溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
怎么在Python中使用PyQt5實現可視化爬蟲工具?很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
Python主要應用于:1、Web開發;2、數據科學研究;3、網絡爬蟲;4、嵌入式應用開發;5、游戲開發;6、桌面應用開發。
import urllib.request
from urllib import parse
from lxml import etree
import ssl
from PyQt5.QtWidgets import QApplication, QWidget, QLineEdit, QTextEdit, QVBoxLayout, QPushButton, QMessageBox
import sys
# 取消代理驗證
ssl._create_default_https_context = ssl._create_unverified_context
class TextEditMeiJu(QWidget):
def __init__(self, parent=None):
super(TextEditMeiJu, self).__init__(parent)
# 定義窗口頭部信息
self.setWindowTitle('美劇天堂')
# 定義窗口的初始大小
self.resize(500, 600)
# 創建單行文本框
self.textLineEdit = QLineEdit()
# 創建一個按鈕
self.btnButton = QPushButton('確定')
# 創建多行文本框
self.textEdit = QTextEdit()
# 實例化垂直布局
layout = QVBoxLayout()
# 相關控件添加到垂直布局中
layout.addWidget(self.textLineEdit)
layout.addWidget(self.btnButton)
layout.addWidget(self.textEdit)
# 設置布局
self.setLayout(layout)
# 將按鈕的點擊信號與相關的槽函數進行綁定,點擊即觸發
self.btnButton.clicked.connect(self.buttonClick)
# 點擊確認按鈕
def buttonClick(self):
# 爬取開始前提示一下
start = QMessageBox.information(
