溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
由于需要使用一個純單詞組成的文件,在網上下載到了一個存放單詞的文件,但是里面有中文的解釋,那就需要做一下提取了。
文本的形式如下:
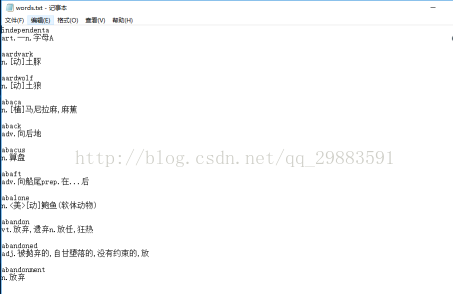
所見即所得,這個文本是有規律的,每個單詞為一行,緊接著下一行便是單詞的解釋,有了這種規律我們就很好處理了。
首先我們來將文件的數據讀取出來:
#coding:utf-8
file_object = open('words.txt')
try:
lines = file_object.readlines()
finally:
file_object.close( )
for line in lines:
print line
代碼執行的結果為:
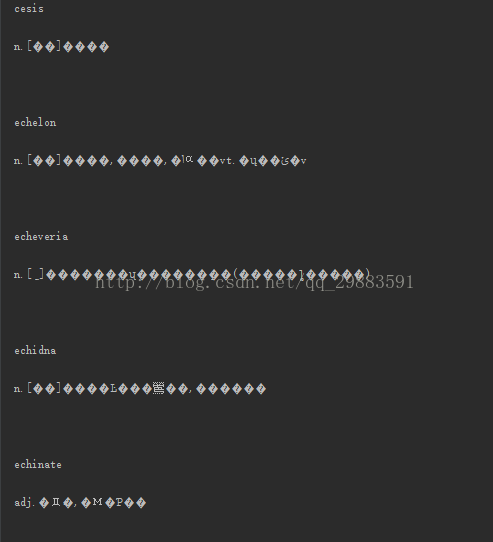
顯然,這不是我們想要的結果,因為這里面有太多的空行了,現在最主要的就是要處理掉這些妨礙我們的空行,對于中文的亂碼呢,我們是不需要中文的解釋的,所以它是無妨礙的,如果想看得舒服些,那么我們就轉碼一下就好了。現在最主要的就是要知道為什么會出現這么多的空行,因為我們的文件是已將看過了,顯然是這些空行的出現是有點“匪夷所思”的,這也是由于python讀文件的機制導致的,下面我們修改下代碼,來看看原因:
#coding:utf-8
file_object = open('words.txt')
try:
lines = file_object.readlines()
finally:
file_object.close( )
print lines
在這里,我們直接輸出lines,得到如下的結果:

我們隨意拿出這句'runlet\n', 'n.\xcd\xb0,\xd0\xa1\xba\xd3\n', '\n', 'runnel\n', 'n.\xd0\xa1\xba\xd3,\xcf\xb8\xc1\xf7\n', '\n',從中可以看出,對于每行的文件,在讀取的時候,換行符“\n”也是會被讀取在單詞和對應的解釋的后面的,所以這也就是為什么會有那么多空行的原因了,這顯然不是我們想要看見的,下面我們處理一下,讓這些多余的空行失去效果:
#coding:utf-8
file_object = open('words.txt')
try:
lines = file_object.readlines()
finally:
file_object.close( )
for line in lines:
if line!='\n':
print line.decode('gb2312','ignore'), #逗號得帶著,因為文件自身帶了換行,可以代替pirnt的換行
程序執行后,得到如下的結果:

好了,這下就是我們想看到的東西了,那么,現在我們可以將這些輸出寫入 到新的文件里了,然后就可以得到我們想要的單詞文本了。
#coding:utf-8
file_object = open('words.txt')
try:
lines = file_object.readlines()
finally:
file_object.close( )
myfile=open('newfile.txt','w')
num=0
for word in lines:
if word!='\n':
num+=1
if num%2: #只有奇數行為單詞
myfile.write(word)
運行程序便可以得到新的單詞文件了,最終提取了45000多個單詞,文件如下所示:
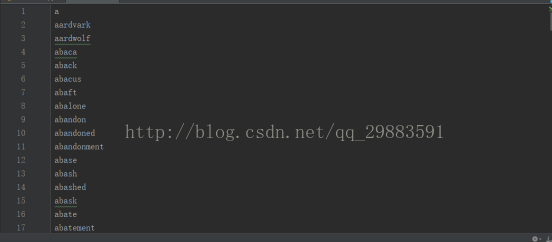
很顯然,滿足我們最終想要實現的要求,那么可以收工了。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





