溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文實例講述了Python實現爬取馬云的微博功能。分享給大家供大家參考,具體如下:
分析請求
我們打開 Ajax 的 XHR 過濾器,然后一直滑動頁面加載新的微博內容,可以看到會不斷有Ajax請求發出。
我們選定其中一個請求來分析一下它的參數信息,點擊該請求進入詳情頁面,如圖所示:

可以發現這是一個 GET 請求,請求的參數有 6 個:display、retcode、type、value、containerid 和 page,觀察這些請求可以發現只有 page 在變化,很明顯 page 是用來控制分頁的。
分析響應
如圖所示:
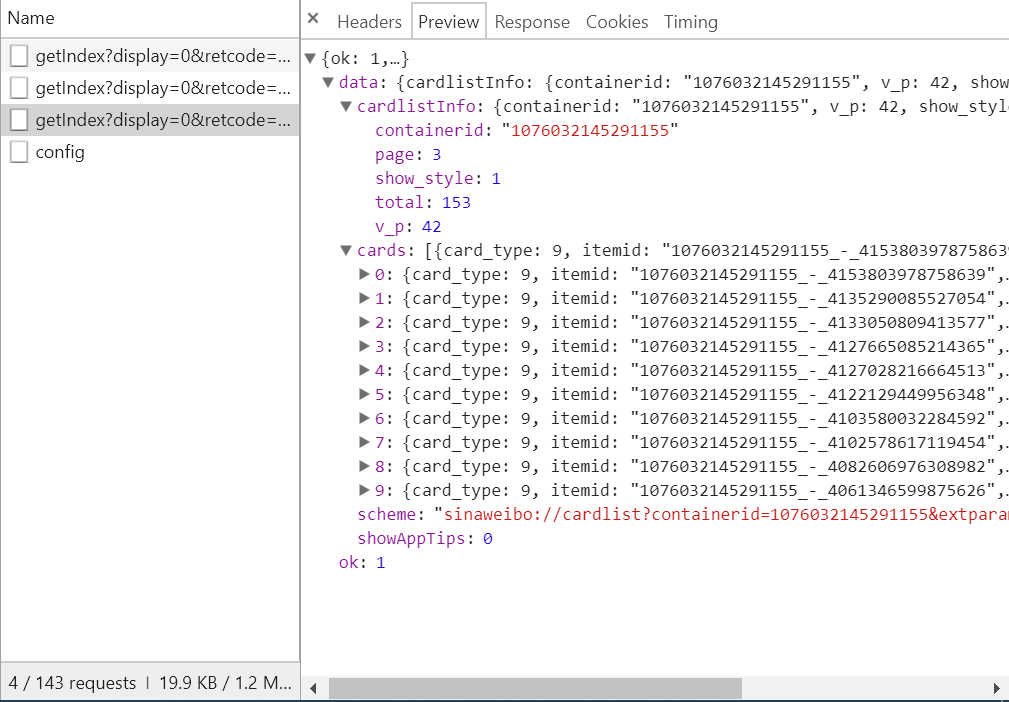
它是一個 Json 格式,瀏覽器開發者工具自動為做了解析方便我們查看,可以看到最關鍵的兩部分信息就是 cardlistInfo 和 cards,將二者展開,cardlistInfo 里面包含了一個比較重要的信息就是 total,經過觀察后發現其實它是微博的總數量,我們可以根據這個數字來估算出分頁的數目。
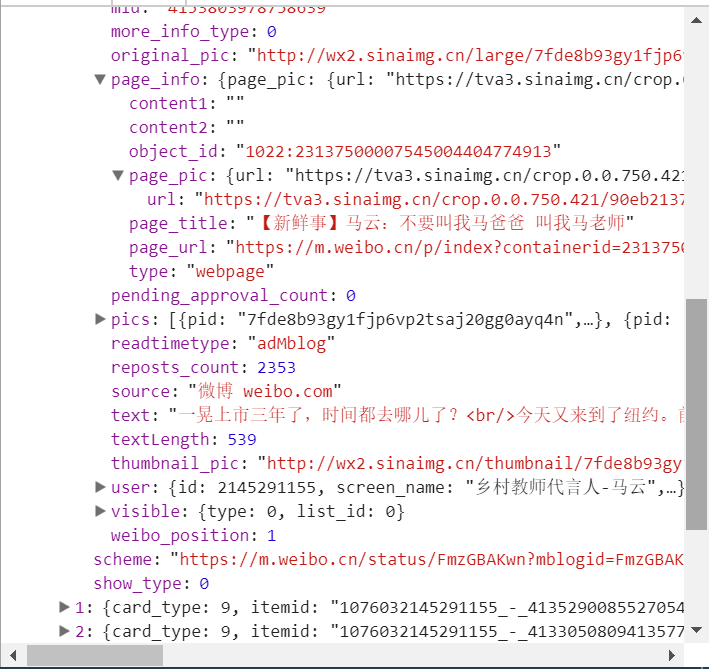
發現它又有一個比較重要的字段,叫做 mblog,繼續把它展開,發現它包含的正是微博的一些信息。比如 attitudes_count 贊數目、comments_count 評論數目、reposts_count 轉發數目、created_at 發布時間、text 微博正文等等,得來全不費功夫,而且都是一些格式化的內容,所以我們提取信息也更加方便了。
這樣我們可以請求一個接口就得到 10 條微博,而且請求的時候只需要改變 page 參數即可。這樣我們只需要簡單做一個循環就可以獲取到所有的微博了。
實戰演練
在這里我們就開始用程序來模擬這些 Ajax 請求,將馬云的所有微博全部爬取下來。
首先我們定義一個方法,來獲取每次請求的結果,在請求時page 是一個可變參數,所以我們將它作為方法的參數傳遞進來,代碼如下:
from urllib.parse import urlencode
import requests
base_url = 'https://m.weibo.cn/api/container/getIndex?'
headers = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/u/2145291155',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
def get_page(page):
params = {
'display': '0',
'retcode': '6102',
'type': 'uid',
'value': '2145291155',
'containerid': '1076032145291155',
'page': page
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