self, '提示', '是否開始爬取《' + self.textLineEdit.text() + "》",
QMessageBox.Ok | QMessageBox.No, QMessageBox.Ok
)
# 確定爬取
if start == QMessageBox.Ok:
self.page = 1
self.loadSearchPage(self.textLineEdit.text(), self.page)
# 取消爬取
else:
pass
# 加載輸入美劇名稱后的頁面
def loadSearchPage(self, name, page):
# 將文本轉為 gb2312 編碼格式
name = parse.quote(name.encode('gb2312'))
# 請求發送的 url 地址
url = "https://www.meijutt.com/search/index.asp?page=" + str(page) + "&searchword=" + name + "&searchtype=-1"
# 請求報頭
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"}
# 發送請求
request = urllib.request.Request(url, headers=headers)
# 獲取請求的 html 文檔
html = urllib.request.urlopen(request).read()
# 對 html 文檔進行解析
text = etree.HTML(html)
# xpath 獲取想要的信息
pageTotal = text.xpath('//div[@class="page"]/span[1]/text()')
# 判斷搜索內容是否有結果
if pageTotal:
self.loadDetailPage(pageTotal, text, headers)
# 搜索內容無結果
else:
self.infoSearchNull()
# 加載點擊搜索頁面點擊的本季頁面
def loadDetailPage(self, pageTotal, text, headers):
# 取出搜索的結果一共多少頁
pageTotal = pageTotal[0].split('/')[1].rstrip("頁")
# 獲取每一季的內容(劇名和鏈接)
node_list = text.xpath('//a[@class="B font_14"]')
items = {}
items['name'] = self.textLineEdit.text()
