溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹如何使用puppeteer爬取網站并抓出404無效鏈接,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
檢查網頁無效鏈接
前言
自動化技術可以幫助我們做自動化測試,同樣也可以幫助我們完成別的事情,比如今天我們要做的檢查網站404無效鏈接。
原理
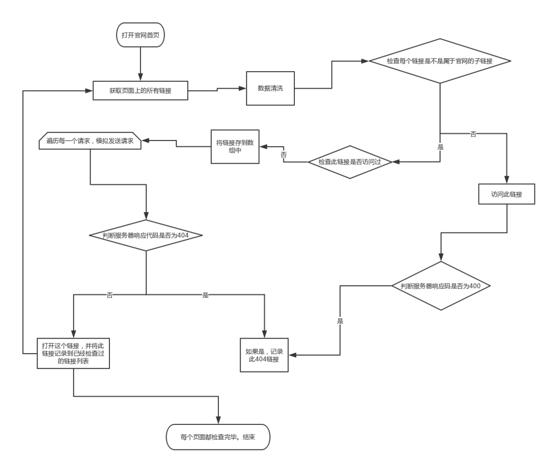
實現這樣的功能,大致分為以下步驟: 1.打開官網首頁,獲取頁面上所有的鏈接。 2.添加規則對這些鏈接過濾,把外鏈去掉。 3.遍歷訪問這些鏈接,打開打開其中的每一個鏈接,檢查是否為404,如果是距離下來。 4.重復執行1,2,3。直到把整個網站所有的鏈接都遍歷完。
準備
CukeTest 一款可以專業的編輯自動化腳本的工具。cuketest.com/
puppeteer 一個非常流行自動化庫。https://github.com/GoogleChrome/puppeteer
實現
CukeTest中新建一個項目。
刪掉features目錄。新建一個demo.js文件。
安裝puppeteer
npm install puppeteer --save
主要方法講解
pupputeer內置監聽事件,可以很快拿到每個請求的響應結果。
puppeteer可以創建Chromium實例。創建方式如下:
let puppeteer = require('puppeteer');
browser = await puppeteer.launch({ headless: true });
page = await browser.newPage();
await browser.close();puppeteer 提供事件監聽,可以監聽到每個頁面的響應狀態,為每個請求添加響應事件,如果響應狀態碼為404,記錄到文件中。
page.on('response',(res)=>{
// console.log("res.url", res.url(), res.status())
let url = res.url();
if(res.status()==404){
linktoFile(url, brokenlinkFile);
}else{
if(isvaildUrl(url)){
linktoFile(url,validUrlFilePath);
}
}
})puppeteer抓取頁面上所有的鏈接
await page.goto(url);
//獲取所有的link
const hrefs = await page.evaluate(
() => Array.from(document.body.querySelectorAll('a[href]'), ({ href }) => href)
);將鏈接記錄到文件或者從文件讀取鏈接的方法
let filetoLinks = function (filepath) {
if (!fs.existsSync(filepath)) {
fs.writeFileSync(filepath);
}
let data = fs.readFileSync(filepath, 'utf-8')
let links = data.trim().split('\n');
return links;
}
let linktoFile = function (link, filepath) {
let foundLinks = filetoLinks(filepath);
if (!foundLinks.includes(link)) {
fs.appendFileSync(filepath, link + '\n');
}
}最終代碼
let puppeteer = require('puppeteer');
const fs = require('fs');
const path = require('path');
const host = 'http://www.xxxx.cn/'; // 被測網站
const visitedFile = 'visitedUrl.txt'; //瀏覽過的頁面
const visitedFilePath = path.join(__dirname, visitedFile);
const brokenlinkFile = 'brokenLink.txt'; //404鏈接
const brokenlinkFilePath = path.join(__dirname, brokenlinkFile);
const validUrlFile = 'validUrlFile.txt'; //可用的鏈接
const validUrlFilePath = path.join(__dirname,validUrlFile);
let browser;
let page;
function isvaildUrl(url){
return url.startsWith(host) && !url.includes('/#');
}
async function run() {
browser = await puppeteer.launch({ headless: true });
page = await browser.newPage();
page.on('response',(res)=>{
// console.log("res.url", res.url(), res.status())
let url = res.url();
let currenturl = page.url()
if(res.status()==404){
linktoFile(currenturl+"=="+url, brokenlinkFilePath);
}else{
if(isvaildUrl(url)){
linktoFile(url,validUrlFilePath);
}
}
})
await visitPage(browser,page, host);
await browser.close();
}
async function visitPage(browser,page, url) {
// if (!isvaildUrl(url)) return;
await page.goto(url);
//獲取所有的link
const hrefs = await page.evaluate(
() => Array.from(document.body.querySelectorAll('a[href]'), ({ href }) => href)
);
for (const href of hrefs) {
//數據清洗
if (isvaildUrl(href) && href !== host) {
//符合條件的link
// linktoFile(href, visitedFilePath);
let res = await page.goto(href);
if (res && res.status() == 404) {
linktoFile(href, brokenlinkFilePath);
} else {
let visitedlinks = filetoLinks(visitedFilePath);
if(!visitedlinks.includes(href)){
linktoFile(href, visitedFilePath);
await visitPage(browser,page,href);
}
}
let links = filetoLinks(visitedFilePath);
if (!links.includes(href)) {
await visitPage(browser,page, href);
}
}
}
}
let filetoLinks = function (filepath) {
if (!fs.existsSync(filepath)) {
fs.writeFileSync(filepath);
}
let data = fs.readFileSync(filepath, 'utf-8')
let links = data.trim().split('\n');
return links;
}
let linktoFile = function (link, filepath) {
let foundLinks = filetoLinks(filepath);
if (!foundLinks.includes(link)) {
fs.appendFileSync(filepath, link + '\n');
}
}
run();運行
點擊 【運行】按鈕即可運行。 同樣,在CukeTest中也支持命令行執行,執行命令為
cuke --runjs demo.js
以上是“如何使用puppeteer爬取網站并抓出404無效鏈接”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