首先在這里我們定義了一個 base_url 來表示請求的 URL 的前半部分,接下來構造了一個參數字典,其中 display、retcode、 type、value、containerid 是固定的參數,只有 page 是可變參數,接下來我們調用了 urlencode() 方法將參數轉化為 URL 的 GET請求參數,即類似于display=0&retcode=6102&type=uid&value=2145291155&containerid=1076032145291155&page=2 這樣的形式,隨后 base_url 與參數拼合形成一個新的 URL,然后我們用 Requests 請求這個鏈接,加入 headers 參數,然后判斷響應的狀態碼,如果是200,則直接調用 json() 方法將內容解析為 Json 返回,否則不返回任何信息,如果出現異常則捕獲并輸出其異常信息。
隨后我們需要定義一個解析方法,用來從結果中提取我們想要的信息,比如我們這次想保存微博的 正文、贊數、評論數、轉發數這幾個內容,那可以先將 cards 遍歷,然后獲取 mblog 中的各個信息,賦值為一個新的字典返回即可。
from pyquery import PyQuery as pq
def parse_page(json):
if json:
items = json.get('cards')
for item in items:
item = item.get('mblog')
weibo = {}
weibo['微博內容:'] = pq(item.get('text')).text()
weibo['轉發數'] = item.get('attitudes_count')
weibo['評論數'] = item.get('comments_count')
weibo['點贊數'] = item.get('reposts_count')
yield weibo
在這里我們借助于 PyQuery 將正文中的 HTML 標簽去除掉。
最后我們遍歷一下 page,將提取到的結果打印輸出即可。
if __name__ == '__main__':
for page in range(1, 50):
json = get_page(page)
results = parse_page(json)
for result in results:
print(result)
另外我們還可以加一個方法將結果保存到 本地 TXT 文件中。
def save_to_txt(result):
with open('馬云的微博.txt', 'a', encoding='utf-8') as file:
file.write(str(result) + '\n')
代碼整理
import requests
from urllib.parse import urlencode
from pyquery import PyQuery as pq
base_url = 'https://m.weibo.cn/api/container/getIndex?'