# 循環獲取每一季的內容
for node in node_list:
# 獲取信息
title = node.xpath('@title')[0]
link = node.xpath('@href')[0]
items["title"] = title
# 通過獲取的單季鏈接跳轉到本季的詳情頁面
requestDetail = urllib.request.Request("https://www.meijutt.com" + link, headers=headers)
htmlDetail = urllib.request.urlopen(requestDetail).read()
textDetail = etree.HTML(htmlDetail)
node_listDetail = textDetail.xpath('//div[@class="tabs-list current-tab"]//strong//a/@href')
self.writeDetailPage(items, node_listDetail)
# 爬取完畢提示
if self.page == int(pageTotal):
self.infoSearchDone()
else:
self.infoSearchContinue(pageTotal)
# 將數據顯示到圖形界面
def writeDetailPage(self, items, node_listDetail):
for index, nodeLink in enumerate(node_listDetail):
items["link"] = nodeLink
# 寫入圖形界面
self.textEdit.append(
"<div>"
"<font color='black' size='3'>" + items['name'] + "</font>" + "\n"
"<font color='red' size='3'>" + items['title'] + "</font>" + "\n"
"<font color='orange' size='3'>第" + str(index + 1) + "集</font>" + "\n"
"<font color='green' size='3'>下載鏈接:</font>" + "\n"
"<font color='blue' size='3'>" + items['link'] + "</font>"
"<p></p>"
"</div>"
)
# 搜索不到結果的提示信息
def infoSearchNull(self):
QMessageBox.information(
