溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
介紹
本文將介紹我是如何在python爬蟲里面一步一步踩坑,然后慢慢走出來的,期間碰到的所有問題我都會詳細說明,讓大家以后碰到這些問題時能夠快速確定問題的來源,后面的代碼只是貼出了核心代碼,更詳細的代碼暫時沒有貼出來。
流程一覽
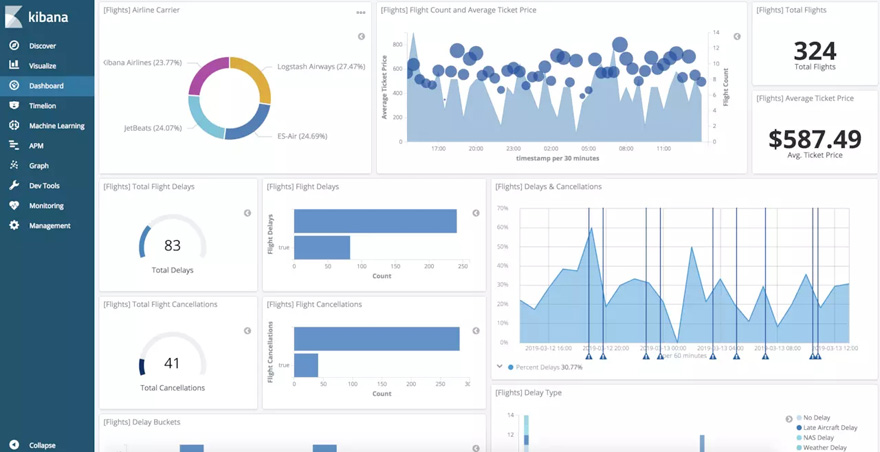
首先我是想爬某個網站上面的所有文章內容,但是由于之前沒有做過爬蟲(也不知道到底那個語言最方便),所以這里想到了是用python來做一個爬蟲(畢竟人家的名字都帶有爬蟲的含義😄),我這邊是打算先將所有從網站上爬下來的數據放到ElasticSearch里面, 選擇ElasticSearch的原因是速度快,里面分詞插件,倒排索引,需要數據的時候查詢效率會非常好(畢竟爬的東西比較多😄),然后我會將所有的數據在ElasticSearch的老婆kibana里面將數據進行可視化出來,并且分析這些文章內容,可以先看一下預期可視化的效果(上圖了),這個效果圖是kibana6.4系統給予的幫助效果圖(就是說你可以弄成這樣,我也想弄成這樣😁)。后面我會發一個dockerfile上來(現在還沒弄😳)。
環境需求
這些東西可以去找相應的教程安裝,我這里只有ElasticSearch的安裝😢點我獲取安裝教程
第一步,使用python的pip來安裝需要的插件(第一個坑在這兒)
1.tomd:將html轉換成markdown
pip3 install tomd
2.redis:需要python的redis插件
pip3 install redis
3.scrapy:框架安裝(坑)
1、首先我是像上面一樣執行了
pip3 install scrapy
2、然后發現缺少gcc組件 error: command 'gcc' failed with exit status 1
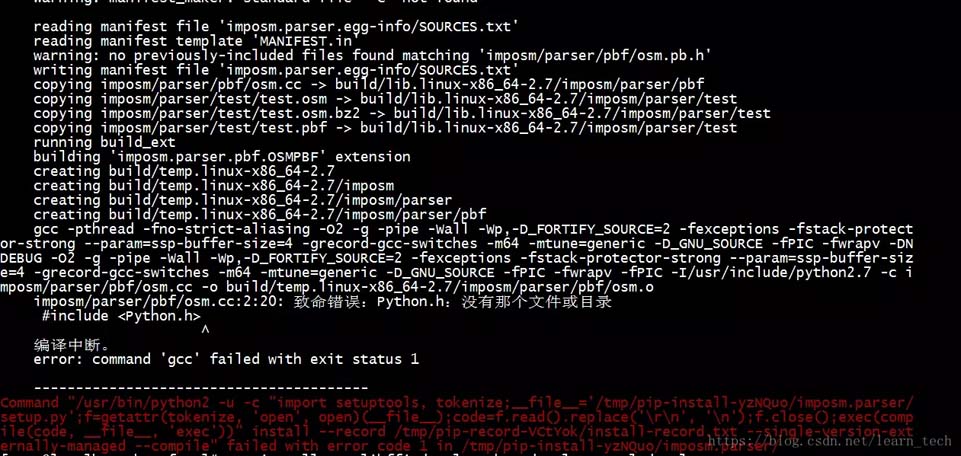
3、然后我就找啊找,找啊找,最后終于找到了正確的解決方法(期間試了很多錯誤答案😭)。最終的解決辦法就是使用yum來安裝python34-devel, 這個python34-devel根據你自己的python版本來,可能是python-devel,是多少版本就將中間的34改成你的版本, 我的是3.4.6
yum install python34-devel
4、安裝完成過后使用命令 scrapy 來試試吧。
第二步,使用scrapy來創建你的項目
輸入命令scrapy startproject scrapyDemo, 來創建一個爬蟲項目
liaochengdeMacBook-Pro:scrapy liaocheng$ scrapy startproject scrapyDemo New Scrapy project 'scrapyDemo', using template directory '/usr/local/lib/python3.7/site-packages/scrapy/templates/project', created in: /Users/liaocheng/script/scrapy/scrapyDemo You can start your first spider with: cd scrapyDemo scrapy genspider example example.com liaochengdeMacBook-Pro:scrapy liaocheng$
使用genspider來生成一個基礎的spider,使用命令scrapy genspider demo juejin.im, 后面這個網址是你要爬的網站,我們先爬自己家的😂
liaochengdeMacBook-Pro:scrapy liaocheng$ scrapy genspider demo juejin.im Created spider 'demo' using template 'basic' liaochengdeMacBook-Pro:scrapy liaocheng$
查看生成的目錄結構
第三步,打開項目,開始編碼
查看生成的的demo.py的內容
# -*- coding: utf-8 -*- import scrapy class DemoSpider(scrapy.Spider): name = 'demo' ## 爬蟲的名字 allowed_domains = ['juejin.im'] ## 需要過濾的域名,也就是只爬這個網址下面的內容 start_urls = ['https://juejin.im/post/5c790b4b51882545194f84f0'] ## 初始url鏈接 def parse(self, response): ## 如果新建的spider必須實現這個方法 pass
可以使用第二種方式,將start_urls給提出來
# -*- coding: utf-8 -*- import scrapy class DemoSpider(scrapy.Spider): name = 'demo' ## 爬蟲的名字 allowed_domains = ['juejin.im'] ## 需要過濾的域名,也就是只爬這個網址下面的內容 def start_requests(self): start_urls = ['http://juejin.im/'] ## 初始url鏈接 for url in start_urls: # 調用parse yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): ## 如果新建的spider必須實現這個方法 pass
編寫articleItem.py文件(item文件就類似java里面的實體類)