headers = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/u/2145291155',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
max_page = 50
def get_page(page):
params = {
'display': '0',
'retcode': '6102',
'type': 'uid',
'value': '2145291155',
'containerid': '1076032145291155',
'page': page
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json(), page
except requests.ConnectionError as e:
print('Error', e.args)
def parse_page(json, page: int):
if json:
items = json.get('data').get('cards')
for index, item in enumerate(items):
if page == 1 and index == 1:
continue
else:
item = item.get('mblog')
weibo = {}
weibo['微博內容:'] = pq(item.get('text')).text()
weibo['轉發數:'] = item.get('attitudes_count')
weibo['評論數:'] = item.get('comments_count')
weibo['點贊數:'] = item.get('reposts_count')
yield weibo
def save_to_txt(result):
with open('馬云的微博.txt', 'a', encoding='utf-8') as file:
file.write(str(result) + '\n')
if __name__ == '__main__':
for page in range(1, max_page + 1):
json = get_page(page)
results = parse_page(*json)
for result in results:
print(result)
save_to_txt(result)
最后結果為:
{'微博內容:': '公安部兒童失蹤信息緊急發布平臺,現在有了階段性成果。上線兩年時間,發布3053名兒童失蹤信息,找回兒童2980名,找回率97.6%……失蹤兒童信息會觸達到幾乎每一個有手機的用戶,這對拐賣兒童的犯罪分子更是巨大的震懾!\n為找回孩子的家長欣慰,為這個“互聯網+打拐”平臺的創建而感動,也 ...全文', '轉發數:': 82727, '評論數:': 9756, '點贊數:': 18091}
{'微博內容:': '#馬云鄉村教師獎#說個喜事:馬云鄉村教師獎的獲獎老師丁茂洲,元旦新婚,新娘也是一名教師。丁老師坦白,他是2015年得了鄉村教師獎以后,才被現在的女朋友給“瞄上的”。其實馬云鄉村教師獎,不光女朋友喜歡,重要的是丈母娘也喜歡!\n丁老師的學校,陜西安康市三星小學,在一個貧困 ...全文', '轉發數:': 37030, '評論數:': 8176, '點贊數:': 3931}
{'微博內容:': '雙十一結束了,想對300萬快遞員、對所有物流合作伙伴說聲謝謝!你們創造了世界商業的奇跡!雙十一的三天里產生了10億多個包裹,菜鳥網絡用了一周的時間送完,抵達世界各個角落,這是世界貨運業的奇跡,更是商業世界協同合作的奇跡。10年前,我們不敢想象中國快遞 ...全文', '轉發數:': 85224, '評論數:': 21615, '點贊數:': 5044}
{'微博內容:': '今晚11.11,準備好了嗎?注意休息,開心快樂。姑娘們,今晚是你們的節日。男人們,反正錢是用來花的,花錢不心疼的日子只有今天!', '轉發數:': 76803, '評論數:': 22068, '點贊數:': 4773}
本文參考崔慶才的《python3 網絡爬蟲開發實戰》。
更多關于Python相關內容可查看本站專題:《Python Socket編程技巧總結》、《Python正則表達式用法總結》、《Python數據結構與算法教程》、《Python函數使用技巧總結》、《Python字符串操作技巧匯總》、《Python入門與進階經典教程》及《Python文件與目錄操作技巧匯總》
希望本文所述對大家Python程序設計有所幫助。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