self, '提示', '搜索結果不存在,請重新輸入搜索內容',
QMessageBox.Ok, QMessageBox.Ok
)
# 爬取數據完畢的提示信息
def infoSearchDone(self):
QMessageBox.information(
self, '提示', '爬取《' + self.textLineEdit.text() + '》完畢',
QMessageBox.Ok, QMessageBox.Ok
)
# 多頁情況下是否繼續爬取的提示信息
def infoSearchContinue(self, pageTotal):
end = QMessageBox.information(
self, '提示', '爬取第' + str(self.page) + '頁《' + self.textLineEdit.text() + '》完畢,還有' + str(int(pageTotal) - self.page) + '頁,是否繼續爬取',
QMessageBox.Ok | QMessageBox.No, QMessageBox.No
)
if end == QMessageBox.Ok:
self.page += 1
self.loadSearchPage(self.textLineEdit.text(), self.page)
else:
pass
if __name__ == '__main__':
app = QApplication(sys.argv)
win = TextEditMeiJu()
win.show()
sys.exit(app.exec_())以上是實現功能的所有代碼,可以運行 Python 的小伙伴直接復制到本地運行即可。都說 Python 是做爬蟲最好的工具,寫完之后發現確實是這樣。
我們一點點分析代碼:
import urllib.request from urllib import parse from lxml import etree import ssl from PyQt5.QtWidgets import QApplication, QWidget, QLineEdit, QTextEdit, QVBoxLayout, QPushButton, QMessageBox, QLabel import sys
以上為我們引入的所需要的庫,前 4 行是爬取 美劇天堂 官網所需要的庫,后兩個是實現圖形化應用所需的庫。
我們先來看一下如何爬取網站信息。
由于現在 美劇天堂 使用的是 https 協議,進入頁面需要代理驗證,為了不必要的麻煩,我們干脆取消代理驗證,所以用到了 ssl 模塊。
