溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下如何使用Python搭建點擊率預估模型,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
點擊率預估模型
0.前言
本篇是一個基礎機器學習入門篇文章,幫助我們熟悉機器學習中的神經網絡結構與使用。
日常中習慣于使用Python各種成熟的機器學習工具包,例如sklearn、TensorFlow等等,來快速搭建各種各樣的機器學習模型來解決各種業務問題。
本文將從零開始,僅僅利用基礎的numpy庫,使用Python實現一個最簡單的神經網絡(或者說是簡易的LR,因為LR就是一個單層的神經網絡),解決一個點擊率預估的問題。
1.假設一個業務場景
聲明:為了簡單起見,下面的一切設定從簡….
定義需要解決的問題:
老板:小李,這臺機器上有一批微博的點擊日志數據,你拿去分析一下,然后搞點擊率預測啥的…
是的,就是預測一篇微博是否會被用戶點擊(被點擊的概率)…..預測未來,貌似很神奇的樣子!
熱門微博
簡單的介紹一下加深的業務數據
每一條微博數據有由三部分構成: {微博id, 微博特征X, 微博點擊標志Y}
微博特征X有三個維度:
X={x0="該微博有娛樂明星”,x1="該微博有圖”,x2="該微博有表情”}
微博是否被點擊過的標志Y:
Y={y0=“點擊”, y1=“未點擊”}
數據有了,接下來需要設計一個模型,把數據輸入進去進行訓練之后,在預測階段,只需要輸入{微博id,微博特征X},模型就會輸出每一個微博id會被點擊的概率。
2.任務分析:
這是一個有監督的機器學習任務
對于有監督的機器學習任務,可以簡單的分為分類與回歸問題,這里我們簡單的想實現預測一條微博是否會被用戶點擊,預測目標是一個二值類別:點擊,或者不點擊,顯然可以當做一個分類問題。
所以,我們需要搭建一個分類模型(點擊率預測模型),這也就決定我們需要構建一個有監督學習的訓練數據集。
模型的選擇
選擇最簡單神經網絡模型,人工神經網絡有幾種不同類型的神經網絡,比如前饋神經網絡、卷積神經網絡及遞歸神經網絡等。本文將以簡單的前饋或感知神經網絡為例,這種類型的人工神經網絡是直接從前到后傳遞數據的,簡稱前向傳播過程。
3.數據準備:
整體的流程:
數據預處理(數值化編碼)——>特征篩選——>選擇模型(前饋神經網絡)——>訓練模型——>模型預測
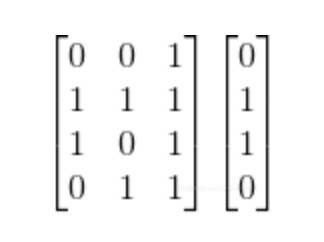
假設,對4條微博的數據進行數值化編碼,可以表示為如下的矩陣格式:
訓練數據XY
解讀一條樣本數據:
第一條樣本數據為:X0=[0 0 1],分別對應著三維的特征,最后4x1的矩陣是Y,0表示無,1表示有,可知該特征對應的Y0是未點擊。
所以,這條樣本可以翻譯為:[該微博沒娛樂明星,沒有圖片,有表情],最終y=0,代表該條微博沒有被點擊。
業務以及數據特征是不是很簡單….簡單有點看起來編的不太合理 - !
4.神經網絡基本結構:
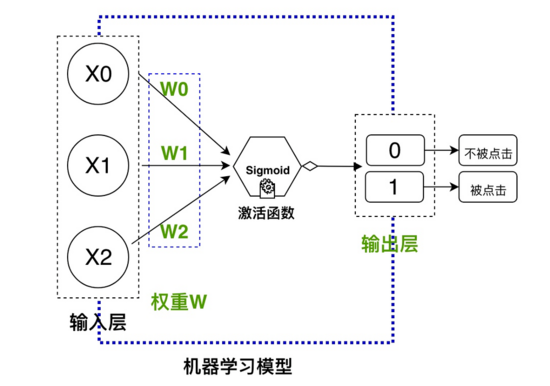
1.輸入層:輸入的業務特征數據
2.隱藏層:初始化權重參數
3.激活函數:選擇激活函數
4.輸出層:預測的目標,定義損失函數
我們即將使用的機器學習模型:
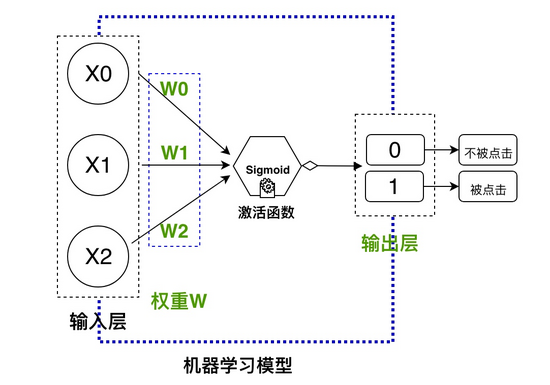
超級簡單的前饋神經網絡
機器學習模型類似一個黑盒子,輸入歷史點擊的數據,進行訓練,然后就可以對未來的額數據進行預測….我們上面設計的是一個超級簡單的前饋神經網絡,但是可以實現我們上面的目的。
關于激活函數:
通過引入激活函數,實現了非線性變換,增強了模型的擬合效果。
關乎激活函數,請看之前的文章 吾愛NLP(2)--解析深度學習中的激活函數
在本文教程中,使用的是簡單的Sigmoid激活函數,但注意一點,在深層神經網絡模型中, sigmoid激活函數一般不作為首選,原因是其易發生梯度彌散現象。
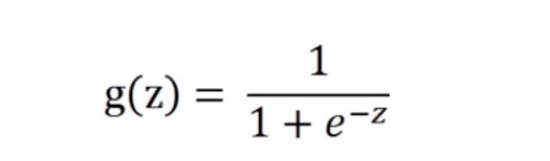
sigmoid公式
此函數可以將任何值映射到0到1之間,并能幫助我們規范化輸入的加權和。
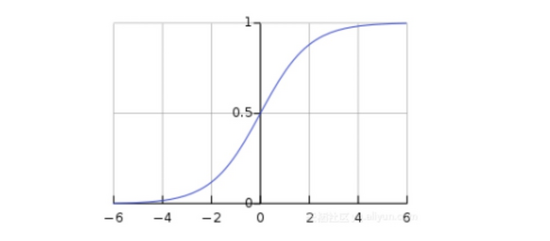
sigmoid圖像
對sigmoid激活函數求偏導:
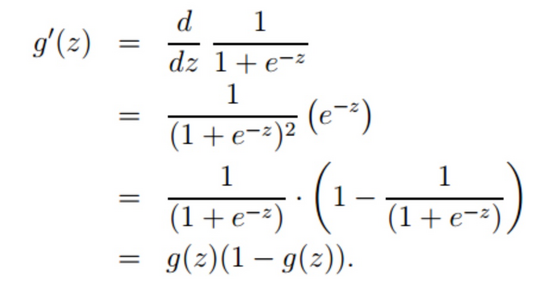
該偏導函數嗎,等下寫程序會用到,所以先放在這里!
模型的訓練
訓練階段,模型的輸入X已經確定,輸出層的Y確定,機器學習模型確定,唯一需要求解的就是模型中的權重W,這就是訓練階段的目標。