import scrapy class ArticleItem(scrapy.Item): ## 需要實現scrapy.Item文件 # 文章id id = scrapy.Field() # 文章標題 title = scrapy.Field() # 文章內容 content = scrapy.Field() # 作者 author = scrapy.Field() # 發布時間 createTime = scrapy.Field() # 閱讀量 readNum = scrapy.Field() # 點贊數 praise = scrapy.Field() # 頭像 photo = scrapy.Field() # 評論數 commentNum = scrapy.Field() # 文章鏈接 link = scrapy.Field()
編寫parse方法的代碼
def parse(self, response):
# 獲取頁面上所有的url
nextPage = response.css("a::attr(href)").extract()
# 遍歷頁面上所有的url鏈接,時間復雜度為O(n)
for i in nextPage:
if nextPage is not None:
# 將鏈接拼起來
url = response.urljoin(i)
# 必須是掘金的鏈接才進入
if "juejin.im" in str(url):
# 存入redis,如果能存進去,就是一個沒有爬過的鏈接
if self.insertRedis(url) == True:
# dont_filter作用是是否過濾相同url true是不過濾,false為過濾,我們這里只爬一個頁面就行了,不用全站爬,全站爬對對掘金不是很友好,我么這里只是用來測試的
yield scrapy.Request(url=url, callback=self.parse,headers=self.headers,dont_filter=False)
# 我們只分析文章,其他的內容都不管
if "/post/" in response.url and "#comment" not in response.url:
# 創建我們剛才的ArticleItem
article = ArticleItem()
# 文章id作為id
article['id'] = str(response.url).split("/")[-1]
# 標題
article['title'] = response.css("#juejin > div.view-container > main > div > div.main-area.article-area.shadow > article > h2::text").extract_first()
# 內容
parameter = response.css("#juejin > div.view-container > main > div > div.main-area.article-area.shadow > article > div.article-content").extract_first()
article['content'] = self.parseToMarkdown(parameter)
# 作者
article['author'] = response.css("#juejin > div.view-container > main > div > div.main-area.article-area.shadow > article > div:nth-child(6) > meta:nth-child(1)::attr(content)").extract_first()
# 創建時間
createTime = response.css("#juejin > div.view-container > main > div > div.main-area.article-area.shadow > article > div.author-info-block > div > div > time::text").extract_first()
createTime = str(createTime).replace("年", "-").replace("月", "-").replace("日","")
article['createTime'] = createTime
# 閱讀量
article['readNum'] = int(str(response.css("#juejin > div.view-container > main > div > div.main-area.article-area.shadow > article > div.author-info-block > div > div > span::text").extract_first()).split(" ")[1])
# 點贊數
article['badge'] = response.css("#juejin > div.view-container > main > div > div.article-suspended-panel.article-suspended-panel > div.like-btn.panel-btn.like-adjust.with-badge::attr(badge)").extract_first()