然后我們就可以正大光明的進入網站了:
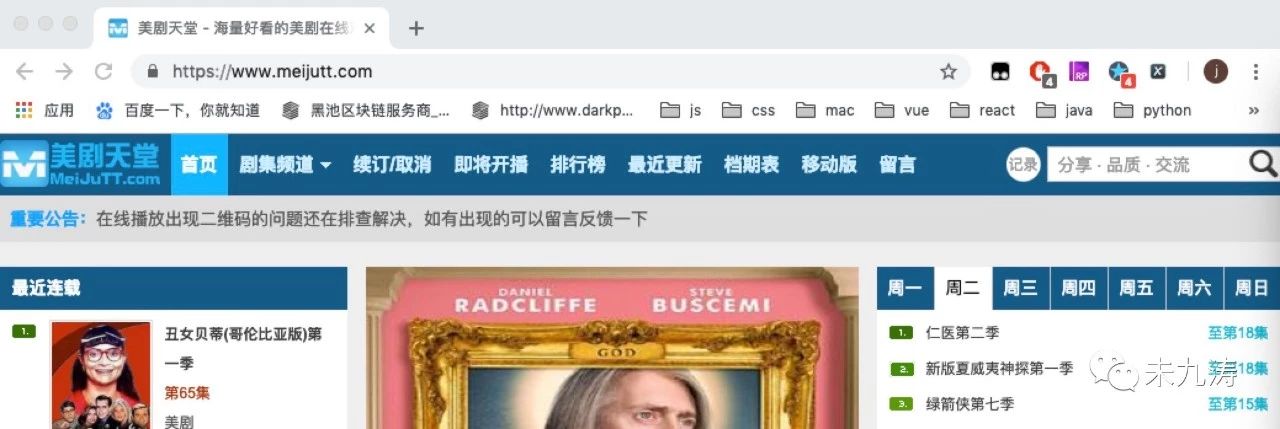
令人遺憾的是 url 鏈接為https://www.meijutt.com/search/index.asp,顯然沒有為我們提供任何有用的信息,當我們刷新頁面時,如下圖:
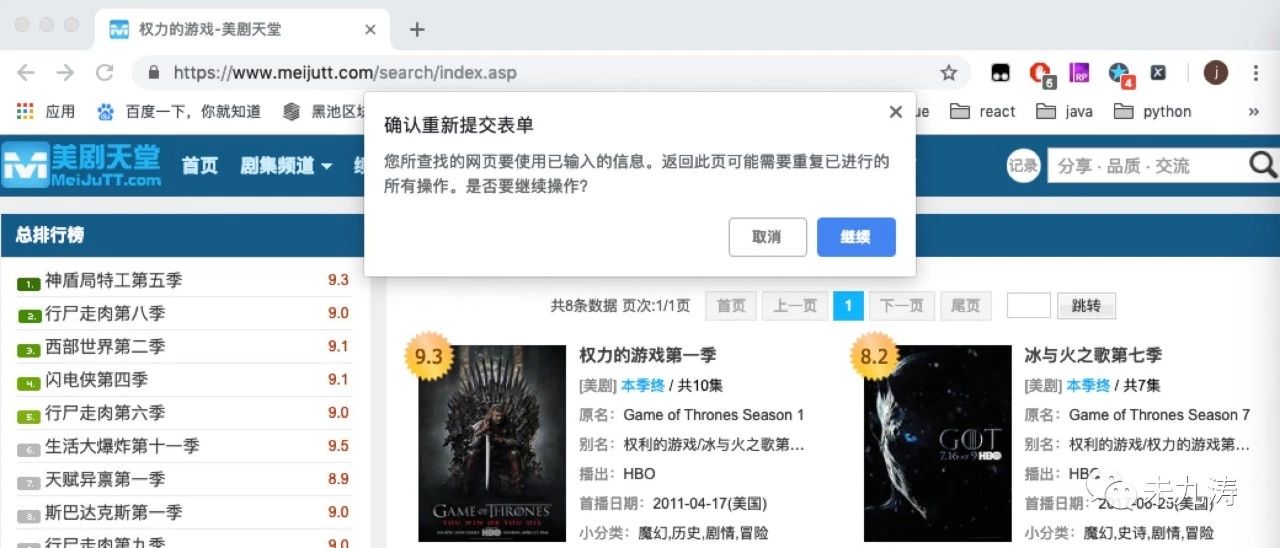
當我們手動輸入 ulr 鏈接https://www.meijutt.com/search/index.asp進行搜索時:
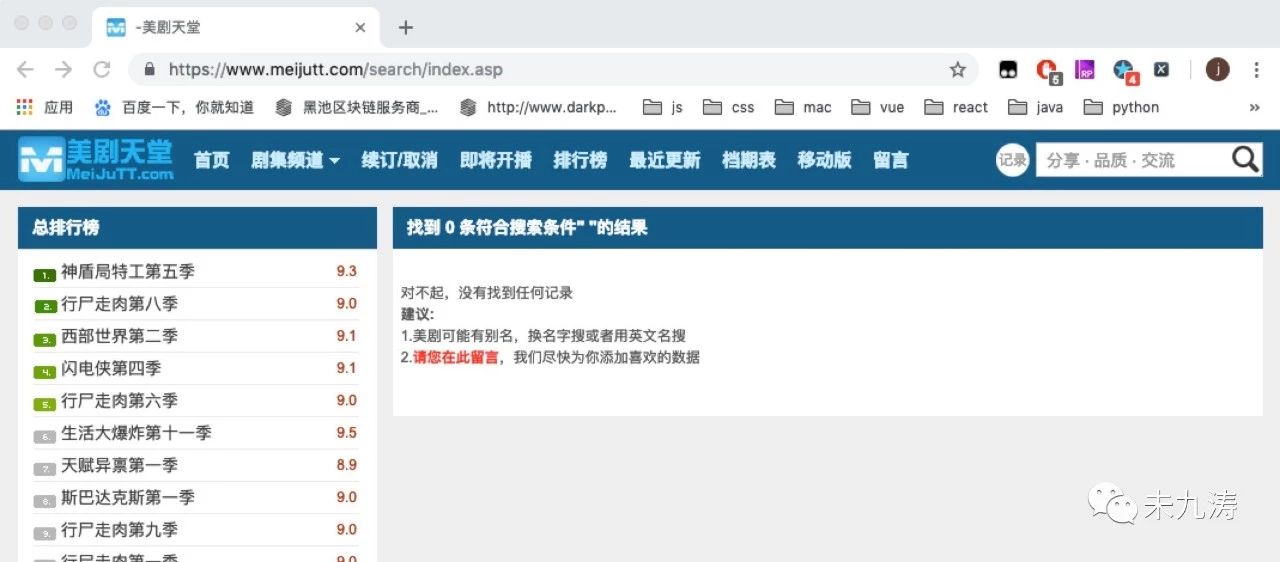
很明顯了,當我們在首頁輸入想看的美劇并搜索時網站將我們的請求表單信息隱藏了,并沒有給到 url 鏈接里,但是本人可不想每次都從首頁進行搜索再提交表單獲取信息,很不爽,還好本人發現了一個更好的方法。如下圖:
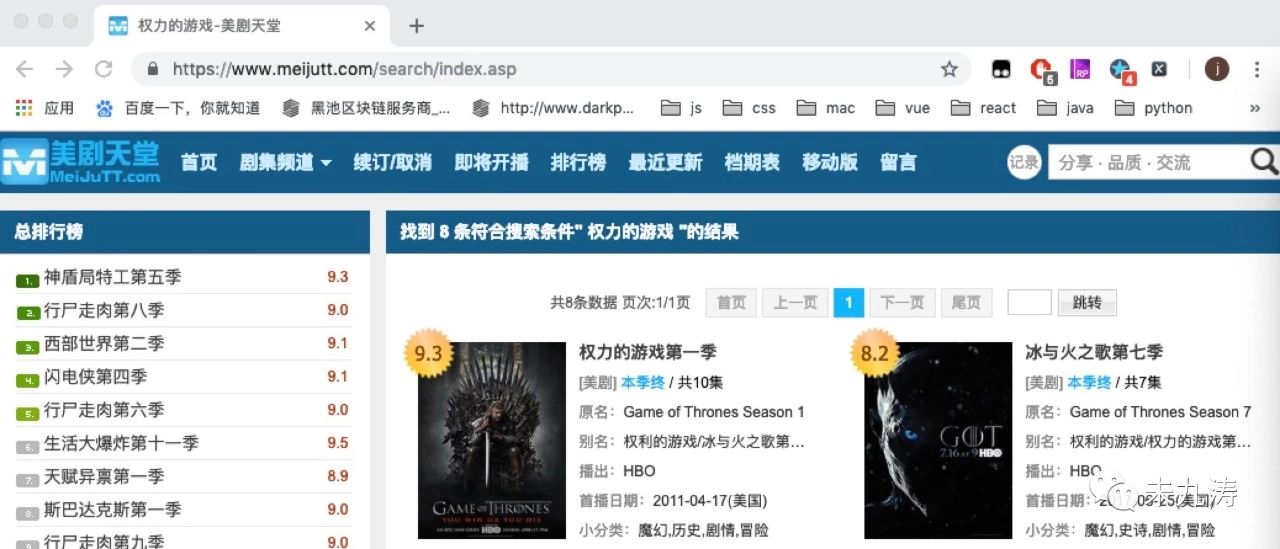
在頁面頂部有一個頁面跳轉的按鈕,我們可以選擇跳轉的頁碼,當選擇跳轉頁碼后,頁面變成了如下:
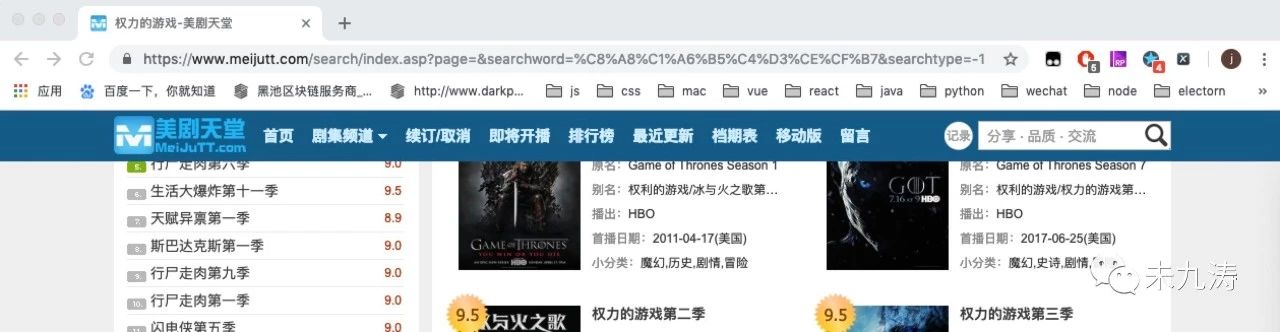
url 鏈接已經改變了:https://www.meijutt.com/search/index.asp?page=&searchword=%C8%A8%C1%A6%B5%C4%D3%CE%CF%B7&searchtype=-1
我們再將 page 中動態添加為page=1,頁面效果不變。
經過搜索多個不同的美劇的多次驗證發現只有 page 和 searchword 這兩個字段是改變的,其中 page 字段默認為 1 ,而其本人搜索了許多季數很長的美劇,比如《老友記》、《生活大爆炸》、《邪惡力量》,這些美劇也就一頁,但仍有更長的美劇,比如《辛普森一家》是兩頁,《法律與秩序》是兩頁,這就要求我們對頁數進行控制,但是需要特別注意的是如果隨意搜索內容,比如在搜索框只搜索了一個 ”i“,整整搜出了219頁,這要扒下來需要很長的時間,所以就需要對其搜索的頁數進行控制。
我們再來看一下 searchword 字段,將 searchword 字段解碼轉成漢字:
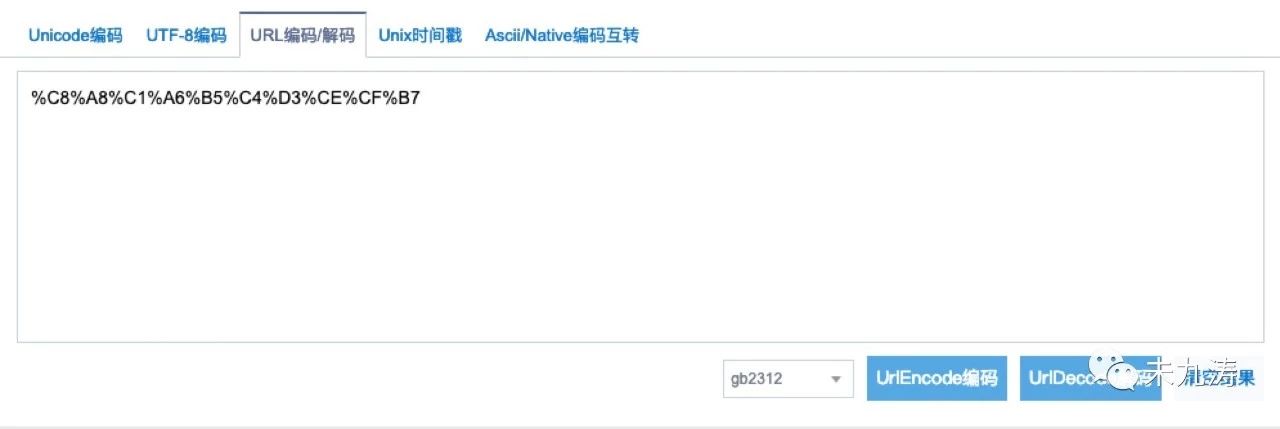
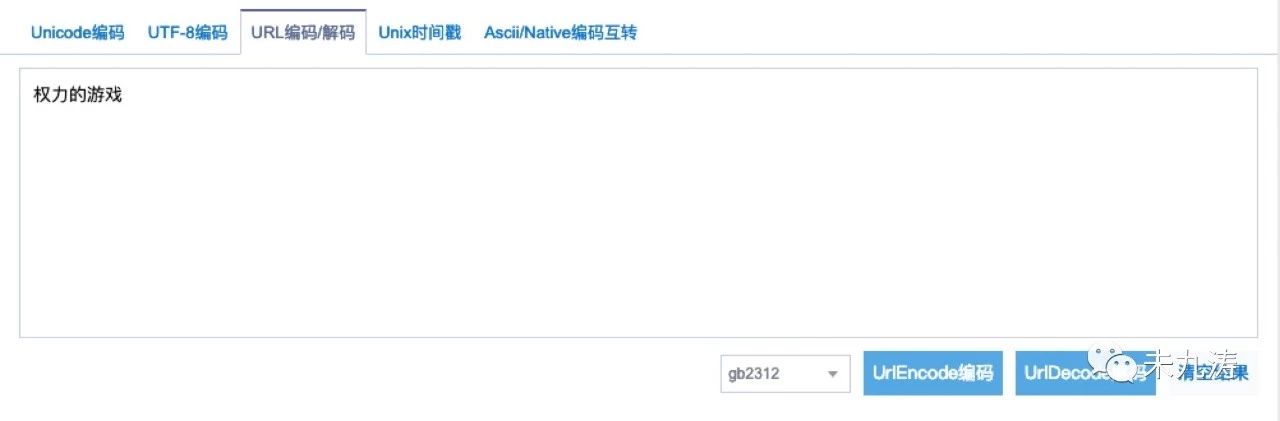
沒錯,正是我們想要的,萬里長征終于實現了第一步。
# 加載輸入美劇名稱后的頁面
def loadSearchPage(self, name, page):
