溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
引言
小A正在balabala寫代碼呢,DBA小B突然發來了一條消息,“快看看你的用戶特定信息表T,里面的主鍵,也就是自增id,都到16億了,這才多久,在這樣下去過不了多久主鍵就要超出范圍了,插入就會失敗,balabala......”
我記得沒有這么多,最多1k多萬,count了下,果然是1100萬。原來運維是通過auto_increment那個值看的,就是說,表中有大量的刪除插入操作,但是我大部分情況都是更新的,怎么會這樣?
下面話不多說了,來一起看看詳細的介紹吧
問題排查
這張表是一個簡單的接口服務在使用,每天大數據會統計一大批信息,然后推送給小A,小A將信息更新到數據庫中,如果是新數據就插入,舊數據就更新之前的數據,對外接口就只有查詢了。
很快,小A就排查了一遍自己的代碼,沒有刪除的地方,也沒有主動插入、更新id的地方,怎么會這樣呢?難道是小B的原因,也不太可能,DBA那邊兒管理很多表,有問題的話早爆出來了,但問題在我這里哪里也沒頭緒。
小A又仔細觀察了這1000多萬已有的數據,將插入時間、id作為主要觀察字段,很快,發現了個問題,每天第一條插入的數據總是比前一天多1000多萬,有時候遞增的多,有時候遞增的少,小A又將矛頭指向了DBA小B,將問題又給小B描述了一遍。
小B問了小A,“你是是不是用了REPLACE INTO ...語句”,這是怎么回事呢,原來REPLACE INTO ...會對主鍵有影響。
REPLACE INTO ...對主鍵的影響
假設有一張表t1:
CREATE TABLE `t1` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID,自增', `uid` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '用戶uid', `name` varchar(20) NOT NULL DEFAULT '' COMMENT '用戶昵稱', PRIMARY KEY (`id`), UNIQUE KEY `u_idx_uid` (`uid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='測試replace into';
如果新建這張表,執行下面的語句,最后的數據記錄如何呢?
insert into t1 values(NULL, 100, "test1"),(NULL, 101, "test2"); replace into t1 values(NULL, 100, "test3");
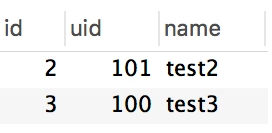
原來,REPLACE INTO ...每次插入的時候如果唯一索引對應的數據已經存在,會刪除原數據,然后重新插入新的數據,這也就導致id會增大,但實際預期可能是更新那條數據。
小A說:“我知道replace是這樣,所有既沒有用它”,但還是又排查了一遍,確實不是自己的問題,沒有使用REPLACE INTO ...,
小A又雙叒叕仔細的排查了一遍,還是沒發現問題,就讓小B查下binlog日志,看看是不是有什么奇怪的地方,查了之后還是沒發現問題,確實存在跳躍的情況,但并沒有實質性的問題。
下圖中@1的值對應的是自增主鍵id,用(@2, @3)作為唯一索引
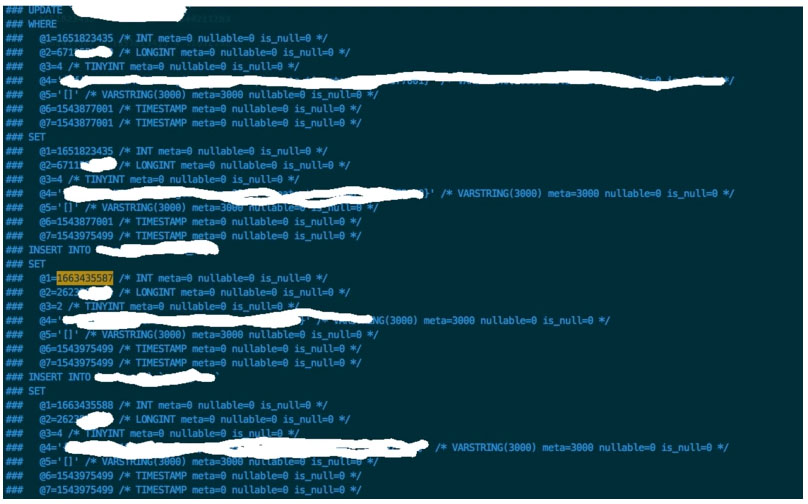
后來過了很久,小B給小A指了個方向,小A開始懷疑自己的插入更新語句INSERT ... ON DUPLICATE KEY UPDATE ...了,查了許久,果然是這里除了問題。
INSERT ... ON DUPLICATE KEY UPDATE ...對主鍵的影響
這個語句跟REPLACE INTO ...類似,不過他并不會變更該條記錄的主鍵,還是上面t1這張表,我們執行下面的語句,執行完結果是什么呢?
insert into t1 values(NULL, 100, "test4") on duplicate key update name = values(name);
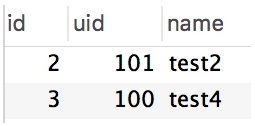
沒錯,跟小A預想的一樣,主鍵并沒有增加,而且name字段已經更新為想要的了,但是執行結果有條提示,引起了小A的注意
No errors; 2 rows affected, taking 10.7ms
明明更新了一條數據,為什么這里的影響記錄條數是2呢?小A,又看了下目前表中的auto_increment
CREATE TABLE `t1` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID,自增', `uid` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '用戶uid', `name` varchar(20) NOT NULL DEFAULT '' COMMENT '用戶昵稱', PRIMARY KEY (`id`), UNIQUE KEY `u_idx_uid` (`uid`) ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8 COMMENT='測試replace into';
竟然是5`,這里本應該是4的。
也就是說,上面的語句,會跟REPLACE INTO ...類似的會將自增ID加1,但實際記錄沒有加,這是為什么呢?
