溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“pytorch + visdom CNN如何處理自建圖片數據集”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“pytorch + visdom CNN如何處理自建圖片數據集”這篇文章吧。
環境
系統:win10
cpu:i7-6700HQ
gpu:gtx965m
python : 3.6
pytorch :0.3
數據下載
下載后解壓放到項目根目錄:
數據集為用來分類 螞蟻和蜜蜂。有大約120個訓練圖像,每個類有75個驗證圖像。
數據導入
可以使用 torchvision.datasets.ImageFolder(root,transforms) 模塊 可以將 圖片轉換為 tensor。
先定義transform:
ata_transforms = {
'train': transforms.Compose([
# 隨機切成224x224 大小圖片 統一圖片格式
transforms.RandomResizedCrop(224),
# 圖像翻轉
transforms.RandomHorizontalFlip(),
# totensor 歸一化(0,255) >> (0,1) normalize channel=(channel-mean)/std
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]),
"val" : transforms.Compose([
# 圖片大小縮放 統一圖片格式
transforms.Resize(256),
# 以中心裁剪
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
}導入,加載數據:
data_dir = './hymenoptera_data'
# trans data
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']}
# load data
data_loaders = {x: DataLoader(image_datasets[x], batch_size=BATCH_SIZE, shuffle=True) for x in ['train', 'val']}
data_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
print(data_sizes, class_names){'train': 244, 'val': 153} ['ants', 'bees']
訓練集 244圖片 , 測試集153圖片 。
可視化部分圖片看看,由于visdom支持tensor輸入 ,不用換成numpy,直接用tensor計算即可 :
inputs, classes = next(iter(data_loaders['val'])) out = torchvision.utils.make_grid(inputs) inp = torch.transpose(out, 0, 2) mean = torch.FloatTensor([0.485, 0.456, 0.406]) std = torch.FloatTensor([0.229, 0.224, 0.225]) inp = std * inp + mean inp = torch.transpose(inp, 0, 2) viz.images(inp)

創建CNN
net 根據上一篇的處理cifar10的改了一下規格:
class CNN(nn.Module): def __init__(self, in_dim, n_class): super(CNN, self).__init__() self.cnn = nn.Sequential( nn.BatchNorm2d(in_dim), nn.ReLU(True), nn.Conv2d(in_dim, 16, 7), # 224 >> 218 nn.BatchNorm2d(16), nn.ReLU(inplace=True), nn.MaxPool2d(2, 2), # 218 >> 109 nn.ReLU(True), nn.Conv2d(16, 32, 5), # 105 nn.BatchNorm2d(32), nn.ReLU(True), nn.Conv2d(32, 64, 5), # 101 nn.BatchNorm2d(64), nn.ReLU(True), nn.Conv2d(64, 