# 將文本轉為 gb2312 編碼格式
name = parse.quote(name.encode('gb2312'))
# 請求發送的 url 地址
url = "https://www.meijutt.com/search/index.asp?page=" + str(page) + "&searchword=" + name + "&searchtype=-1"
# 請求報頭
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"}
# 發送請求
request = urllib.request.Request(url, headers=headers)
# 獲取請求的 html 文檔
html = urllib.request.urlopen(request).read()
# 對 html 文檔進行解析
text = etree.HTML(html)
# xpath 獲取想要的信息
pageTotal = text.xpath('//div[@class="page"]/span[1]/text()')
# 判斷搜索內容是否有結果
if pageTotal:
self.loadDetailPage(pageTotal, text, headers)
# 搜索內容無結果
else:
self.infoSearchNull()接下來我們只需要將輸入的美劇名轉化成 url 編碼格式就可以了。如上代碼,通過 urllib 庫對搜索的網站進行操作。
其中我們還需要做判斷,搜索結果是否存在,比如我們搜索 行尸跑肉,結果不存在。
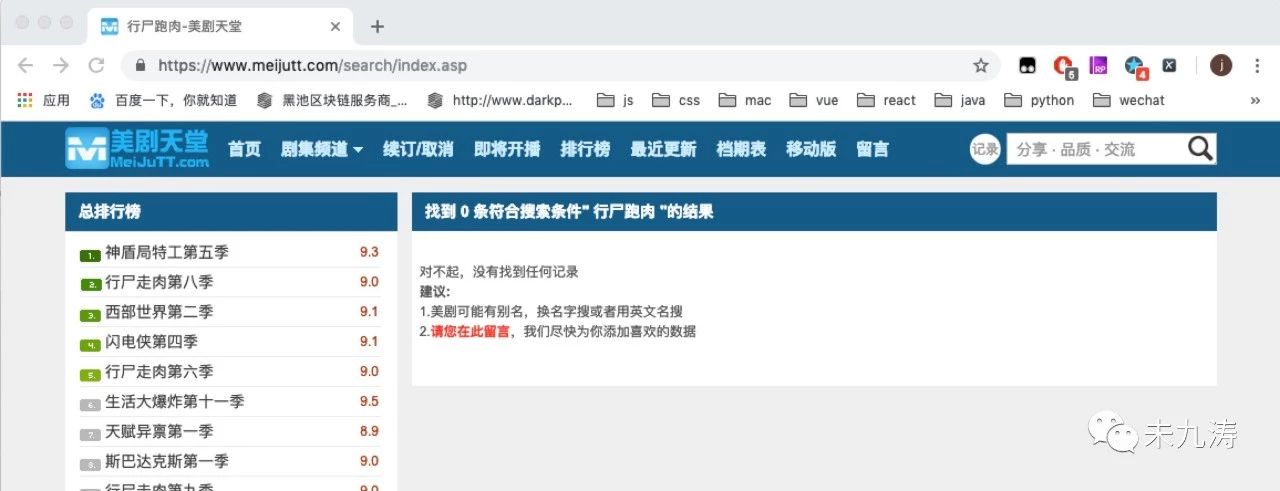
當搜索結果存在時:
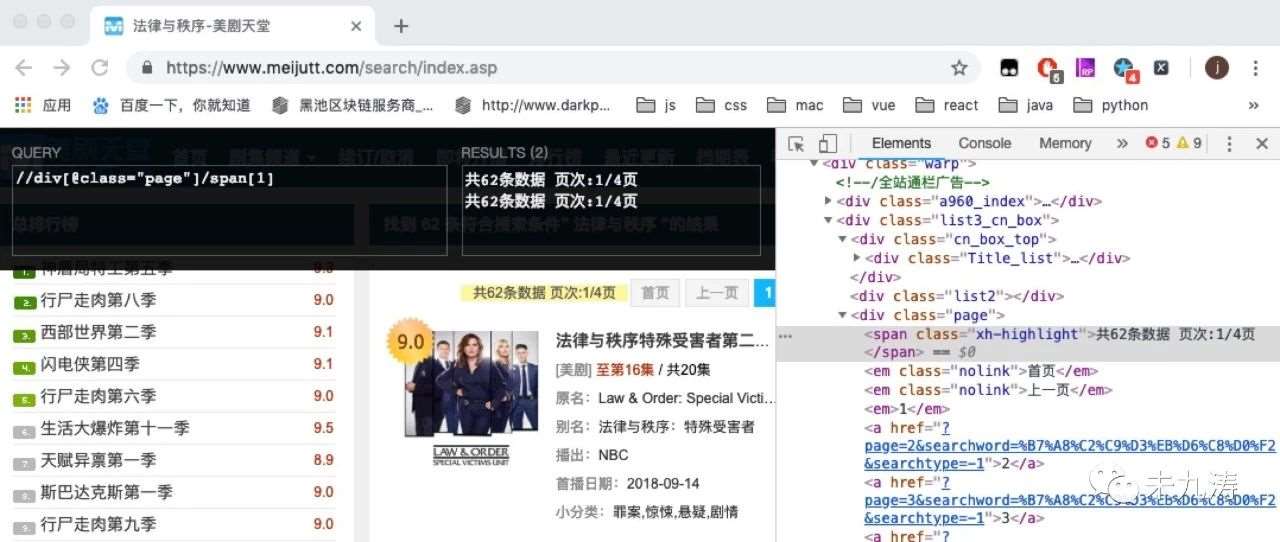
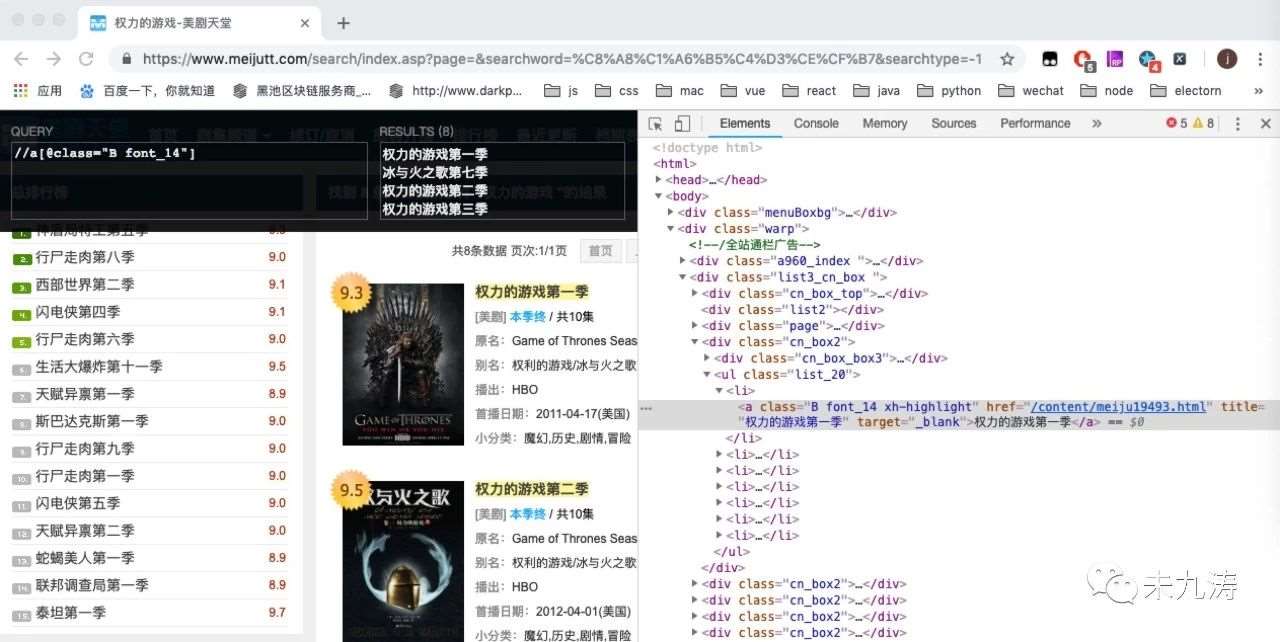
我們通過谷歌的 xpath 插件對頁面內的 dom 進行搜索,發現我們要選取的 class 類名。
我們根據獲取到的頁數,找到所有頁面里我們要搜索的信息:
# 加載點擊搜索頁面點擊的本季頁面
def loadDetailPage(self, pageTotal, text, headers):
# 取出搜索的結果一共多少頁
pageTotal = pageTotal[0].split('/')[1].rstrip("頁")
# 獲取每一季的內容(劇名和鏈接)
node_list = text.xpath('//a[@class="B font_14"]')
items = {}
items['name'] = self.textLineEdit.text()