# 評論數
article['commentNum'] = response.css("#juejin > div.view-container > main > div > div.article-suspended-panel.article-suspended-panel > div.comment-btn.panel-btn.comment-adjust.with-badge::attr(badge)").extract_first()
# 文章鏈接
article['link'] = response.url
# 這個方法和很重要(坑),之前就是由于執行yield article, pipeline就一直不能獲取數據
yield article
# 將內容轉換成markdown
def parseToMarkdown(self, param):
return tomd.Tomd(str(param)).markdown
# url 存入redis,如果能存那么就沒有該鏈接,如果不能存,那么就存在該鏈接
def insertRedis(self, url):
if self.redis != None:
return self.redis.sadd("articleUrlList", url) == 1
else:
self.redis = self.redisConnection.getClient()
self.insertRedis(url)
編寫pipeline類,這個pipeline是一個管道,可以將所有yield關鍵字返回的數據都交給這個管道處理,但是需要在settings里面配置一下pipeline才行
from elasticsearch import Elasticsearch
class ArticlePipelines(object):
# 初始化
def __init__(self):
# elasticsearch的index
self.index = "article"
# elasticsearch的type
self.type = "type"
# elasticsearch的ip加端口
self.es = Elasticsearch(hosts="localhost:9200")
# 必須實現的方法,用來處理yield返回的數據
def process_item(self, item, spider):
# 這里是判斷,如果是demo這個爬蟲的數據才處理
if spider.name != "demo":
return item
result = self.checkDocumentExists(item)
if result == False:
self.createDocument(item)
else:
self.updateDocument(item)
# 添加文檔
def createDocument(self, item):
body = {
"title": item['title'],
"content": item['content'],
"author": item['author'],
"createTime": item['createTime'],
"readNum": item['readNum'],
"praise": item['praise'],
"link": item['link'],
"commentNum": item['commentNum']
}
try:
self.es.create(index=self.index, doc_type=self.type, id=item["id"], body=body)
except:
pass
# 更新文檔
def updateDocument(self, item):
parm = {
"doc" : {
"readNum" : item['readNum'],
"praise" : item['praise']
}
}
try:
self.es.update(index=self.index, doc_type=self.type, id=item["id"], body=parm)
except:
pass
# 檢查文檔是否存在
def checkDocumentExists(self, item):
try:
self.es.get(self.index, self.type, item["id"])
return True
except:
return False
第四步,運行代碼查看效果
使用scrapy list查看本地的所有爬蟲
liaochengdeMacBook-Pro:scrapyDemo liaocheng$ scrapy list demo liaochengdeMacBook-Pro:scrapyDemo liaocheng$
使用scrapy crawl demo來運行爬蟲
scrapy crawl demo
到kibana里面看爬到的數據,執行下面的命令可以看到數據
GET /article/_search
{
"query": {
"match_all": {}
}
}
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "article2",
"_type": "type",
"_id": "5c790b4b51882545194f84f0",
"_score": 1,
"_source": {}
}
]
}
}
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作具有一定的參考學習價值,謝謝大家對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





