溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
先放一段代碼
for(int i=0;i<1000;i++){
for(int j=0;j<5;j++){
System.out.println("hello");
}
}
for(int i=0;i<5;i++){
for(int j=0;j<1000;j++){
System.out.println("hello");
}
}
分析以上代碼可以看到兩行代碼除了循環的次序不一致意外,其他并無區別,在實際執行時兩者所消耗的時間和空間應該也是一致的。但是這僅僅是在Java中,現在我們轉化一下情景,最外層循環是數據庫中的連接操作,內層循環為查找操作,那么現在兩次的結果將相差巨大。
之所以出現這樣的原因是數據庫的特點決定的,數據庫中相比較于查詢操作而言,建立連接是更消耗資源的。第一段代碼建立了1000次連接,每一次連接卻只做了5次查詢,顯然是很浪費的。
因此在我們對數據庫進行操作時需要遵循的操作應當是小表驅動大表(小的數據集驅動大的數據集)。
in與exists
表結構
tbl_emp為員工表,deptld為部門id。tbl_dept為部門表。員工表中含有客人,其deptld字段為-1
mysql> desc tbl_emp; +--------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | YES | | NULL | | | deptld | int(11) | YES | MUL | NULL | | +--------+-------------+------+-----+---------+----------------+ 3 rows in set (0.00 sec) mysql> desc tbl_dept; +----------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +----------+-------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | deptName | varchar(30) | YES | MUL | NULL | | | locAdd | varchar(40) | YES | | NULL | | +----------+-------------+------+-----+---------+----------------+ 3 rows in set (0.01 sec)
我們知道對于一個公司而言相對于部門來說員工數要多得多。現在我們有這樣一個需求:查詢屬于這個公司的員工(不含來訪客人),我們可以用以下代碼解決
利用in
# 先查詢部門表中所有的id,然后拿員工表中的deptld字段與之對比,若含有則保留。
mysql> select * from tbl_emp a where a.deptld in (select id from tbl_dept);
in關鍵字就像or的拼接,例如上述sql雨中子查詢查出的結果為1,2,3。則sql語句等價于以下形式
mysql> select * from tbl_emp a where a.deptld=1 or a.deptld=2 or a.deptld=3
總的來說in關鍵字就是將子查詢中的所有結果都查出來,假設結果集為B,共有m條記錄,然后在將子查詢條件的結果集分解成m個,再進行m次查詢。可以看到這里主要是用到了A的索引,B表如何對查詢影響不大
利用exists
mysql> select * from tbl_emp a where exists (select 1 from tbl_dept b where a.deptld = b.id );
exits:將主查詢的數據放到子查詢中做條件驗證,根據驗證結果(True或False)來判斷是否保留主查詢中的記錄。
for (i = 0; i < count(A); i++) { //遍歷A的總記錄數
a = get_record(A, i); //從A表逐條獲取記錄
if (B.id = a[id]) //如果子條件成立
result[] = a;
}
return result;
可以看到:exists主要是用到了B表的索引,A表如何對查詢的效率影響不大
結論
mysql> select * from tbl_emp a where a.deptld in (select id from tbl_dept);
若tbl_dept的記錄數少余tbl_emp則使用in效率比較高
mysql> select * from tbl_emp a where exists (select 1 from tbl_dept b where a.deptld = b.id );
若tbl_dept的記錄數多余tbl_emp則使用in效率比較高
下面給大家介紹IN與EXISTS的區別
1、IN查詢分析
SELECT * FROM A WHERE id IN (SELECT id FROM B);
等價于:1、SELECT id FROM B ----->先執行in中的查詢
2、SELECT * FROM A WHERE A.id = B.id
以上in()中的查詢只執行一次,它查詢出B中的所有的id并緩存起來,然后檢查A表中查詢出的id在緩存中是否存在,如果存在則將A的查詢數據加入到結果集中,直到遍歷完A表中所有的結果集為止。
以下用遍歷結果集的方式來分析IN查詢
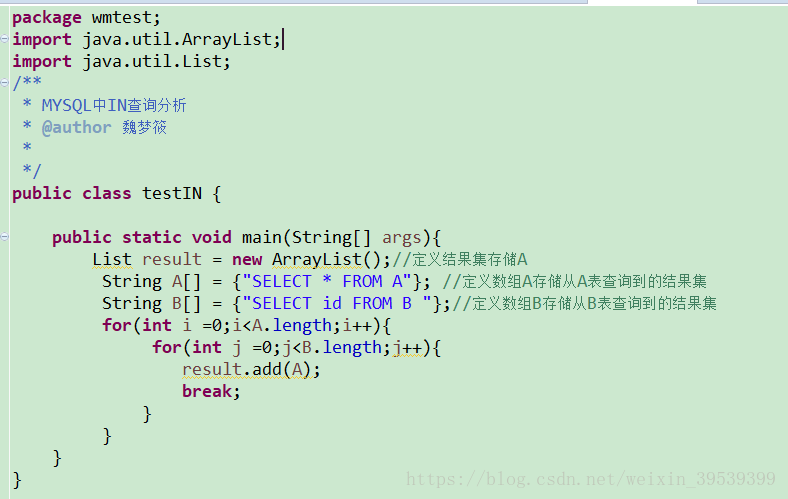
通過以上程序可以看出,當B表的數據較大時不適合使用in()查詢,因為它會將B表中的數據全部遍歷一次
例如:
1、A表中有100條記錄,B表中有1000條記錄,那么最多可能遍歷100*1000次,效率很差
2、A表中有1000條記錄,B表中有100條記錄,那么最多可遍歷1000*100此,內循環次數減少,效率大大提升
結論:IN()查詢適合B表數據比A表數據小的情況,IN()查詢是從緩存中取數據
2、EXISTS查詢分析
語法:SELECT 字段 FROM table WHERE EXISTS(subquery);
SELECT * FROM a WHERE EXISTS(SELECT 1 FROM b WHERE B.id = A.id);
以上查詢等價于:
SELECT * FROM A; SELECT I FROM B WHERE B.id = A.id;
EXISTS()查詢會執行SELECT * FROM A查詢,執行A.length次,并不會將EXISTS()查詢結果結果進行緩存,因為EXISTS()查詢返回一個布爾值true或flase,它只在乎EXISTS()的查詢中是否有記錄,與具體的結果集無關。
EXISTS()查詢是將主查詢的結果集放到子查詢中做驗證,根據驗證結果是true或false來決定主查詢數據結果是否得以保存。
總結
以上所述是小編給大家介紹的MySQL中in與exists的使用及區別介紹,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對億速云網站的支持!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