# 循環獲取每一季的內容
for node in node_list:
# 獲取信息
title = node.xpath('@title')[0]
link = node.xpath('@href')[0]
items["title"] = title
# 通過獲取的單季鏈接跳轉到本季的詳情頁面
requestDetail = urllib.request.Request("https://www.meijutt.com" + link, headers=headers)
htmlDetail = urllib.request.urlopen(requestDetail).read()
textDetail = etree.HTML(htmlDetail)
node_listDetail = textDetail.xpath('//div[@class="tabs-list current-tab"]//strong//a/@href')
self.writeDetailPage(items, node_listDetail)
# 爬取完畢提示
if self.page == int(pageTotal):
self.infoSearchDone()
else:
self.infoSearchContinue(pageTotal)我們根據獲取到的鏈接,再次通過 urllib 庫進行頁面訪問,即我們手動點擊進入其中的一個頁面,比如 權利的游戲第一季,再次通過 xpath 獲取到我們所需要的下載鏈接:
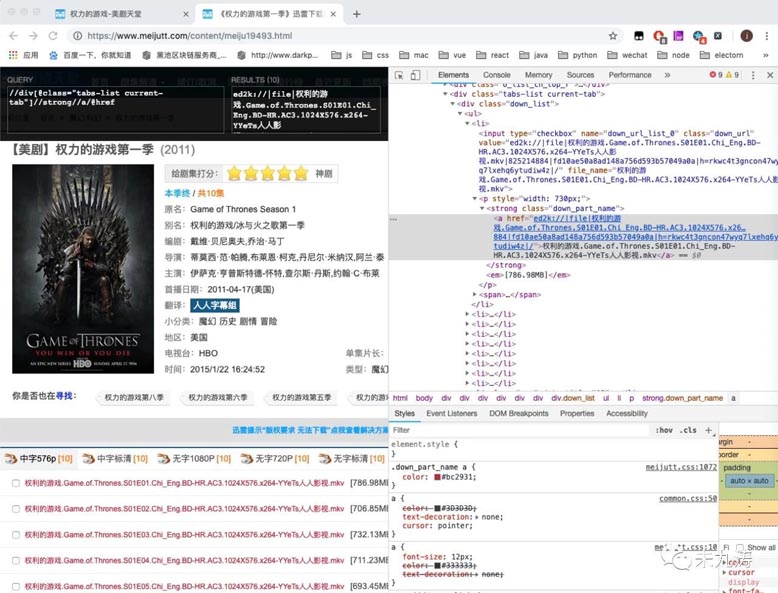
至此我們就將所有我們搜索到的 權力的游戲 的下載鏈接拿到手了,接下來就是寫圖形界面了。
本人選用了 PyQt5 這個框架,它內置了 QT 的操作語法,對于本人這種小白用起來也很友好。至于如何使用本人也都在代碼上添加了注釋,在這兒做一下簡單的說明,就不過多解釋了。
from PyQt5.QtWidgets import QApplication, QWidget, QLineEdit, QTextEdit, QVBoxLayout, QPushButton, QMessageBox, QLabel import sys
將獲取的信息寫入搜索結果內:
