溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
使用pandas怎么去重復行?相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
數據幀作為一個例子:
import pandas as pd
data=pd.DataFrame({'產品':['A','A','A','A'],'數量':[50,50,30,30]})pandas判斷dataframe是否含有重復行數據用:df.duplicated()
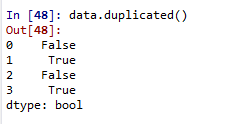
第一次出現的數據為False.重復的數據行就被記錄為True。
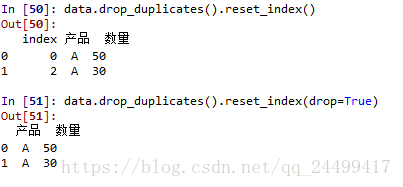
去掉重復行數據使用data.drop_duplicates().

可以看到索引亂了,我們使用data.reset_index(),里面的參數drop=True,表明要舍掉原來的索引,不然的話原來的索引會保留下來。
分類匯總主要使用groupby(表明匯總的條件列)以及agg(要匯總的字段/列以及匯總的方式:求和還是最大最小值或者計數)。完整代碼如下圖
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 20 09:08:10 2018
@author: FanXiaoLei
"""
import pandas as pd
data=pd.DataFrame({'產品':['A','A','A','A'],'數量':[50,50,30,30]})
if data.duplicated:
dataA=data.drop_duplicates().reset_index(drop=True)
print(dataA)
dataB=dataA.groupby(by='產品').agg({'數量':sum})
print('數據匯總結果:')
print(dataB)結果展示如下圖:

看完上述內容,你們掌握使用pandas怎么去重復行的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





