溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了mysql中完整的select語句的用法,內容清晰明了,對此有興趣的小伙伴可以學習一下,相信大家閱讀完之后會有幫助。
完整語法:
先給一下完整的語法,后面將逐一來講解。
基礎語法:select 字段列表 from 數據源;
完整語法:select 去重選項 字段列表 [as 字段別名] from 數據源 [where子句] [group by 子句] [having子句] [order by 子句] [limit子句];
示例:
去重前: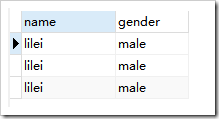 ,去重后
,去重后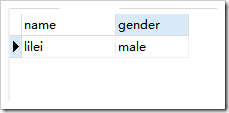
create table student(name varchar(15),gender varchar(15));
insert into student(name,gender) values("lilei","male");
insert into student(name,gender) values("lilei","male");
select * from student;
select distinct * from student;示例:
使用前: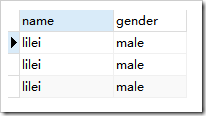 ,使用后
,使用后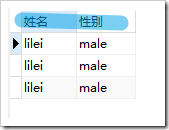
create table student(name varchar(15),gender varchar(15));
insert into student(name,gender) values("lilei","male");
insert into student(name,gender) values("lilei","male");
select * from student;
select name as "姓名",gender as "性別" from student;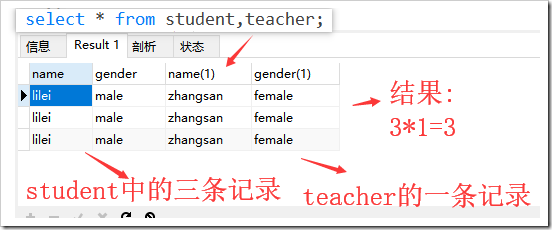
-- 示例 select name from (select * from student) as d;
where幾種語法:
select name as n ,gender from student where name ="lilei"; -- select name as n ,gender from student where n ="lilei"; --報錯 select name as n ,gender from student having n ="lilei";

-- 示例 select name,gender,count(name) as "組員" from student as d group by name; select name,gender,count(name) as "組員" from student as d group by name,gender;
-- 示例 select name as n ,gender from student having n ="lilei"; select name,gender,count(*) as "組員" from student as d group by name,gender having count(*) >2 ;-- 這里只顯示記錄數>2的分組
-- 示例 select * from student order by name; select * from student order by name,gender; select * from student order by name asc,gender desc;
-- 示例 select * from student limit 1; select * from student limit 3,1; select * from student where name ="lilei" limit 1; select * from student where name ="lilei" limit 3,1;
看完上述內容,是不是對mysql中完整的select語句的用法有進一步的了解,如果還想學習更多內容,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