主要由三個核心的流程構成:
前向計算—>計算損失函數—>反向傳播
本文使用的模型是最簡單的前饋神經網絡,起始就是一個LR而已….所以整個過程這里就不繼續介紹了,因為之前已經寫過一篇關于LR的文章--- 邏輯回歸(LR)個人學習總結篇 ,如果對其中的細節以及公式的推導有疑問,可以去LR文章里面去尋找答案。
這里再提一下權重參數W更新的公式:
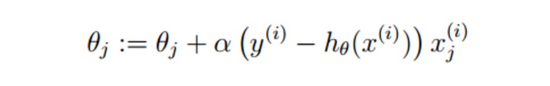
至此,所有的寫代碼需要的細節都已經交代結束了,剩下的就是代碼了。
5.使用Python代碼構建網絡
# coding:utf-8 import numpy as np class NeuralNetwork(): # 隨機初始化權重 def __init__(self): np.random.seed(1) self.synaptic_weights = 2 * np.random.random((3, 1)) - 1 # 定義激活函數:這里使用sigmoid def sigmoid(self, x): return 1 / (1 + np.exp(-x)) #計算Sigmoid函數的偏導數 def sigmoid_derivative(self, x): return x * (1 - x) # 訓練模型 def train(self, training_inputs, training_outputs,learn_rate, training_iterations): # 迭代訓練 for iteration in range(training_iterations): #前向計算 output = self.think(training_inputs) # 計算誤差 error = training_outputs - output # 反向傳播-BP-微調權重 adjustments = np.dot(training_inputs.T, error * self.sigmoid_derivative(output)) self.synaptic_weights += learn_rate*adjustments def think(self, inputs): # 輸入通過網絡得到輸出 # 轉化為浮點型數據類型 inputs = inputs.astype(float) output = self.sigmoid(np.dot(inputs, self.synaptic_weights)) return output if __name__ == "__main__": # 初始化前饋神經網絡類 neural_network = NeuralNetwork() print "隨機初始化的權重矩陣W" print neural_network.synaptic_weights # 模擬訓練數據X train_data=[[0,0,1], [1,1,1], [1,0,1], [0,1,1]] training_inputs = np.array(train_data) # 模擬訓練數據Y training_outputs = np.array([[0,1,1,0]]).T # 定義模型的參數: # 參數學習率 learn_rate=0.1 # 模型迭代的次數 epoch=150000 neural_network.train(training_inputs, training_outputs, learn_rate, epoch) print "迭代計算之后權重矩陣W: " print neural_network.synaptic_weights # 模擬需要預測的數據X pre_data=[0,0,1] # 使用訓練的模型預測該微博被點擊的概率 print "該微博被點擊的概率:" print neural_network.think(np.array(pre_data)) """ 終端輸出的結果: 隨機初始化的權重矩陣W [[-0.16595599] [ 0.44064899] [-0.99977125]] 迭代計算之后權重矩陣W: [[12.41691302] [-0.20410552] [-6.00463275]] 該微博被點擊的概率: [0.00246122] [Finished in 20.2s] """
以上是“如何使用Python搭建點擊率預估模型”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