# 將數據顯示到圖形界面 def writeDetailPage(self, items, node_listDetail): for index, nodeLink in enumerate(node_listDetail): items["link"] = nodeLink # 寫入圖形界面 self.textEdit.append( "<div>" "<font color='black' size='3'>" + items['name'] + "</font>" + "\n" "<font color='red' size='3'>" + items['title'] + "</font>" + "\n" "<font color='orange' size='3'>第" + str(index + 1) + "集</font>" + "\n" "<font color='green' size='3'>下載鏈接:</font>" + "\n" "<font color='blue' size='3'>" + items['link'] + "</font>" "<p></p>" "</div>" )
因為可能有多頁情況,所以我們得做一次判斷,提示一下剩余多少頁,可以選擇繼續爬取或停止,做到人性化交互。
# 搜索不到結果的提示信息 def infoSearchNull(self): QMessageBox.information( self, '提示', '搜索結果不存在,請重新輸入搜索內容', QMessageBox.Ok, QMessageBox.Ok ) # 爬取數據完畢的提示信息 def infoSearchDone(self): QMessageBox.information( self, '提示', '爬取《' + self.textLineEdit.text() + '》完畢', QMessageBox.Ok, QMessageBox.Ok ) # 多頁情況下是否繼續爬取的提示信息 def infoSearchContinue(self, pageTotal): end = QMessageBox.information( self, '提示', '爬取第' + str(self.page) + '頁《' + self.textLineEdit.text() + '》完畢,還有' + str(int(pageTotal) - self.page) + '頁,是否繼續爬取', QMessageBox.Ok | QMessageBox.No, QMessageBox.No ) if end == QMessageBox.Ok: self.page += 1 self.loadSearchPage(self.textLineEdit.text(), self.page) else: pass
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