查了資料之后,小A得知,原來,mysql主鍵自增有個參數innodb_autoinc_lock_mode,他有三種可能只0,1,2,mysql5.1之后加入的,默認值是1,之前的版本可以看做都是0。
可以使用下面的語句看當前是哪種模式
select @@innodb_autoinc_lock_mode;
小A使用的數據庫默認值也是1,當做簡單插入(可以確定插入行數)的時候,直接將auto_increment加1,而不會去鎖表,這也就提高了性能。當插入的語句類似insert into select ...這種復雜語句的時候,提前不知道插入的行數,這個時候就要要鎖表(一個名為AUTO_INC的特殊表鎖)了,這樣auto_increment才是準確的,等待語句結束的時候才釋放鎖。還有一種稱為Mixed-mode inserts的插入,比如INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (5,'c'), (NULL,'d'),其中一部分明確指定了自增主鍵值,一部分未指定,還有我們這里討論的INSERT ... ON DUPLICATE KEY UPDATE ...也屬于這種,這個時候會分析語句,然后按盡可能多的情況去分配auto_incrementid,這個要怎么理解呢,我看下面這個例子:
truncate table t1; insert into t1 values(NULL, 100, "test1"),(NULL, 101, "test2"),(NULL, 102, "test2"),(NULL, 103, "test2"),(NULL, 104, "test2"),(NULL, 105, "test2"); -- 此時數據表下一個自增id是7 delete from t1 where id in (2,3,4); -- 此時數據表只剩1,5,6了,自增id還是7 insert into t1 values(2, 106, "test1"),(NULL, 107, "test2"),(3, 108, "test2"); -- 這里的自增id是多少呢?
上面的例子執行完之后表的下一個自增id是10,你理解對了嗎,因為最后一條執行的是一個Mixed-mode inserts語句,innoDB會分析語句,然后分配三個id,此時下一個id就是10了,但分配的三個id并不一定都使用。此處 @總是遲到 多謝指出,看官方文檔理解錯了
模式0的話就是不管什么情況都是加上表鎖,等語句執行完成的時候在釋放,如果真的添加了記錄,將auto_increment加1。
至于模式2,什么情況都不加AUTO_INC鎖,存在安全問題,當binlog格式設置為Statement模式的時候,從庫同步的時候,執行結果可能跟主庫不一致,問題很大。因為可能有一個復雜插入,還在執行呢,另外一個插入就來了,恢復的時候是一條條來執行的,就不能重現這種并發問題,導致記錄id可能對不上。
至此,id跳躍的問題算是分析完了,由于innodb_autoinc_lock_mode值是1,INSERT ... ON DUPLICATE KEY UPDATE ...是簡單的語句,預先就可以計算出影響的行數,所以不管是否更新,這里都將auto_increment加1(多行的話大于1)。
如果將innodb_autoinc_lock_mode值改為0,再次執行INSERT ... ON DUPLICATE KEY UPDATE ...的話,你會發現auto_increment并沒有增加,因為這種模式直接加了AUTO_INC鎖,執行完語句的時候釋放,發現沒有增加行數的話,不會增加自增id的。
INSERT ... ON DUPLICATE KEY UPDATE ...影響的行數是1為什么返回2?
為什么會這樣呢,按理說影響行數就是1啊,看看官方文檔的說明
With ON DUPLICATE KEY UPDATE, the affected-rows value per row is 1 if the row is inserted as a new row, 2 if an existing row is updated, and 0 if an existing row is set to its current values
官方明確說明了,插入影響1行,更新影響2行,0的話就是存在且更新前后值一樣。是不是很不好理解?
其實,你要這樣想就好了,這是為了區分到底是插入了還是更新了,返回1表示插入成功,2表示更新成功。
解決方案
將innodb_autoinc_lock_mode設置為0肯定可以解決問題,但這樣的話,插入的并發性可能會受很大影響,因此小A自己想著DBA也不會同意。經過考慮,目前準備了兩種較為可能的解決方案:
修改業務邏輯
修改業務邏輯,將INSERT ... ON DUPLICATE KEY UPDATE ...語句拆開,先去查詢,然后去更新,這樣就可以保證主鍵不會不受控制的增大,但增加了復雜性,原來的一次請求可能變為兩次,先查詢有沒有,然后去更新。
刪除表的自增主鍵
刪除自增主鍵,讓唯一索引來做主鍵,這樣子基本不用做什么變動,只要確定目前的自增主鍵沒有實際的用處即可,這樣的話,插入刪除的時候可能會影響效率,但對于查詢多的情況來說,小A比較兩種之后更愿意選擇后者。
結語
其實INSERT ... ON DUPLICATE KEY UPDATE ...這個影響行數是2的,小A很早就發現了,只是沒有保持好奇心,不以為然罷了,沒有深究其中的問題,這深究就起來會帶出來一大串新知識,挺好,看來小A還是要對外界保持好奇心,保持敏感,這樣才會有進步。
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作具有一定的參考學習價值,如果有疑問大家可以留言交流,謝謝大家對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





