果都相同:
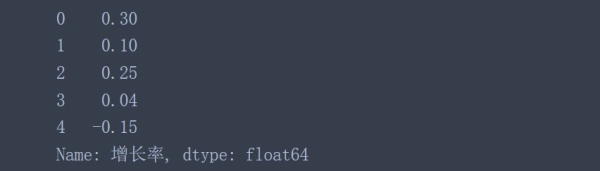
為了轉換狀態列,可以使用Numpy中的where函數,把值為Y的映射成True,其他值全部映射成False。
data['狀態'] = np.where(data['狀態'] == 'Y', True, False)
同樣的你也可以使用自定義函數或者使用lambda表達式,這些方法都可以完美的解決這個問題,這里只是多提供一種思路。
利用Pandas的一些輔助函數進行類型轉換
Pandas的astype()函數和復雜的自定函數之間有一個中間段,那就是Pandas的一些輔助函數。這些輔助函數對于某些特定數據類型的轉換非常有用(如to_numeric()、to_datetime())。所屬組數據列中包含一個非數值,用astype()轉換出現了錯誤,然而用to_numeric()函數處理就優雅很多。
pd.to_numeric(data['所屬組'], errors='coerce').fillna(0)
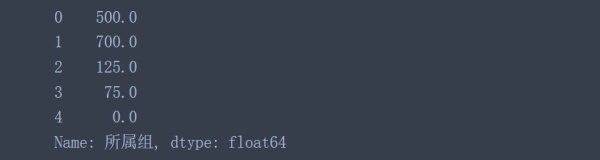
可以看到,非數值被替換成0.0了,當然這個填充值是可以選擇的,具體文檔見
pandas.to_numeric - pandas 0.22.0 documentation
Pandas中的to_datetime()函數可以把單獨的year、month、day三列合并成一個單獨的時間戳。
pd.to_datetime(data[['day', 'month', 'year']])
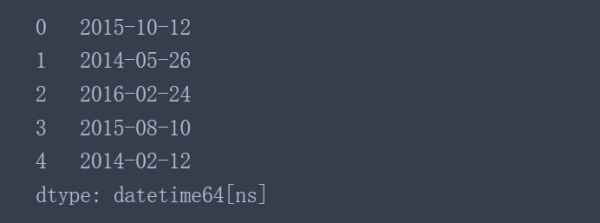
完成數據列的替換
data['new_date'] = pd.to_datetime(data[['day', 'month', 'year']]) #新產生的一列數據 data['所屬組'] = pd.to_numeric(data['所屬組'], errors='coerce').fillna(0)
到這里所有的數據列都轉換完畢,最終的數據顯示:
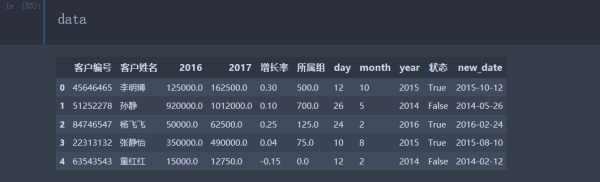
在讀取數據時就對數據類型進行轉換,一步到位
data2 = pd.read_csv("data.csv",
converters={
'客戶編號': str,
'2016': convert_currency,
'2017': convert_currency,
'增長率': convert_percent,
'所屬組': lambda x: pd.to_numeric(x, errors='coerce'),
'狀態': lambda x: np.where(x == "Y", True, False)
},
encoding='gbk')在這里也體現了使用自定義函數比lambda表達式要方便很多。(大部分情況下lambda還是很簡潔的,筆者自己也很喜歡使用)
感謝各位的閱讀!關于“Pandas如何實現數據類型轉換”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





