溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
最近在學習python爬蟲,看到網上有很多關于模擬豆瓣登錄的例子,隨意找了一個試了下,發現不能運行,對比了一下代碼和豆瓣網站,發現原來是豆瓣網站做了修改,增加了反爬措施。
首先看下要模擬登錄的網站:
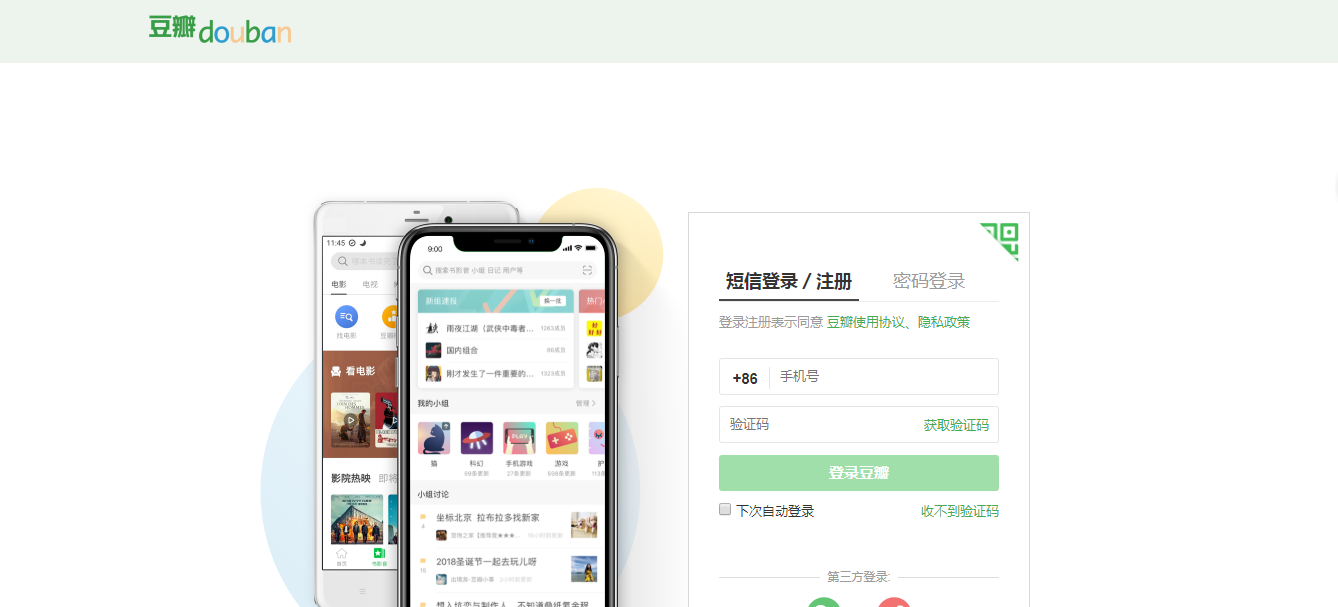
打開開發者模式:
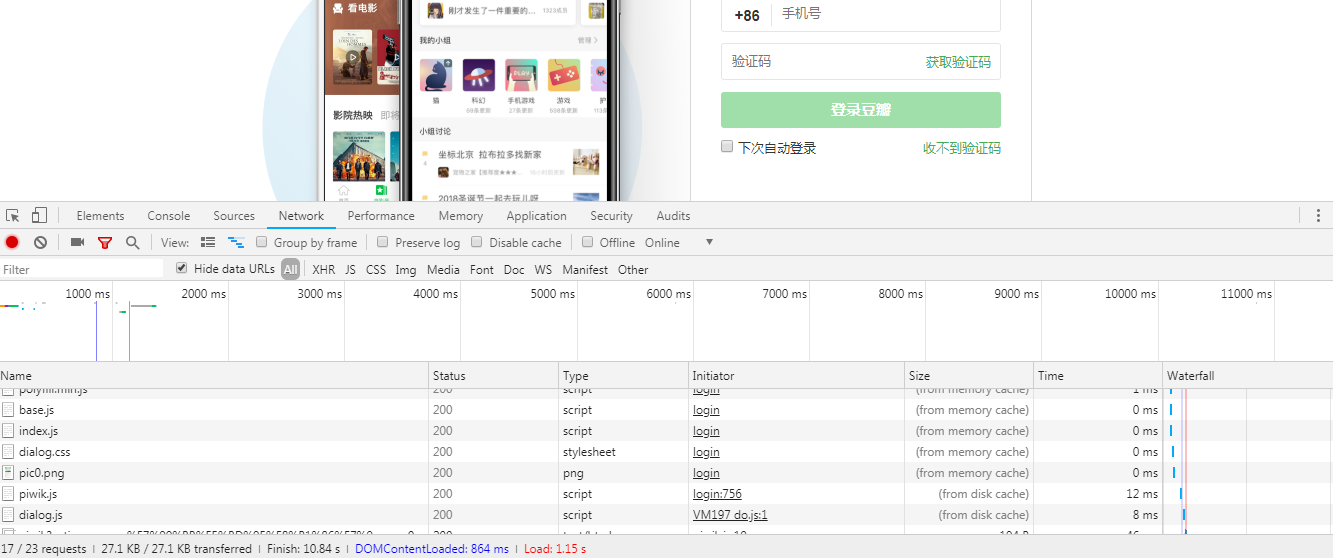
在賬號和密碼隨意填入數據:
發現會發送一個post請求:
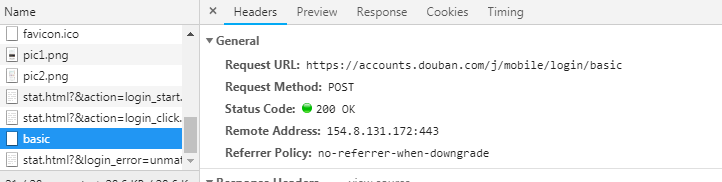
ur是:https://accounts.douban.com/j/mobile/login/basic
數據格式是:
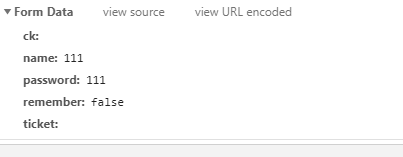
于是可以來編寫代碼:
import requests
def main():
url_basic = 'https://accounts.douban.com/j/mobile/login/basic'
url = 'https://www.douban.com/'
ua_headers = { "User-Agent":'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)'}
data = {
'ck': '',
'name': '自己的賬號',
'password': '自己的密碼',
'remember': 'false',
'ticket': ''
}
s = requests.session()
s.post(url=url_basic, headers=ua_headers, data=data)
response = s.get(url=url, headers=ua_headers)
with open('douban.html' , 'wb') as f:
f.write(response.content)
if __name__ == '__main__':
main()
第一步:
創建 s = requests.session()
作用是跨請求保持參數,也就是說s這個session對象所發出的所有請求之間會保持cookies
第二步:
用創建好的session對象攜帶賬號,密碼去發送post請求。
由于改版后的豆瓣返回的是一個josn數據,而不是像以前一樣重定向,所以需要我們來重定向。
第三步:
攜帶登錄成功保存的cookie去訪問首頁,就會得到你自己的首頁.
最后得到個人首頁:
以上所述是小編給大家介紹的python模擬豆瓣登錄詳解整合,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對億速云網站的支持!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