64, 3, 1, 1), nn.BatchNorm2d(64), nn.ReLU(True), nn.MaxPool2d(2, 2), # 101 >> 50 nn.Conv2d(64, 128, 3, 1, 1), # nn.BatchNorm2d(128), nn.ReLU(True), nn.MaxPool2d(3), # 50 >> 16 ) self.fc = nn.Sequential( nn.Linear(128*16*16, 120), nn.BatchNorm1d(120), nn.ReLU(True), nn.Linear(120, n_class)) def forward(self, x): out = self.cnn(x) out = self.fc(out.view(-1, 128*16*16)) return out # 輸入3層rgb ,輸出 分類 2 model = CNN(3, 2)
loss,優化函數:
line = viz.line(Y=np.arange(10)) loss_f = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=LR, momentum=0.9) scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
參數:
BATCH_SIZE = 4 LR = 0.001 EPOCHS = 10
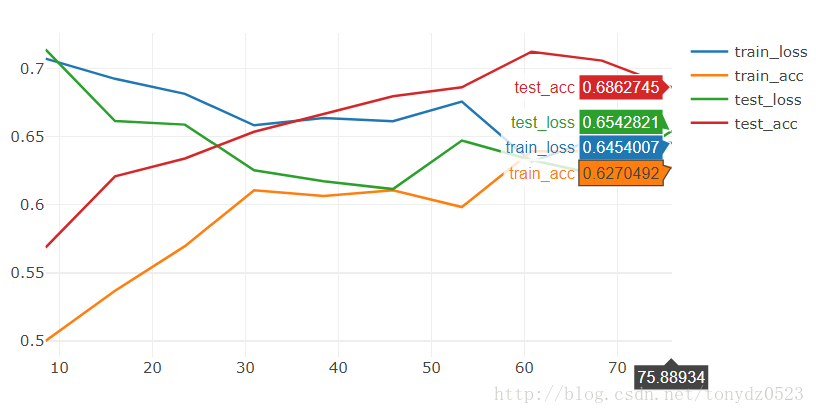
運行 10個 epoch 看看:
[9/10] train_loss:0.650|train_acc:0.639|test_loss:0.621|test_acc0.706
[10/10] train_loss:0.645|train_acc:0.627|test_loss:0.654|test_acc0.686
Training complete in 1m 16s
Best val Acc: 0.712418
運行 20個看看:
[19/20] train_loss:0.592|train_acc:0.701|test_loss:0.563|test_acc0.712
[20/20] train_loss:0.564|train_acc:0.721|test_loss:0.571|test_acc0.706
Training complete in 2m 30s
Best val Acc: 0.745098
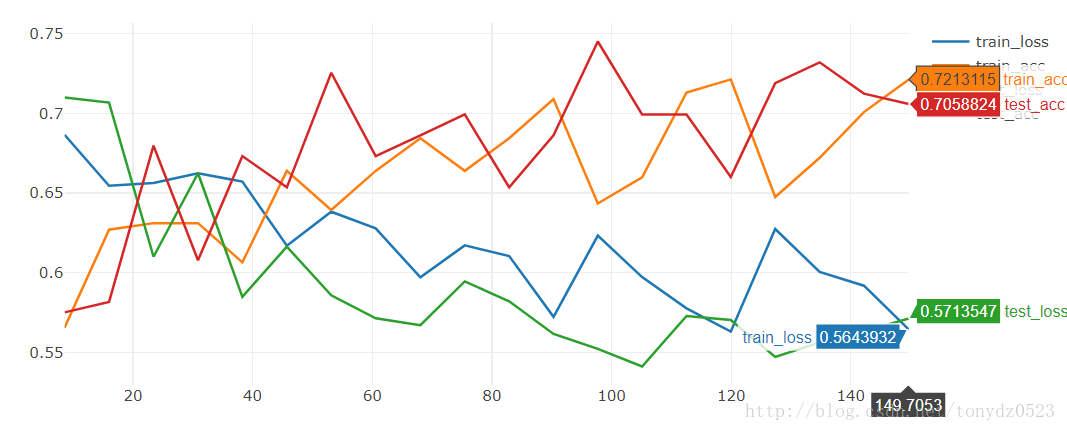
準確率比較低:只有74.5%
我們使用models 里的 resnet18 運行 10個epoch:
model = torchvision.models.resnet18(True) num_ftrs = model.fc.in_features model.fc = nn.Linear(num_ftrs, 2)
[9/10] train_loss:0.621|train_acc:0.652|test_loss:0.588|test_acc0.667
[10/10] train_loss:0.610|train_acc:0.680|test_loss:0.561|test_acc0.667
Training complete in 1m 24s
Best val Acc: 0.686275
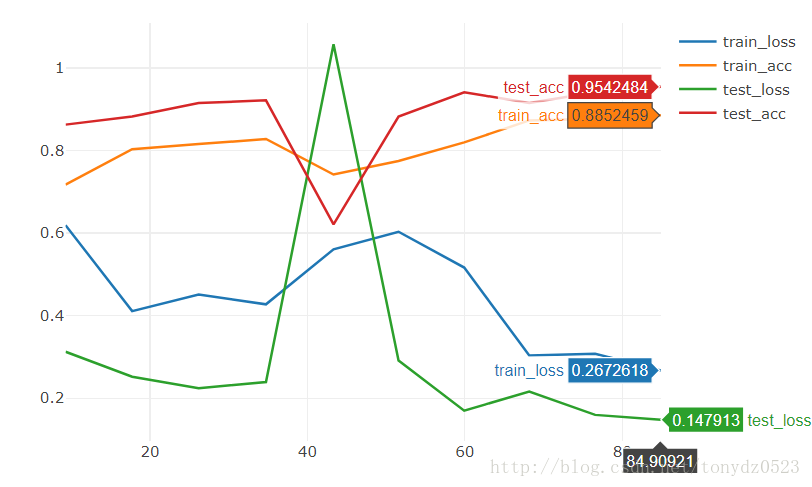
效果也很一般,想要短時間內就訓練出效果很好的models,我們可以下載訓練好的state,在此基礎上訓練:
model = torchvision.models.resnet18(pretrained=True) num_ftrs = model.fc.in_features model.fc = nn.Linear(num_ftrs, 2)
[9/10] train_loss:0.308|train_acc:0.877|test_loss:0.160|test_acc0.941
[10/10] train_loss:0.267|train_acc:0.885|test_loss:0.148|test_acc0.954
Training complete in 1m 25s
Best val Acc: 0.954248
10個epoch直接的到95%的準確率。
以上是“pytorch + visdom CNN如何處理自建圖片數據集”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





