溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹pandas使用groupby后如何對層級索引levels進行處理,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
層及索引levels,剛開始學習pandas的時候沒有太多的操作關于groupby,僅僅是簡單的count、sum、size等等,沒有更深入的利用groupby后的數據進行處理。近來數據處理的時候有遇到這類問題花了一點時間,所以這里記錄以及復習一下:
我使用一個實例來講解下面的問題:一張數據表中有三列(動物物種、物種品種、品種價格),選出每個物種從大到小品種的前兩種,最后只需要品種和價格這兩列。

以上這張表是我們后面需要處理的數據表 (物種 品種 價格)
levels:層及索引 (創建pandas類型時可以預先定義;使用groupby后也會生成)
我們看看levels什么樣(根據df1物種分類,再根據df2品種排序后 如下圖)
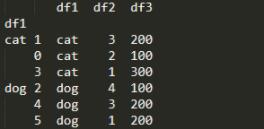
圖中可以看出,根據groupby分類后的cat、dog便是level,以及后面的一列原始位置索引也是level
好了現在簡單了解levels,我們該如何對它進行處理,如何完成上面的實例呢?(可能你拿到這樣的層級數據,不會操作,不知道如何提取其中的信息)
代碼及講解如下:
首先導入pandas、numpy庫,以及創建原始數據:
import pandas as pd
import numpy as np
df = pd.DataFrame({'df1':['cat','cat','dog','cat','dog','dog'],'df2':[2,3,4,1,3,1],'df3':[100,200,100,300,200,200]})原始數據最上面那張圖
下面我們根據物種來分類,并且使用apply調用sort_df2函數對品種進行排序:
def sort_df2(data): data = data.sort_values(by='df2',ascending=False) #df2:品種列 ascending:排序方式 return data group = df.groupby(df['df1']).apply(sort_df2) #groupby以及apply的結合使用
處理后數據,上面第二張圖
print(group.index) #看看groupby后的行索引什么樣

groupby后如上圖,有層級標簽(這里兩列),labels標簽(分類,位置)
這里我們需要的是第一層級標簽的第一列(也就是cat、dog)
levels = group.index.levels[0] #取出第一級標簽:
下面將是兩層循環,完成從中選出(物種前兩個品種以及它的價格),很簡單的操作:
values = [] for i in levels: mid_group = group.loc[i] #選出i標簽物種的所有品種 mid_group = mid_group.iloc[:2,:] #我們只取排序后的品種的前兩種(要注意這里使用iloc,它與loc的區別) cnt = len(mid_group) #為了防止循環長度錯誤,所以我們還是需要計算長度,因為如果真正數據不足2條還是不報錯 for j in range(cnt): #現在在每個物種cat、dog中操作 value = mid_group.iloc[j,:] #我們選出該物種的第j條所有信息df1、df2、df3 value_pro = (value['df2'],value['df3']) #然后只取df2、df3,將它們放到元組中 values.append(value_pro)
所有的操作完成了,我們看看結果:
print(values) #此時在列表中保存了上面提取的元組信息,我們可以使用pandas再次轉換它們為DataFrame,也可以做其它操作
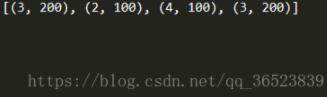
我覺得這個例子比較形象,但是還是有邏輯欠缺的地方,不過不重要,看懂了上面的例子,基本上就能了解和處理層級數據了。當然這里的數據簡單,只是為了更好的理解,真正的處理數據時,可能會出現更為復雜的層級結構,這時需要能夠更靈活的處理,如果你有更好的理解和建議,可以回復。
-------更新(增加對兩層索引的操作)--------
在原來的基礎上增加一列df4表示動物的大小特征
df = pd.DataFrame({'df1':['cat','cat','dog','cat','dog','dog'],'df2':[2,3,4,1,3,1],'df3':[100,200,100,300,200,200],'df4':['大','中','小','巨大','小','中']})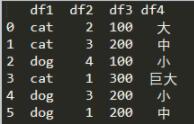
此時根據df1、df4兩列來分類,再對兩層的層級索引操作:
df_group = df.groupby(['df1','df4']).size()

分類后得到的是對應兩個特征的動物數量,現在來取得其中的值:
print(df_group.index) h = df_group.loc[['cat','df4']] print(h)
先查看數據的index信息,從中我們可以看到兩層索引對應的levels有兩中,然后我們根據loc測試選出cat類的df4這一列(也可以填大、中、巨大選出一列)
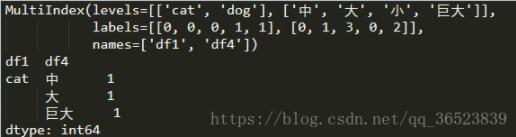
這樣就得到了cat種類的信息,當然也可以選出dog種類,那么如何得出(cat,巨大,1)這樣的一一對應的數據呢?
df1_name = df_group.index.levels[0] #獲得第一層的分類cat、dog
for i in range(len(df1_name)): #循環遍歷第一層
df_level = df_group.loc[[df1_name[i],'df4']] #這里是選出第一層的所有信息
df_level_ch = pd.DataFrame(df_level) #由于上面得到是Series我們需要將它轉換為DataFrame才能更好的操作
for j in range(len(df_level_ch)): #開始對第二層進行遍歷
a = df_level_ch.ix[j].name #由于是DataFrame所以可以取每一行的name值('cat','大')
b = df_level_ch.values[j][0] #獲取對應數量,由于是嵌套列表,所以我們逐層獲取
print(a,b)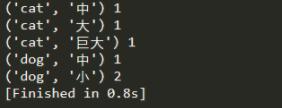
基本上是篩選出來了,還是很簡單的。這只是其中的一個例子,如果遇到需要其他的操作,可以根據這個例子來隨機變換。
這個方法雖然可以篩選,但是個人覺得數據量過大,就不是很好,小編暫時沒有更好的方法
以上是“pandas使用groupby后如何對層級索引levels進行處理”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





